Note: this guide works with any Hue 4 version and HDP 2.x. There is a recent guide on HDP3.
Note: for Hive issues, just scroll down below
Installing Hue 3.9 on HDP 2.3 - Amazon EC2 RHEL 7
Install in HDP 2.2
Initial draft rom Andrew Mo ([email protected])
Insight Data Science - Data Engineering Fellow
Last month I started a guest post on <gethue.com> demonstrating the steps required to use HUE 3.7+ with the Hortonworks Data Platform (HDP); I’ve used HUE successfully with HDP 2.1 and 2.2, and have created a step-by-step guide on using HUE 3.7.1 with HDP 2.2 below.
I’m participating the Insight Data Science Data Engineering Fellows program and built a real-time data engineering pipeline proof of concept using Apache Kafka, Storm, and Hadoop using a “Lambda Architecture.” Cloudera CDH and Cloudera Manager are great tools, but I wanted to use Apache Ambari to deploy and manage Kafka and Storm with Hadoop; for these reasons, HDP 2.2 was selected for the project (note from @gethue: in CDH, Kafka is available and Spark Streaming is preferred to Storm, and CM installs/configures all Hue automatically).
HUE is one of Hadoop’s most important projects, as it significantly increases a user’s ease of access to the power of the Hadoop platform. While Hive and YARN provide a processing backbone for data analysts familiar with SQL to use Hadoop, HUE provides my interface of choice for data analysts to quickly get connected with big data and Hadoop’s powerful tools.
