Salut Big Data aficionados,
L'équipe Hue est fière et remercie tous les contributeurs de Hue 3.9! ![]()
L'objectif de cette nouvelle version a été d'améliorer l'expérience utilisateur générale (pas de nouvelle application ont été ajoutés) et la stabilité. Plus de 700 commits depuis 3.8 ont été fait, en particulier sur le Notebook et Spark Job Server! Allez télécharger la nouvelle version et essayer la un coup!
Vous trouverez ci-dessous une description détaillée de ce qui est a été amélioré. Pour la list complète des changements, consultez les notes de version.
Tutoriels
Exploration des données d'utilisateur de vélo de San Francisco avec un tableau de bord dynamique
Construire en temps réel un tableau de bord de Tweets avec Solr et Spark
Les principales améliorations
Spark (beta)
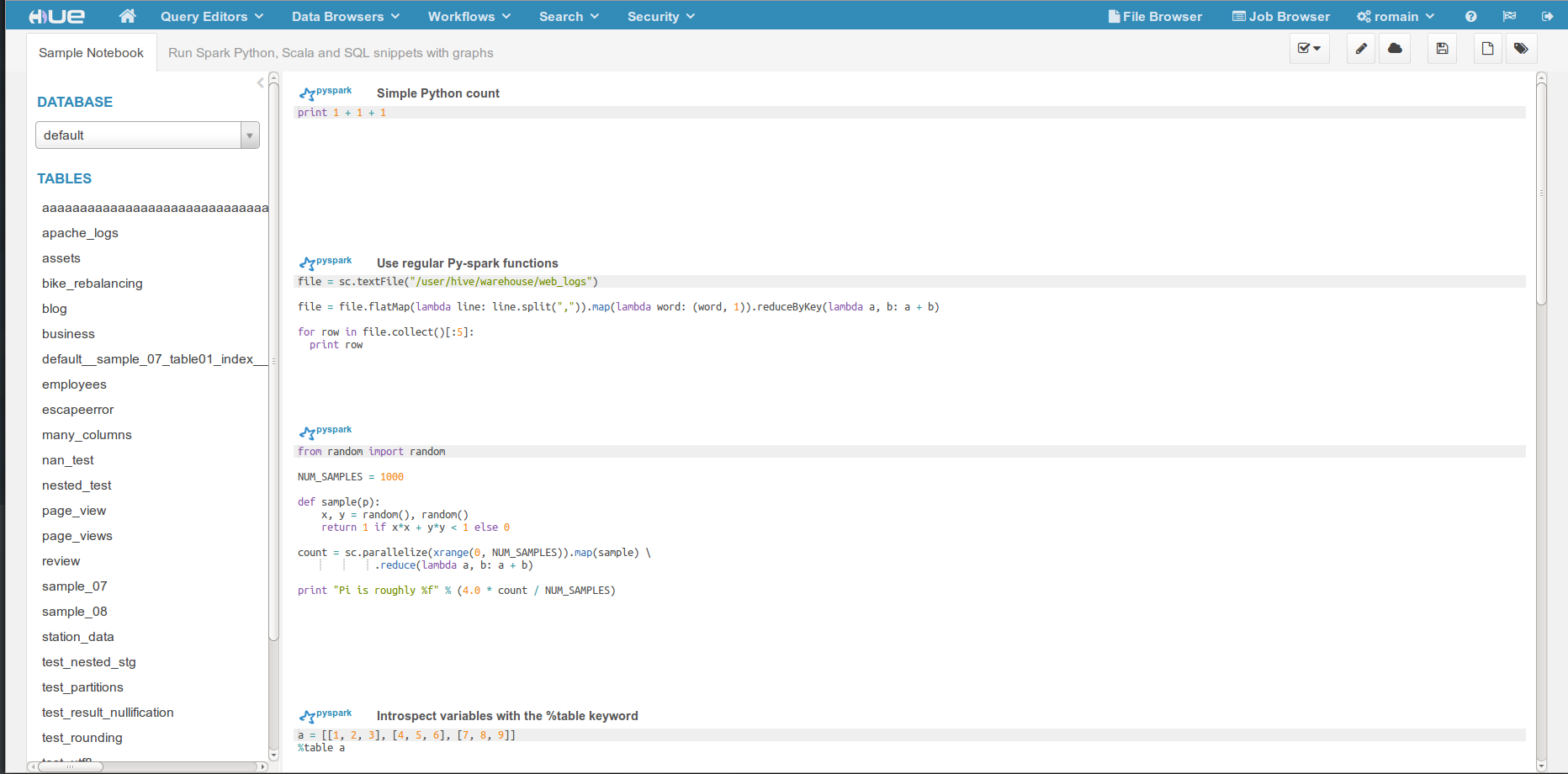
- Refonte de l'interface utilisateur Notebook
- Support de la fermeture de sessions et spécification de ses propriétés
- Support pour Spark 1.3, 1.4, 1.5
- Impersonation de l'utilisateur
- Support du shell R
