Hi Big Data Aficionados,
The Hue Team is glad to thanks all the contributors and release Hue 3.9! ![]()
The focus of this release was to improve the experience everywhere (no new app were added) and the stability. More than 700 commits on top of 3.8 are in and some apps like the Notebook Editor and Spark Job Server got a serious lift! Go grab the tarball release and give it a spin!
You can find below a detailed description of what happened. For all the changes, check out the release notes or the documentation.
Tutorials
Explore San Francisco Bike share data with a dynamic visual dashboard
Build a real time Tweet dashboard with Search and Spark
Main improvements
Spark (beta)
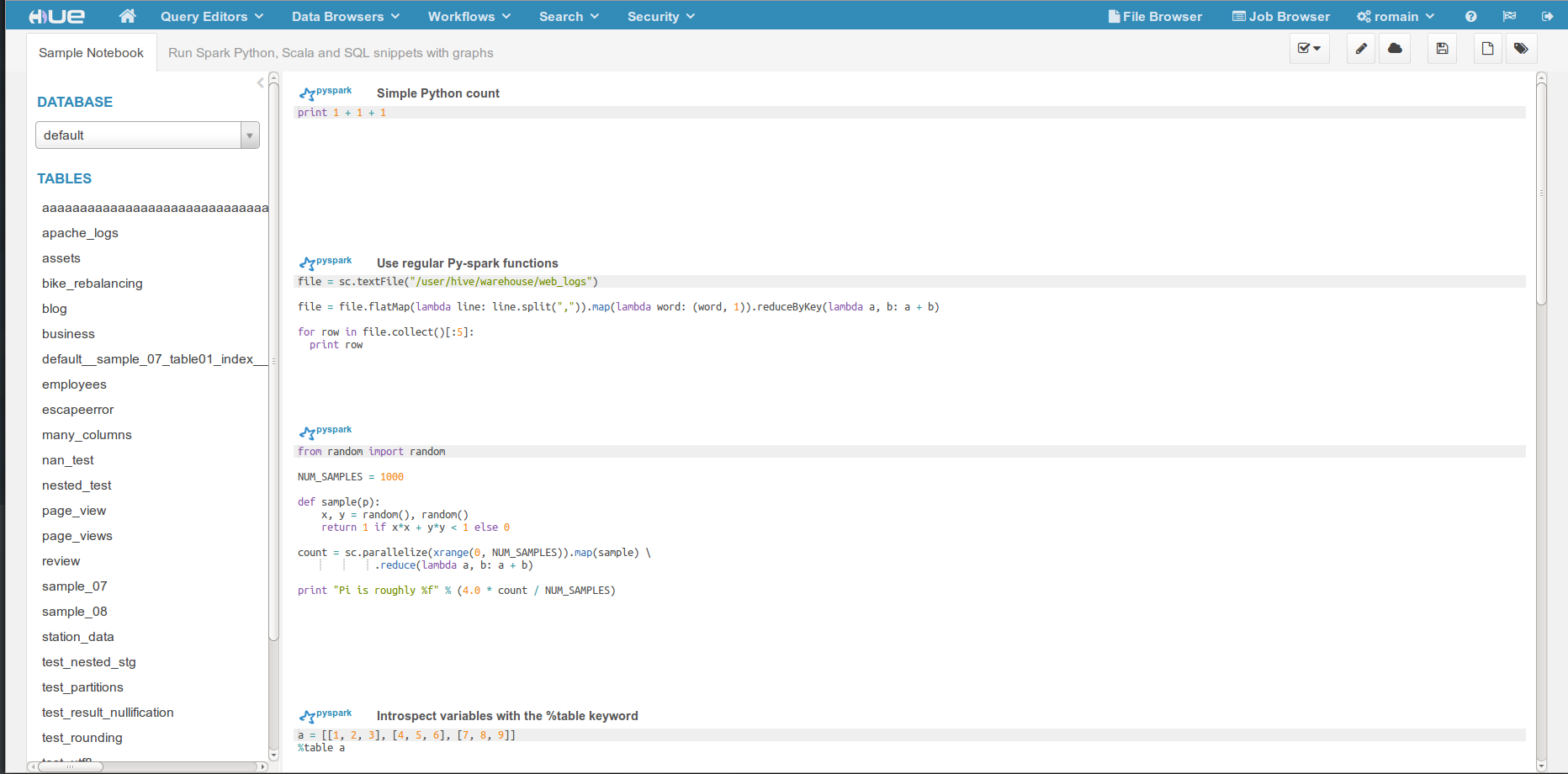
- Revamp of Notebook UI
- Support for closing session and specifying Spark properties
- Support for Spark 1.3, 1.4, 1.5
- Impersonation with YARN
- Support for R shell
- Support for submitting jars or python apps
Learn more about the Notebook and the REST Spark Job Server Livy.