With HDP, HUE’s features and ease of use are something I always miss, so I decided to add HUE 3.7.1 to my HDP clusters.
Features confirmed to work in partial or complete fashion:
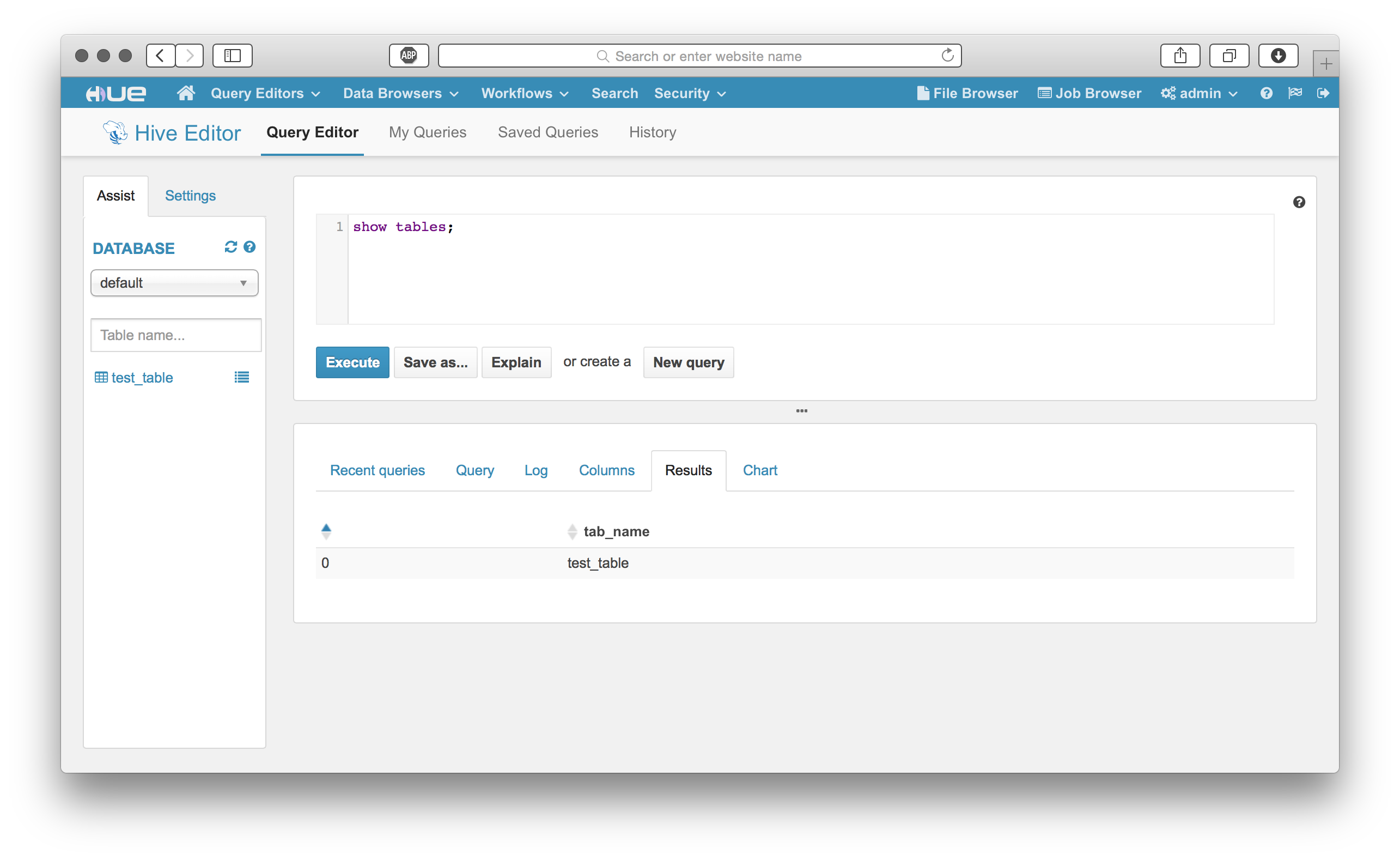
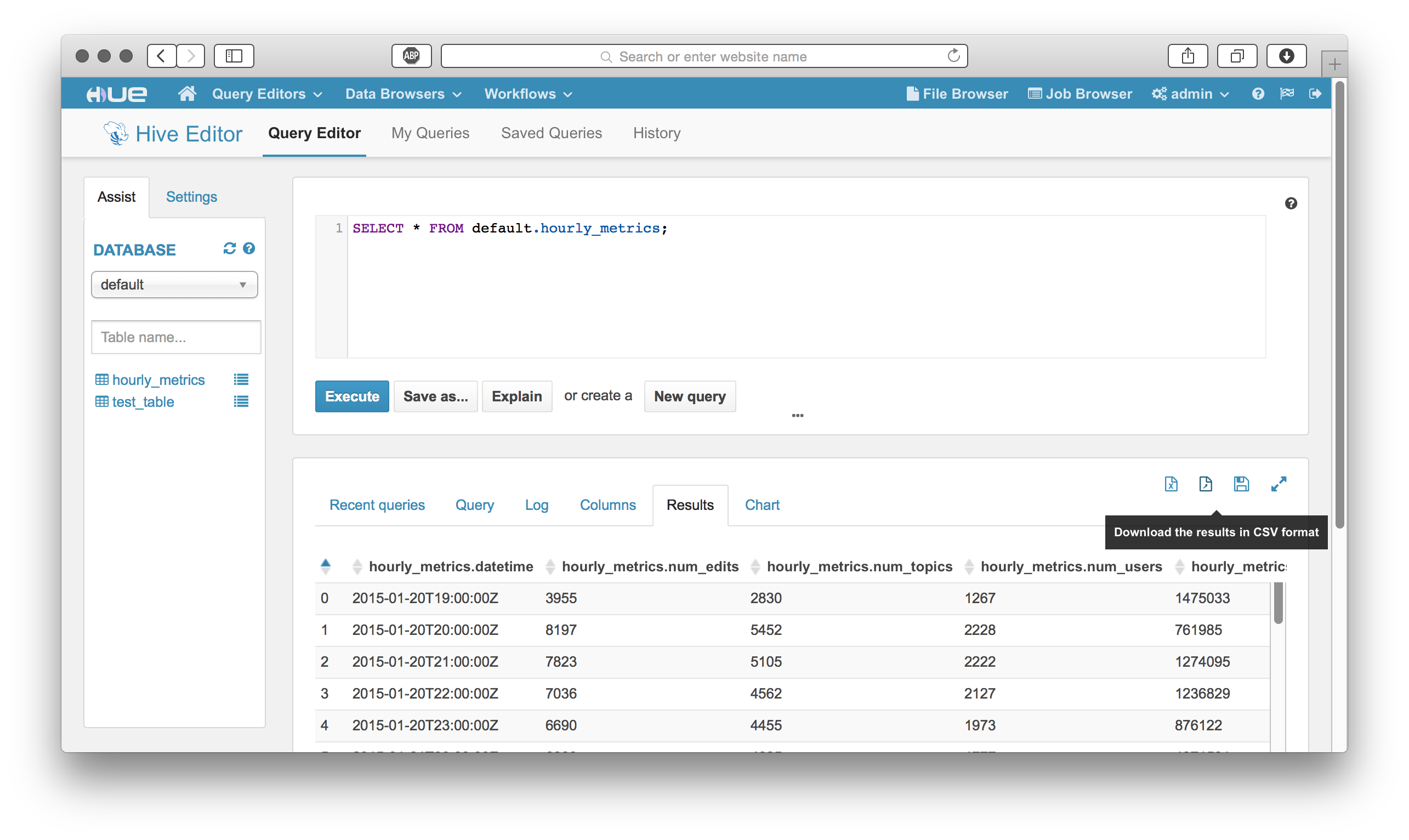
• Hive/Beeswax
• File Browser
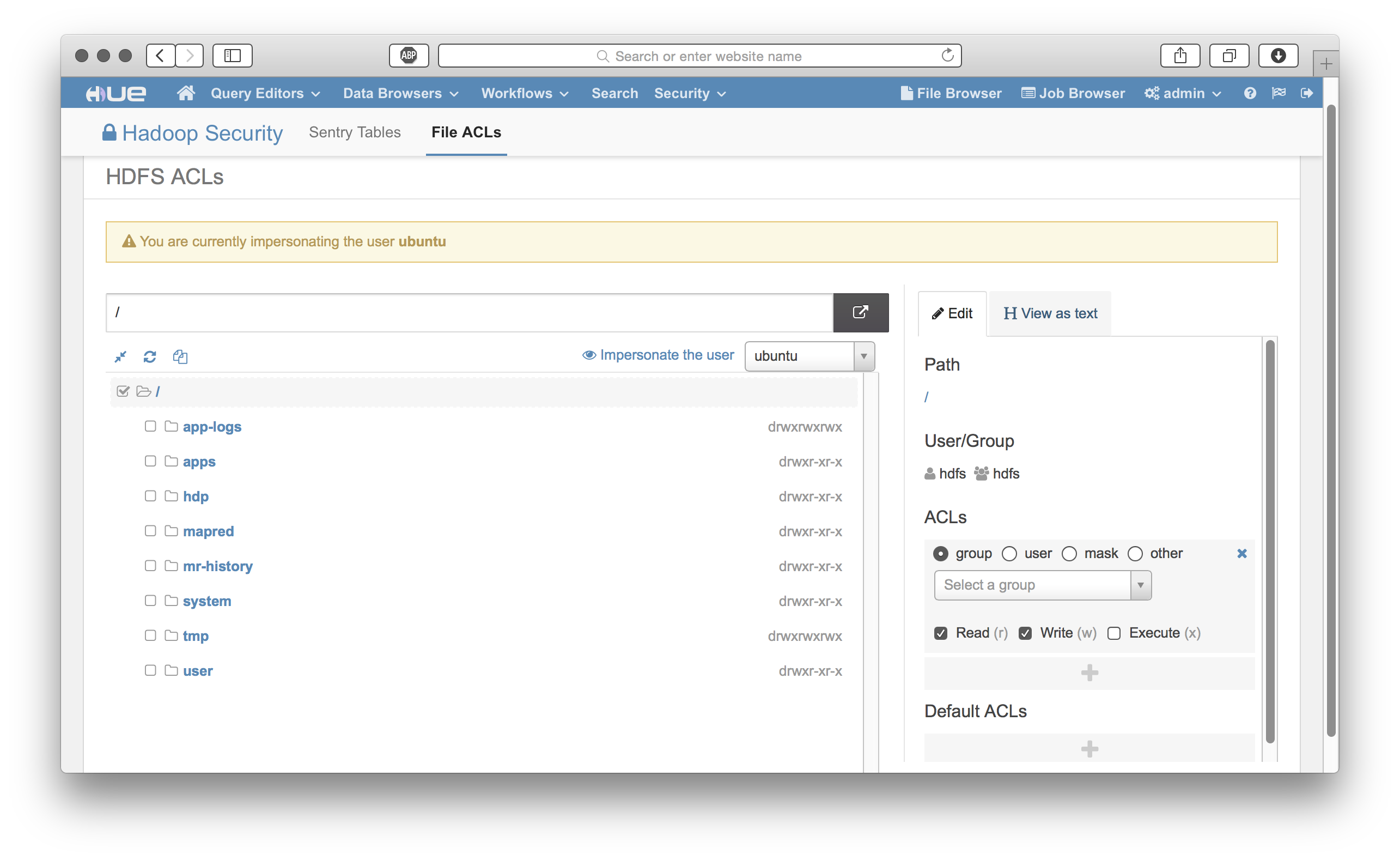
• HDFS FACL Manager
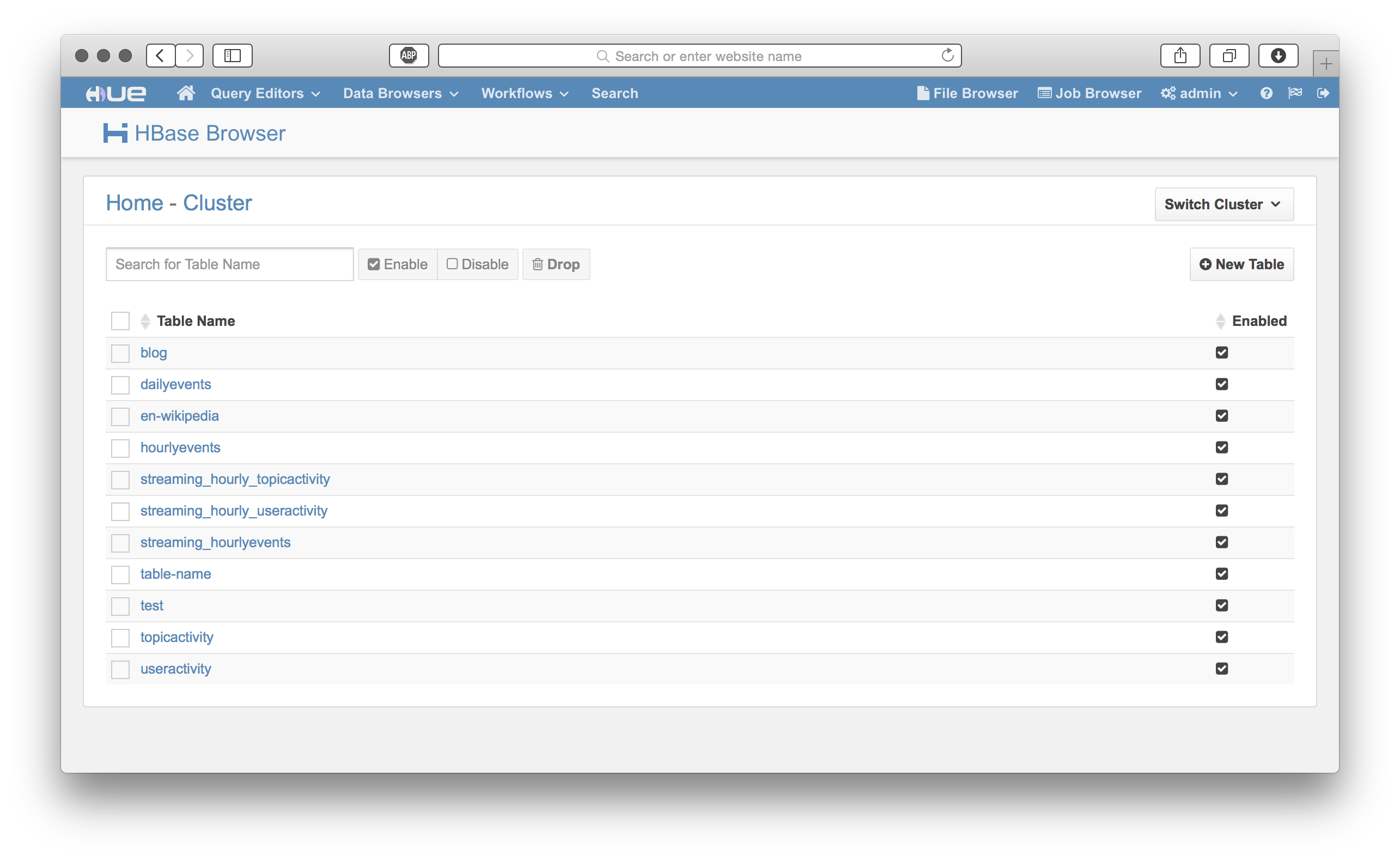
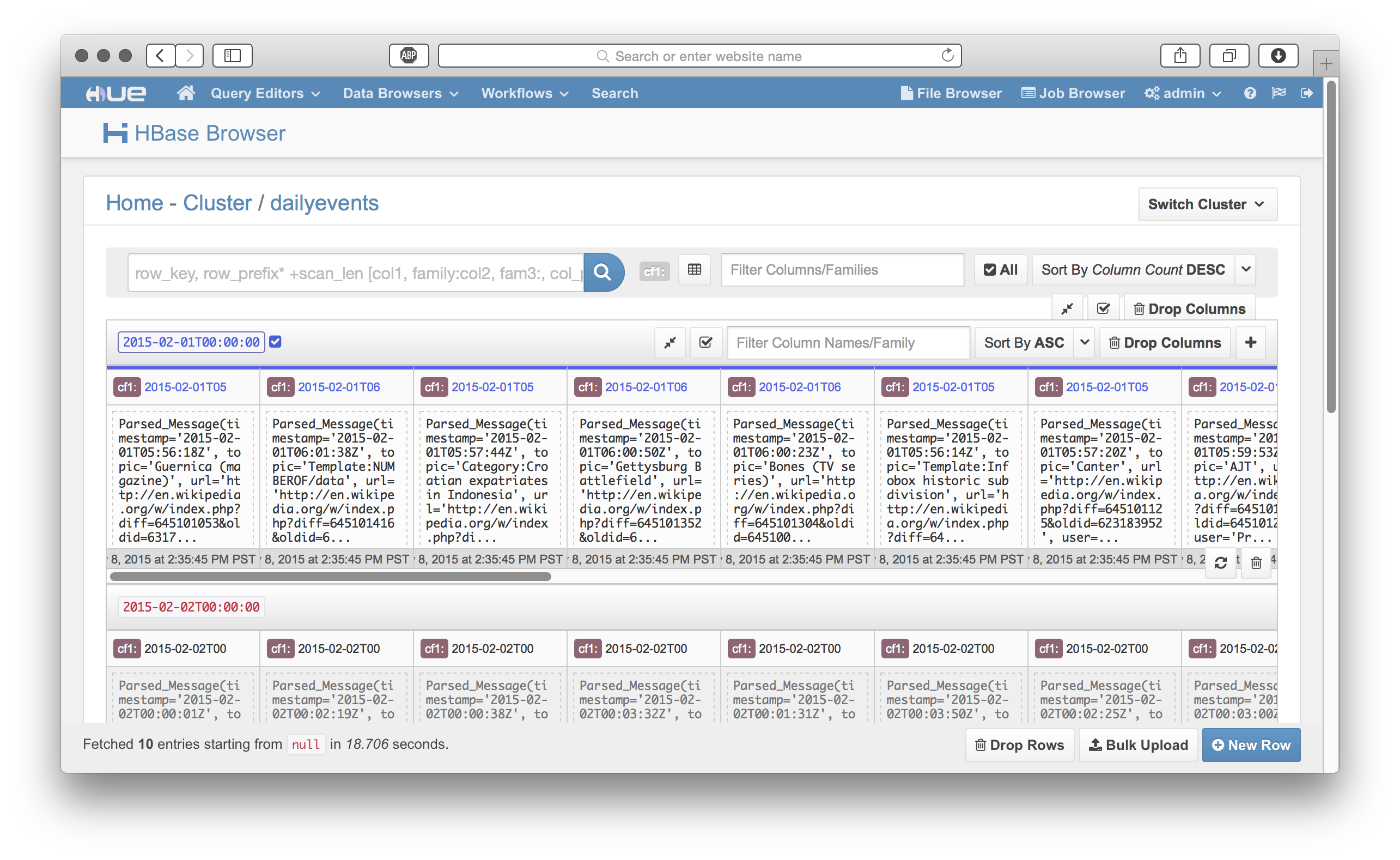
• HBase Cluster Browser
• Job Browser
Still working on debugging/integrating Pig/Oozie!
Spark is on my to do list as well.
Technical Details:
• Distribution: Hortonworks Data Platform (HDP) 2.2
• Cluster Manager: Apache Ambari 1.7
• Environment: Amazon EC2
• Operating System: Ubuntu 12.04 LTS (RHEL6/CentOS6 works fine as well)
HUE will be deployed as a “Gateway” access node to our Hadoop cluster; this means that none of the core Hadoop services or clients are required on the HUE host.
Note about Hive and HDP 2.5+: Since at least HDP 2.5, the default Hive shipped won't work with Hue unless you change the property:
hive.server2.parallel.ops.in.session=trueNote about Tez:
[beeswax]
\# Hue will use at most this many HiveServer2 sessions per user at a time.
\# For Tez, increase the number to more if you need more than one query at the time, e.g. 2 or 3 (Tez as a maximum of 1 query by session).