Pour en en savoir plus, voir les posts sur Spark Notebook et la récente présentation de Livy le Spark REST Job Server.
Recherche
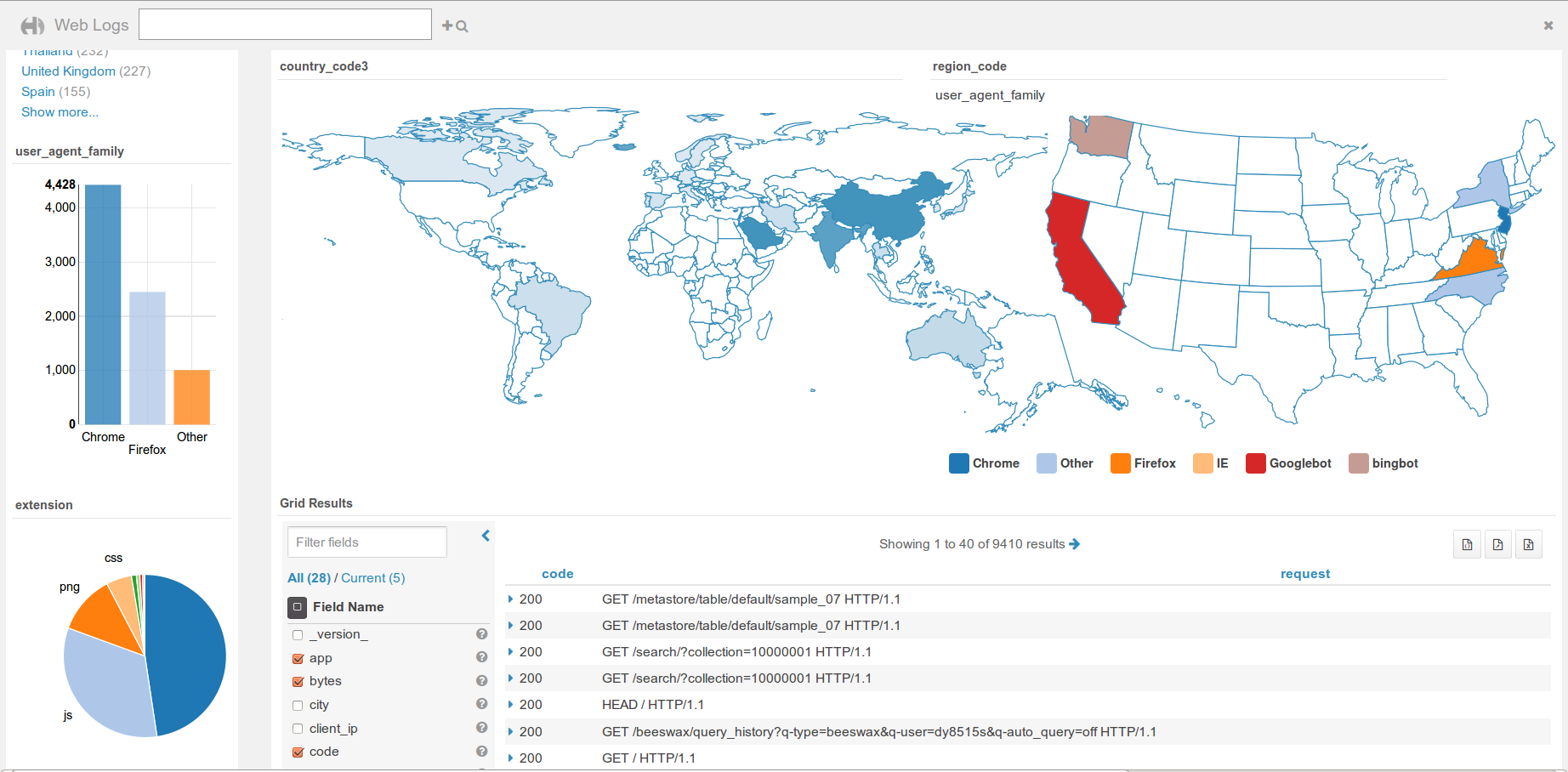
- Filtrage en direct lors du déplacement sur la carte
- Actualisation de seulement les widgets qui ont changé, rafraîchissement toutes les N secondes disponible
- Modification des documents indexés
- Lien vers le document original
- Importation et exportation des tableaux de bord
- Partage des tableaux de bord
- Sauvegarde et rechargement des définitions de la requête de recherche
- Filtrage de la fenêtre de temps en mode fixe ou roulante
- Support des codes de pays à 2 lettres sur la carte
- Mode plein écran
- L'intégration simplifié de Moustache pour améliorer votre style de résultat
Stabilité / performances
- Correction de "deadlocks" / blocages pour les connexions Thrift vers Hive
- Nouvelle série de tests d'intégrations
- Ajouter d'options et metriques sur l'état de santé de Hue sous forme de JSON
- Support de MariaDB pour RHEL7
- Vérification de configuration pour confirmer que le moteur de MySql est bien InnoDB et non MyISAM
- Page d'accueil plus rapide
