The Notebook application as well as the REST Spark Job Server are being revamped. These two components goals are to let users execute Spark in their browser or from anywhere. They are still in beta but next version of Hue will have them graduate. Here are a list of the improvements and a video demo:
- Revamp of the snippets of the Notebook UI
- Support for Spark 1.3, 1.4, 1.5
- Impersonation with YARN
- Support for R shell
- Support for submitting jars or python apps
How to play with it?
See in this post how to use the Notebook UI and on this page on how to use the REST Spark Job Server named Livy. The architecture of Livy was recently detailed in a presentation at Big Data Scala by the Bay. Next updates will be at the Spark meetup before Strata NYC and Spark Summit in Amsterdam.
Slicker snippets interface
The snippets now have a new code editor, autocomplete and syntax highlighting. Shortcut links to HDFS paths and Hive tables have been added.
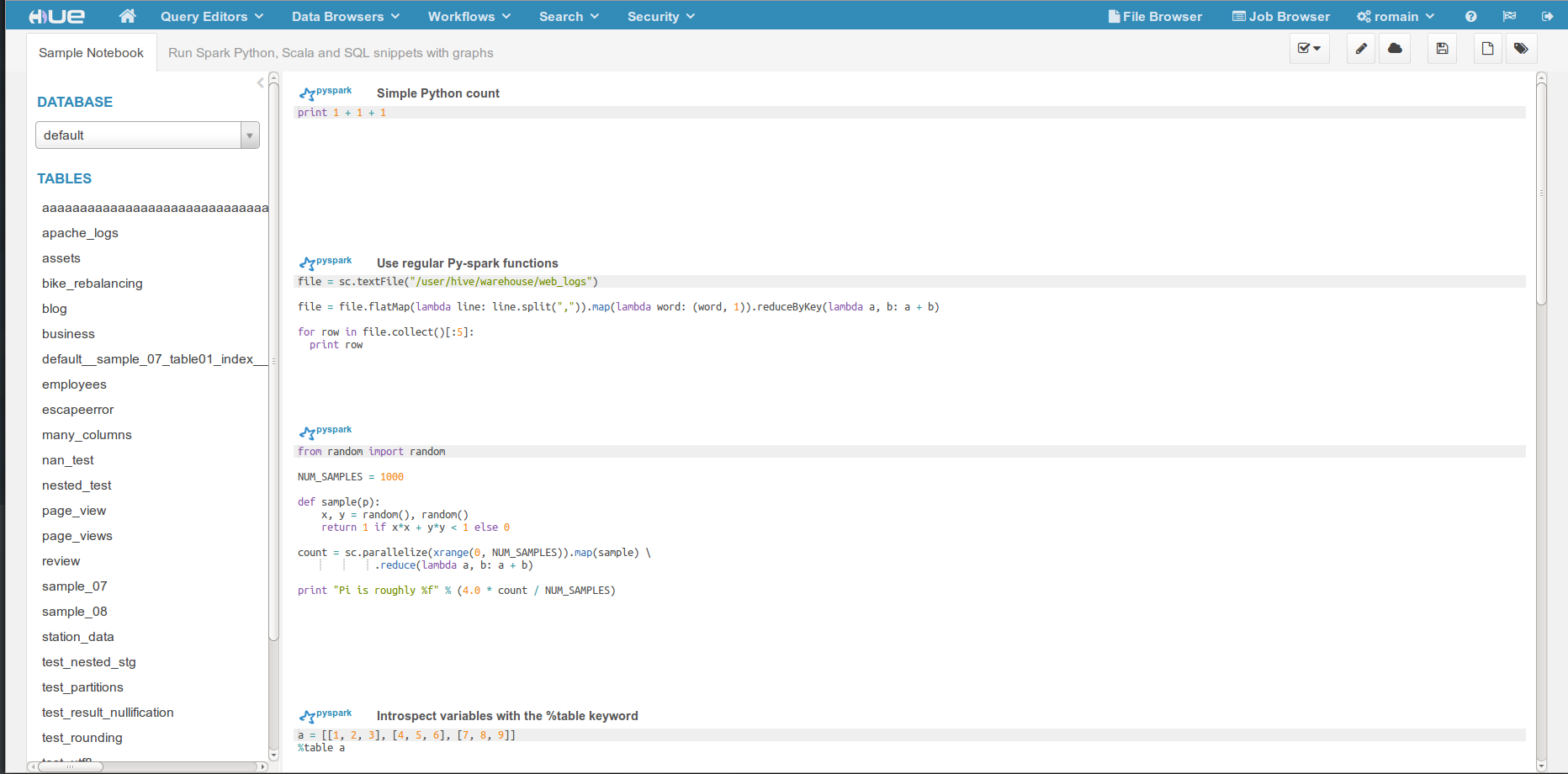
R support
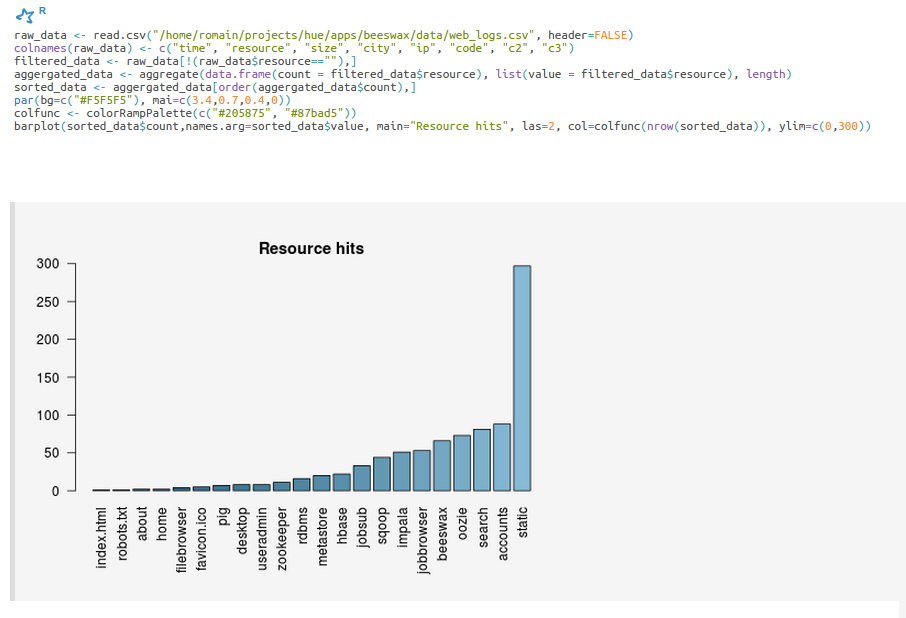
The SparkR shell is now available, and plots can be displayed inline
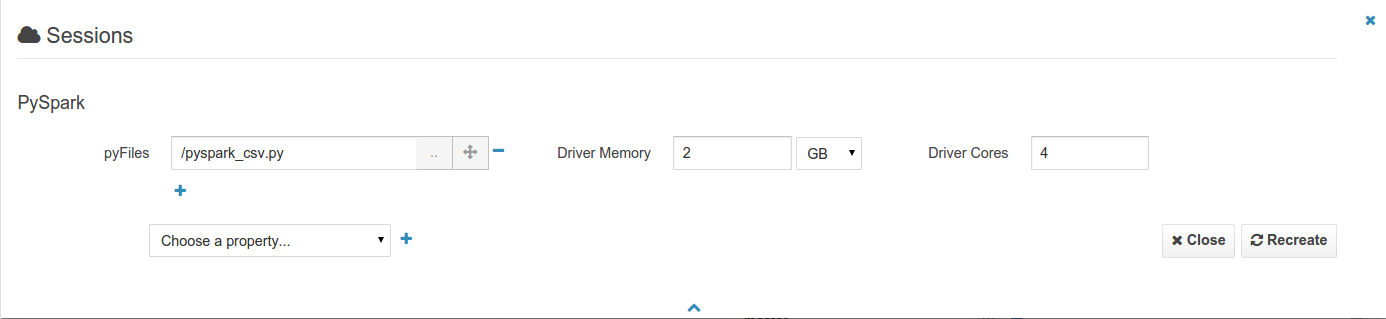
Support for closing session and specifying Spark properties
All the spark-submit, spark-shell, pyspark, sparkR properties of jobs & shells can be added to the sessions of a Notebook. This will for example let you add files, modules and tweak the memory and number of executors.
So give this new Spark integration a try and feel free to send feedback on the hue-user list or @gethue!