max_number_of_sessions=1
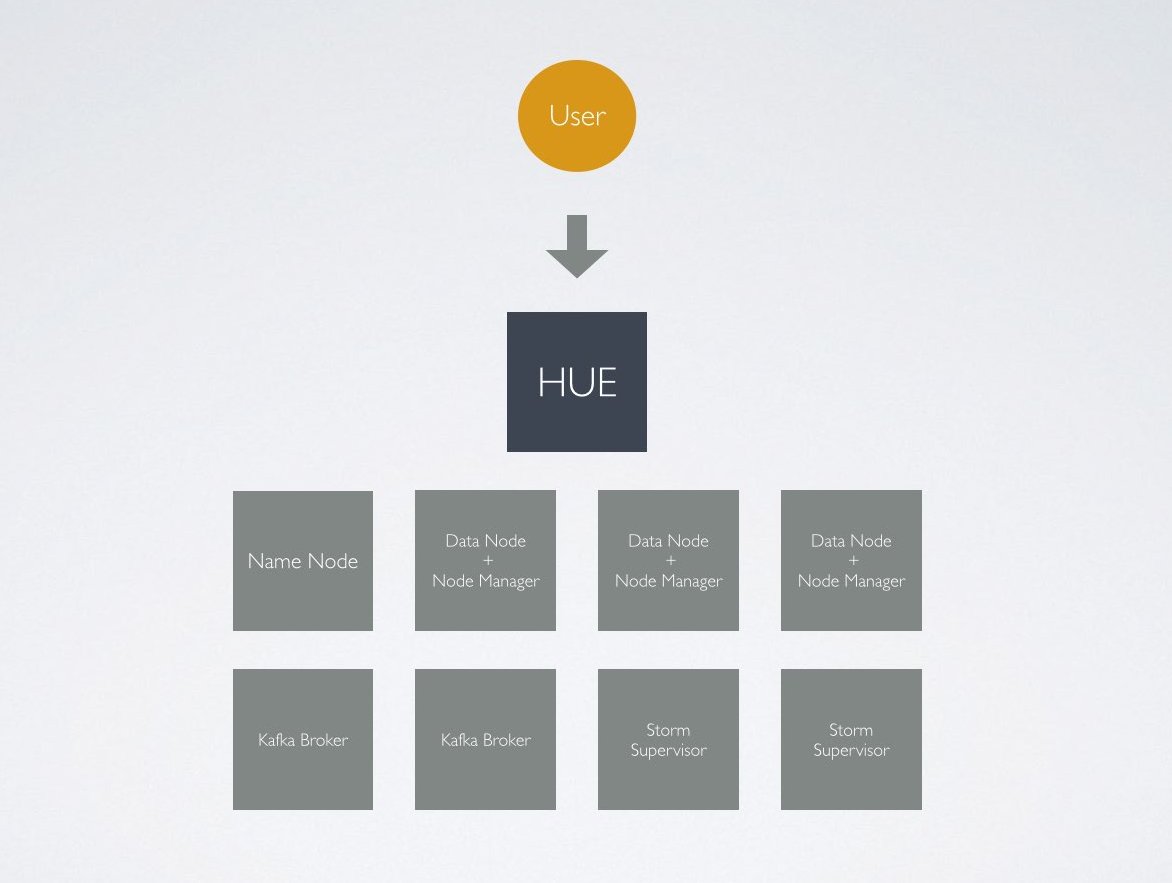
Installing HUE

For this walk-through, we’ll assume that you’ve already deployed a working cluster using Apache Ambari 1.7.
Let’s go on the HUE Host (Gateway node) and get started by preparing our environment and downloading the Hue 3.8 release tarball.
RHEL/CentOS uses ‘yum’ for package management.
Ubuntu uses ‘apt-get’ for package management. In our example, we’re using Ubuntu.
Prepare dependencies:
sudo apt-get install -y ant
sudo apt-get install -y gcc g++
sudo apt-get install -y libkrb5-dev libmysqlclient-dev
sudo apt-get install -y libssl-dev libsasl2-dev libsasl2-modules-gssapi-mit
sudo apt-get install -y libsqlite3-dev
sudo apt-get install -y libtidy-0.99-0 libxml2-dev libxslt-dev
sudo apt-get install -y maven
sudo apt-get install -y libldap2-dev
sudo apt-get install -y python-dev python-simplejson python-setuptools
Download Hue 3.8.1 release tarball (in case, older version 3.7.1 link):
• wget https://cdn.gethue.com/downloads/releases/3.8.1/hue-3.8.1.tgz
Make sure you have Java installed and configured correctly!
I’m using Open JDK 1.7 in this example:
sudo apt-get install -y openjdk-7-jre openjdk-7-jdk
sudo echo “JAVA_HOME=\”/usr/lib/jvm/java-7-openjdk-amd64/jre\”" >> /etc/environment
Unpackage the HUE 3.7.1 release tarball and change to the directory.
Install HUE:
sudo make installBy default, HUE installs to ‘/usr/local/hue’ in your Gateway node’s local filesystem.
As installed, the HUE installation folders and file ownership will be set to the ‘root’ user.
Let’s fix that so HUE can run correctly without root user permissions:
sudo chown -R ubuntu:ubuntu /usr/local/hueConfiguring Hadoop and HUE
HUE uses a configuration file to understand information about your Hadoop cluster and where to connect to. We’ll need to configure our Hadoop cluster to accept connections from HUE, and add our cluster information to the HUE configuration file.
Hadoop Configuration
Ambari provides a convenient single point of management for a Hadoop cluster and related services. We’ll need to reconfigure our HDFS, Hive (WebHcatalog), and Oozie services to take advantage of HUE’s features.
HDFS
We need to do three things, (1) ensure WebHDFS is enabled, (2) add ‘proxy’ user hosts and groups for HUE, and (3) enable HDFS file access control lists (FACLs) (optional).