Search
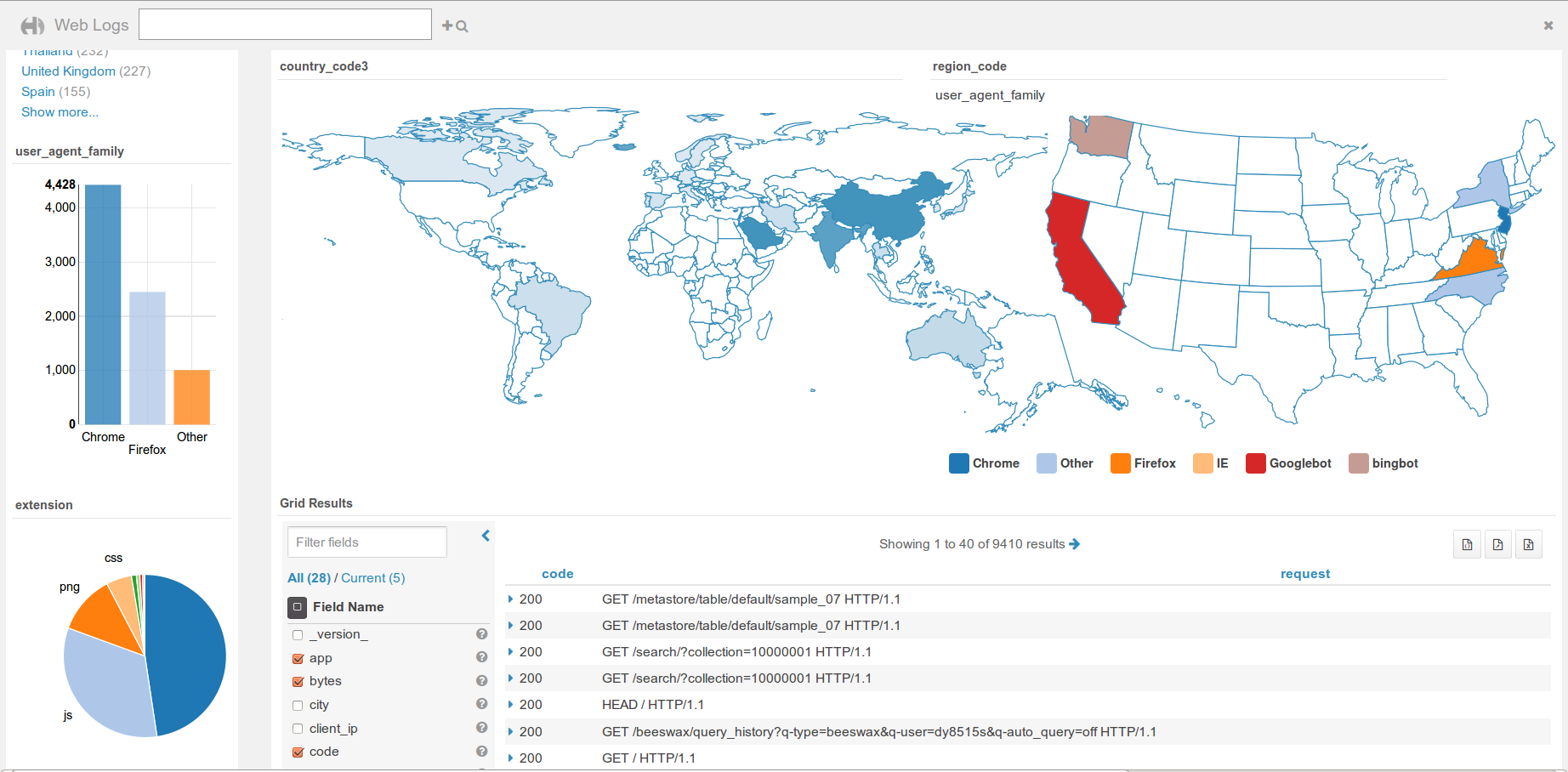
- Live filtering when moving on the map
- Refresh only widgets that changed, refresh every N seconds
- Edit document
- Link to original document
- Export/import saved dashboards
- Share dashboards
- Save and reload the full query search definition
- Fixed or rolling time window filtering
- Marker clustering on Leaflet Map widget
- Support 2-letter country code in gradient map widget
- Full mode Player display
- Simpler Mustache integration to enhance your result style
- Big IDs support
- Preview of nested analytics facets
Stability/performance
- Fix deadlock fetching Thrift clients and waiting for Thrift connections
- New set of integrations tests
- Add optional /desktop/debug/check_config JSON response
- MariaDB support
- Configuration check to confirm that MySql engine is InnoDB
- Faster Home page
- Series of Oracles and DB migration fixes
Security
- Explicitly set cipher list to Mozilla recommendation
- Fix uploading large files to a kerberized HTTPFS
- Set X-Frame-Options to all responses
- Support multiple authentication backends in order of priority
- Add global ssl_validate config option
- Default to using secure session cookies if HTTPS is enabled
Oozie
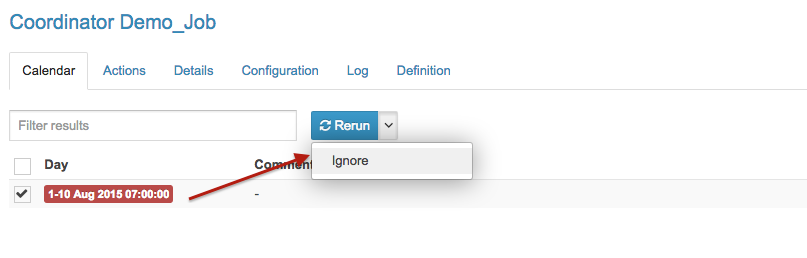
- Filter dashboard jobs in the backend
- Integrate the import/export of Workflows, Coordinators and Bundles into the UI
- Paginate Coordinator dashboard tables
- Paginate Coordinator actions
- Update end time of running coordinator
- Series of improvements to the Editor
SQL
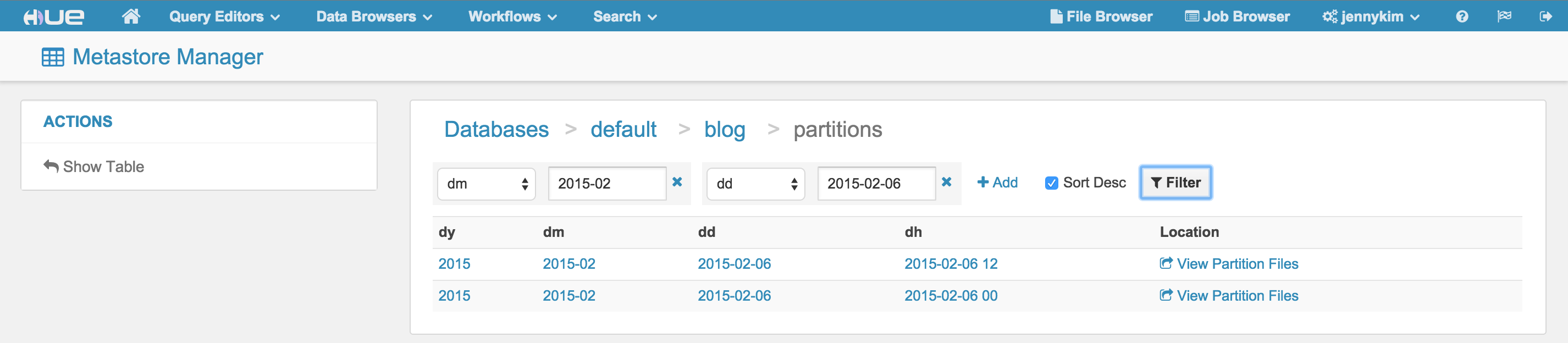
- Table / column statistics and Top terms available in assist
- Select default as first assist database if available