- Série de correction de bugs pour les bases de données d'Oracles et de ses migrations
Sécurité
- La liste de chiffrement (cipher list) recommandée par Mozilla est définie par défaut
- Le téléchargement de fichiers volumineux avec Kerberos HTTPFS remarche
- L'entête X-Frame-Options est spécifié pour toutes les réponses
- Support de multiples authentifications par ordre de priorité
- Ajout d'une option de configuration globale "ssl_validate" pour valider les certificats SSL de Hue vers les clients commen HDFS ou YARN
- Par défaut, l'utilisation des cookies de session est sécurisée si HTTPS est activé
Oozie
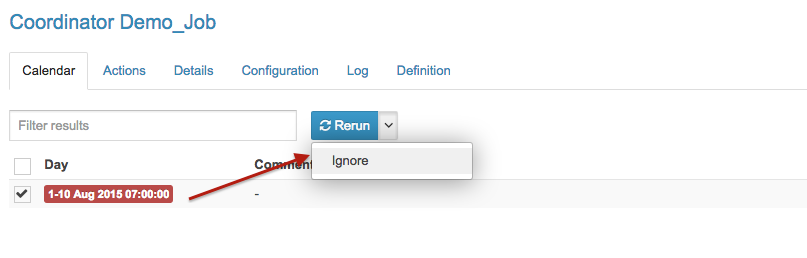
- Les opération des filtres de tableau de bord sont faites par Oozie
- Intégration de l'import / export de flux de travail, des coordinateurs et des Bundles dans l'interface utilisateur
- Pagination des tables d'actions des coordinateurs
- Mise à jour de temps d'un coordinateur directement depuis l'interface
- Série d'améliorations à l'éditeur
SQL
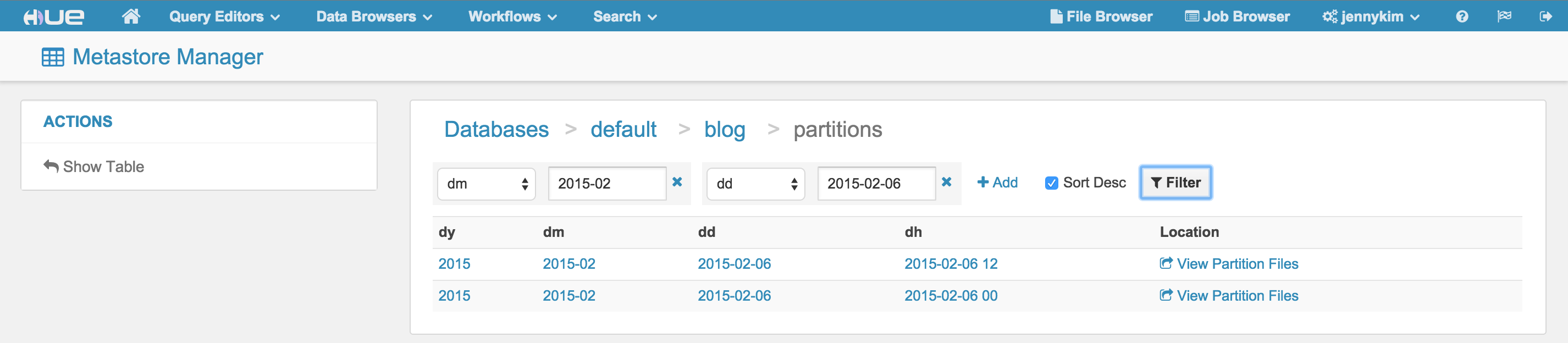
- Le tableau des statistiques et termes les plus utilisés est disponibles directement depuis l'assistant