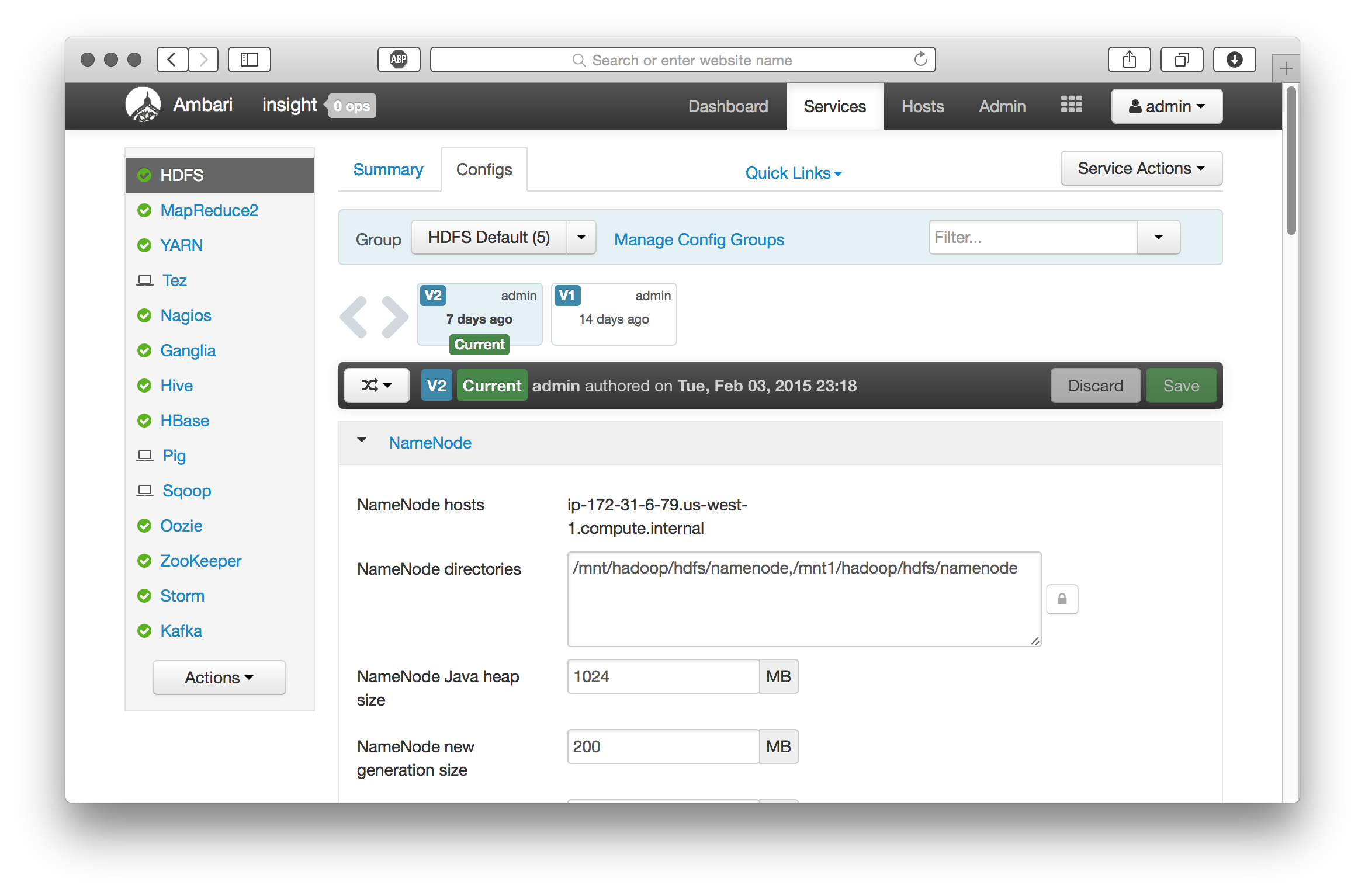
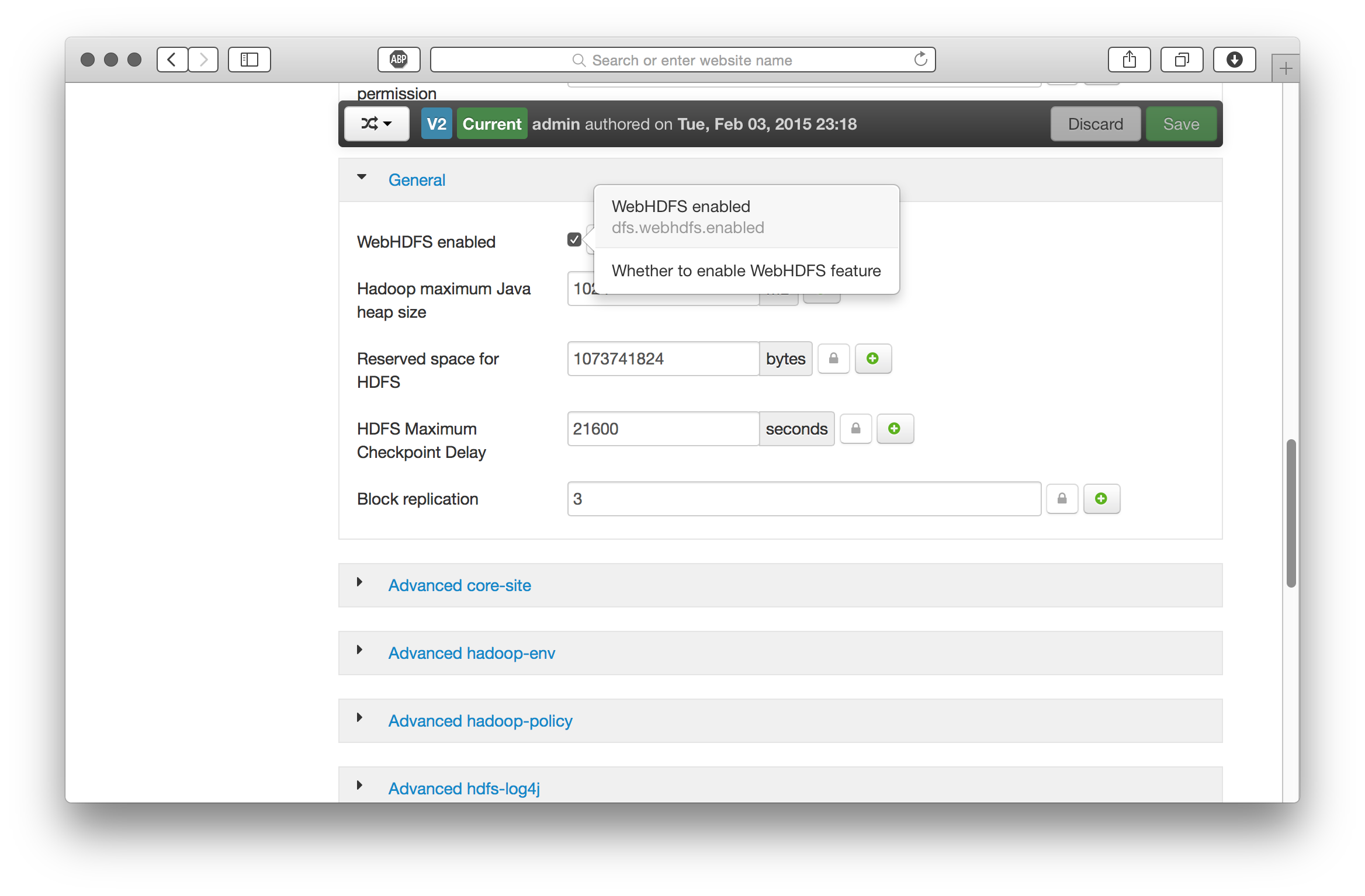
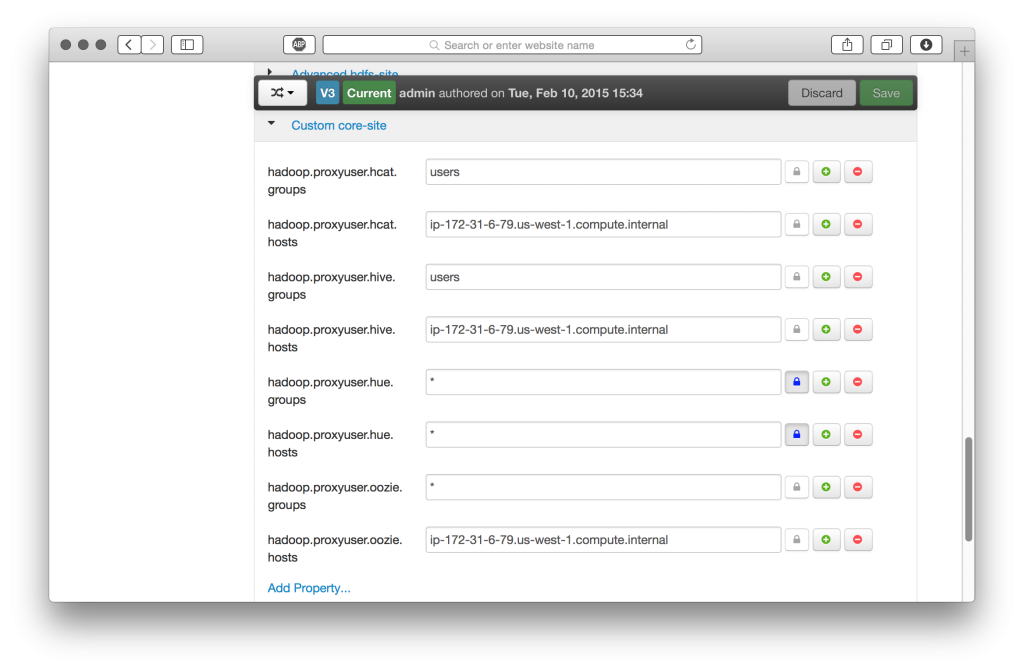