- Offer to filter partition on the list of partitions page
- Partitions names and links are now always correct
- Allow sample on partitioned tables in strict mode
HBase
- Upload binary into cells
- Allow to empty a cell
Sentry

- Better support of URI scope privilege
- Support COLUMN scope privilege for finer grain permissions on tables
- Support HA
- Easier navigation between sections
- Support new sentry.hdfs.integration.path.prefixes hdfs-site.xml property
Indexer
- Directly upload configurations without requiring the solrctl command
ZooKeeper
- Creation of a lib for easily pulling or editing ZooKeeper information
Pig

- Support %default parameters in the submission popup
- Do not show %declare parameters in the submission popup
- Automatically generate hcat auth credentials
Sqoop
- Support Kerberos authentication
Conferences
It was a pleasure to present at Big Data Budapest Meetup, Big Data Amsterdam, Hadoop Summit San Jose and Big Data LA.
New distributions
- Docker image of HUE filebrowser for IBM Analytics for Apache Service
- Big Data IBM insights
- Pivotal HD3.0
- HDP update
Team Retreat
Hummus and yogurt were at the menu in Israel!
Next!
Next release (3.10) will focus on making the v1 of the Spark Notebook and adding simpler Solr indexing on top of the general improvements.
Hue 4 design is also getting kicked in with the goal of becoming the equivalent of “Excel for Big Data”. A fresh new look, a unification of all the apps, wizards for ingesting data… will let you use the full platform (Ingest, Spark, SQL, Search) in a single UI for fast Big Data querying and prototyping!
Onwards!
As usual thank you to all the project contributors and for sending feedback and participating on the hue-user list or @gethue!