- Sélection par défaut d'une base de données disponible la premiere fois
- Offre de filtrage des partitions sur la liste de la page des partitions
- Les liens et noms de partitions sont maintenant toujours corrects
- Les examples de donnée avec les tables partitionnées sont disponibles meme en mode "strict" de Hive
HBase
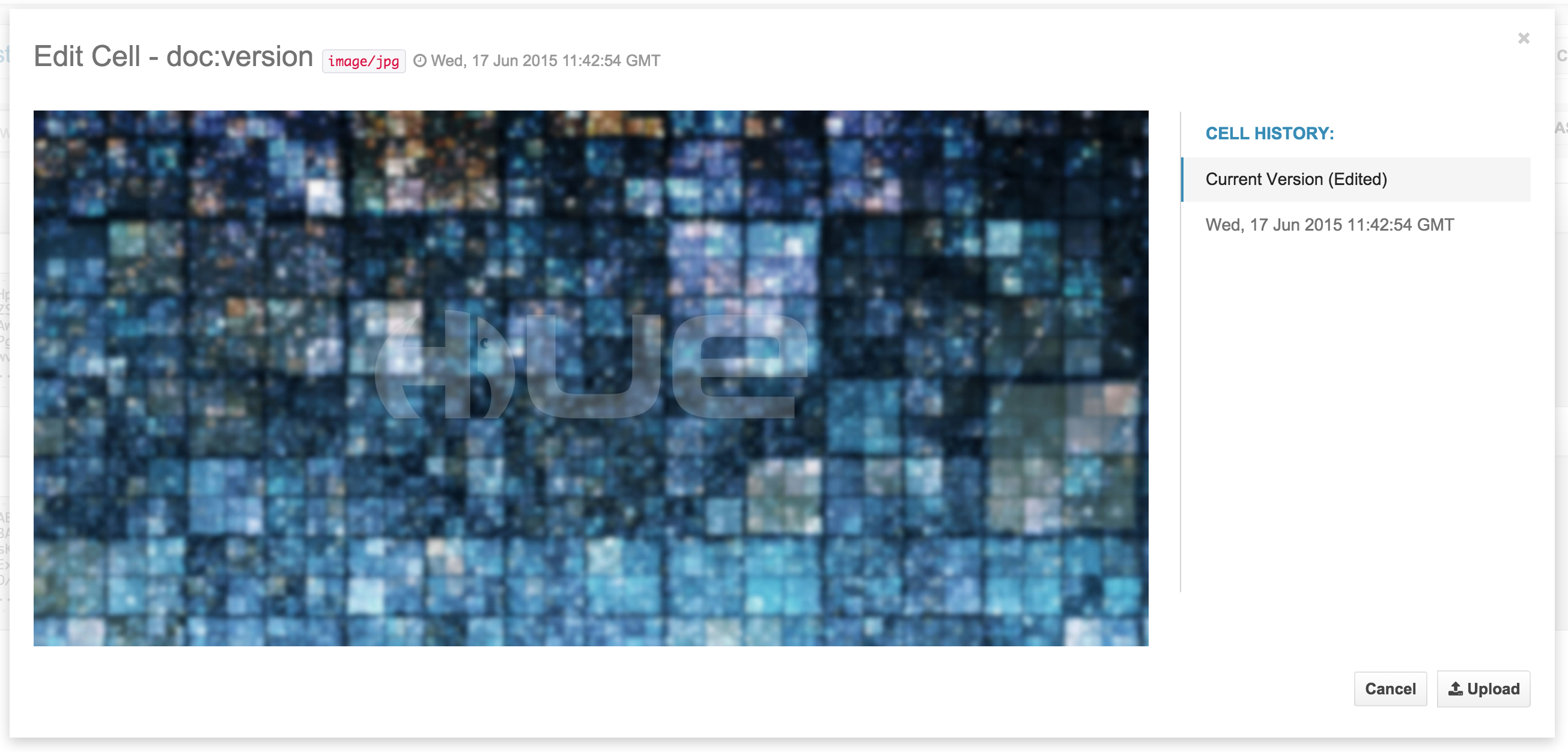
- Téléchargement de donnée binaire dans les cellules
- Une cellule peut être vidée
Senbry

- Meilleur support des URI de Sentry
- Support des privilèges COLONNE pour les autorisations plus fine sur les tables
- Support en cas de crash de Sentry (HA)
- Facilitation de la navigation entre les sections
- Support de la nouvelle propriété sentry.hdfs.integration.path.prefixes HDFS-site.xml
Indexeur pour Solr Search
- Téléchargement direct des configurations sans nécessiter d'avoir la commande "solrctl" installée
ZooKeeper
- Création d'un module pour faciliter la modification des informations de ZooKeeper
Pig

- Support des paramètres %default dans la présentation contextuelle de soumission de script
- Ne montre plus les %parameters dans la présentation contextuelle de soumission de script
- Génération automatique des crédentiels HCat
Sqoop 2
- Support de l'authentification Kerberos
Conférences
Ce fut un plaisir de présenter au Big Data Budapest Meetup, Big Data Amsterdam, Hadoop Summit de San Jose et Big Data LA.
Nouvelles distributions
Équipe
Hummus et le yogourt étaient au menu en Israël!
Pour la suite!
La prochaine version (3.10) se concentrera sur la version 1 du Notebook pour Spark et en ajoutant une indexation plus simple pour l'application Search de Solr.
La conception Hue 4 va également commencer avec l'objectif de devenir l'équivalent de “Excel pour Big Data”. Un nouveau look, une unification de toutes les applications, des assistants pour l'ingestion des données … vous permettra d'utiliser la plate-forme complète (Ingest, Spark, SQL, Recherche) dans une interface utilisateur unique!
En avant / Onwards!
Comme d'habitude merci à tous les contributeurs du projet et pour l'envoi de commentaires et de participer à la liste utilisateur et @gethue!