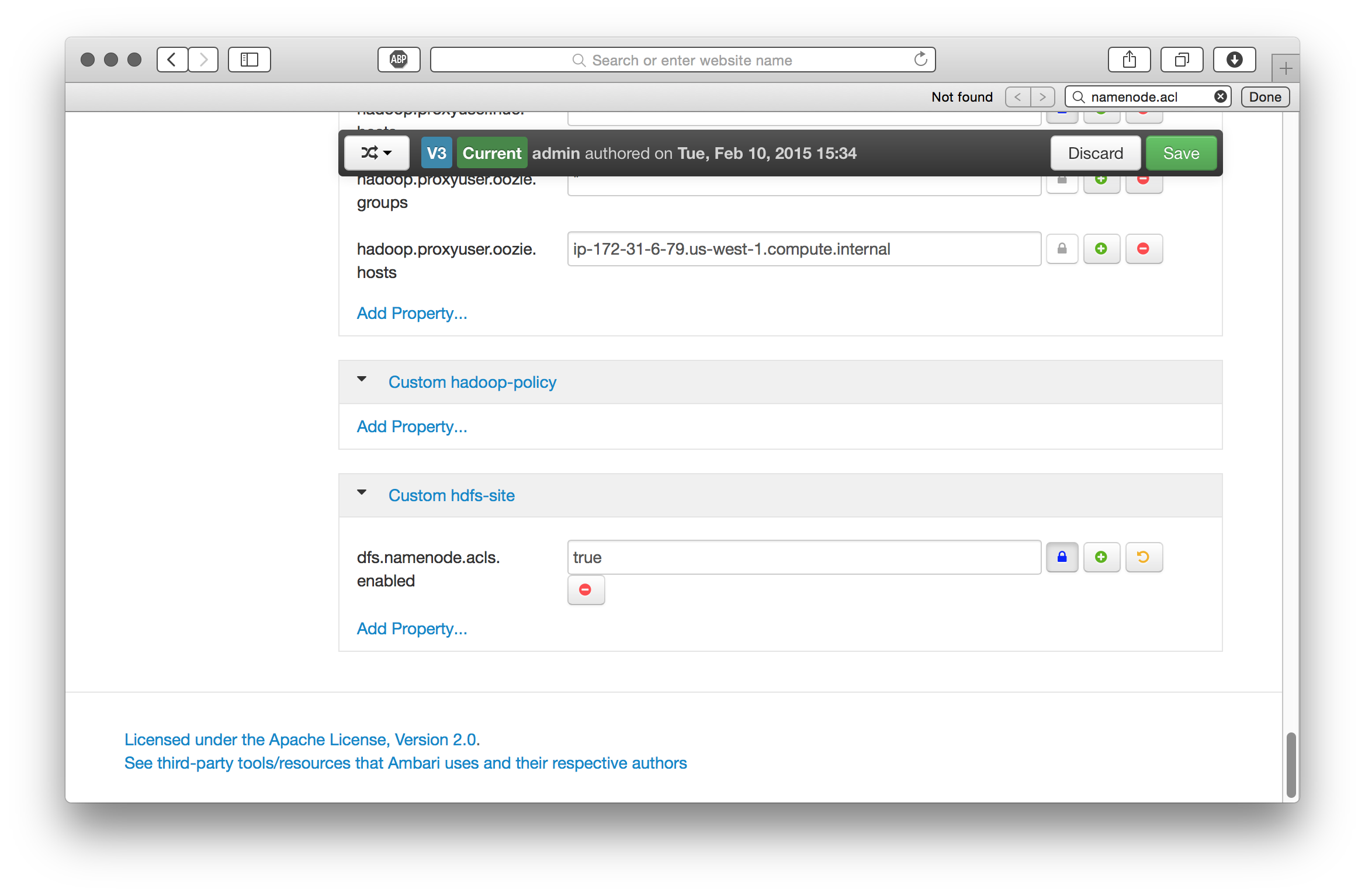
Hive (WebHcat) and Oozie
We’ll also need to set up proxy user hosts and groups for HUE in our Hive and Oozie service configurations.
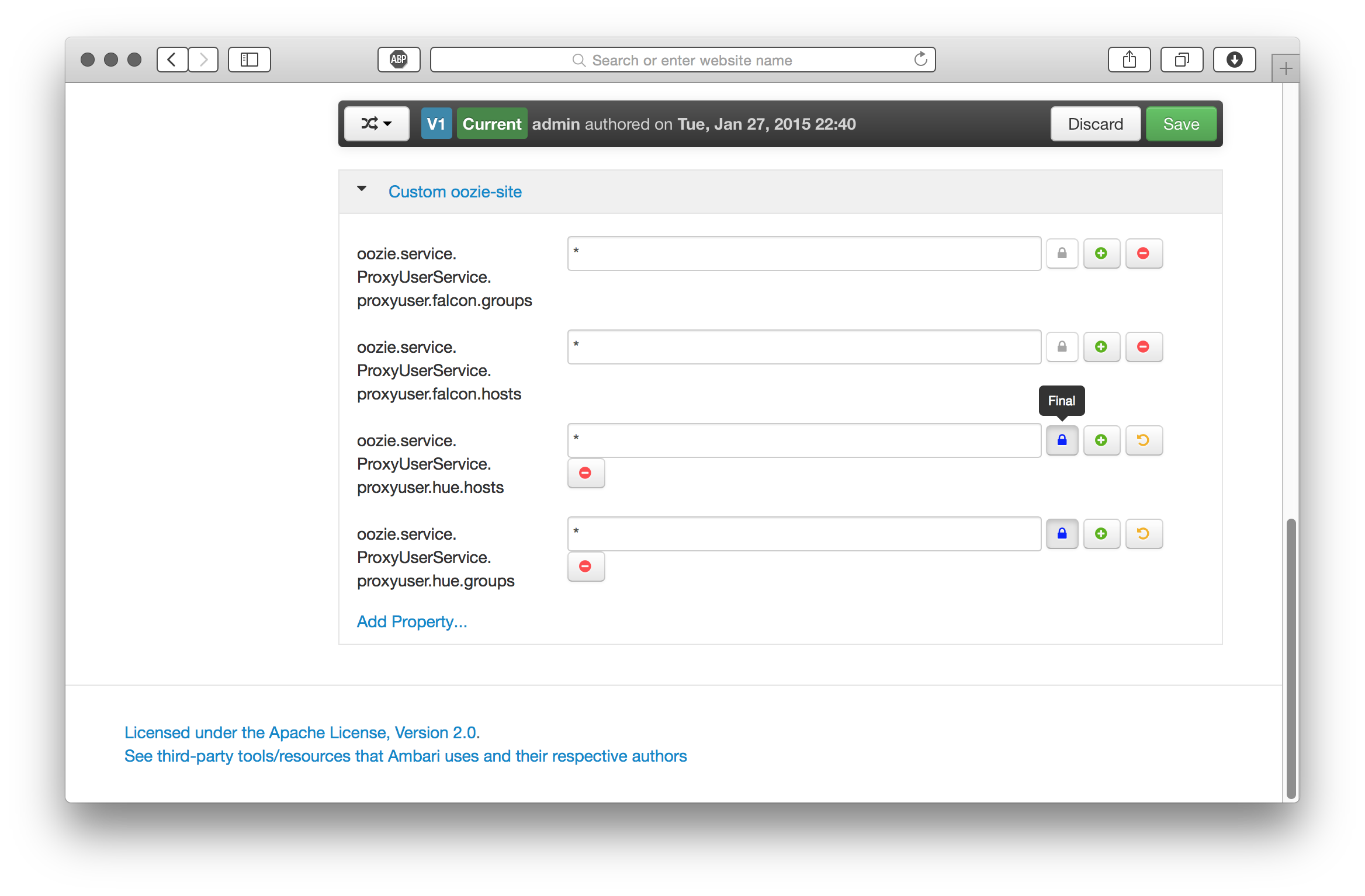
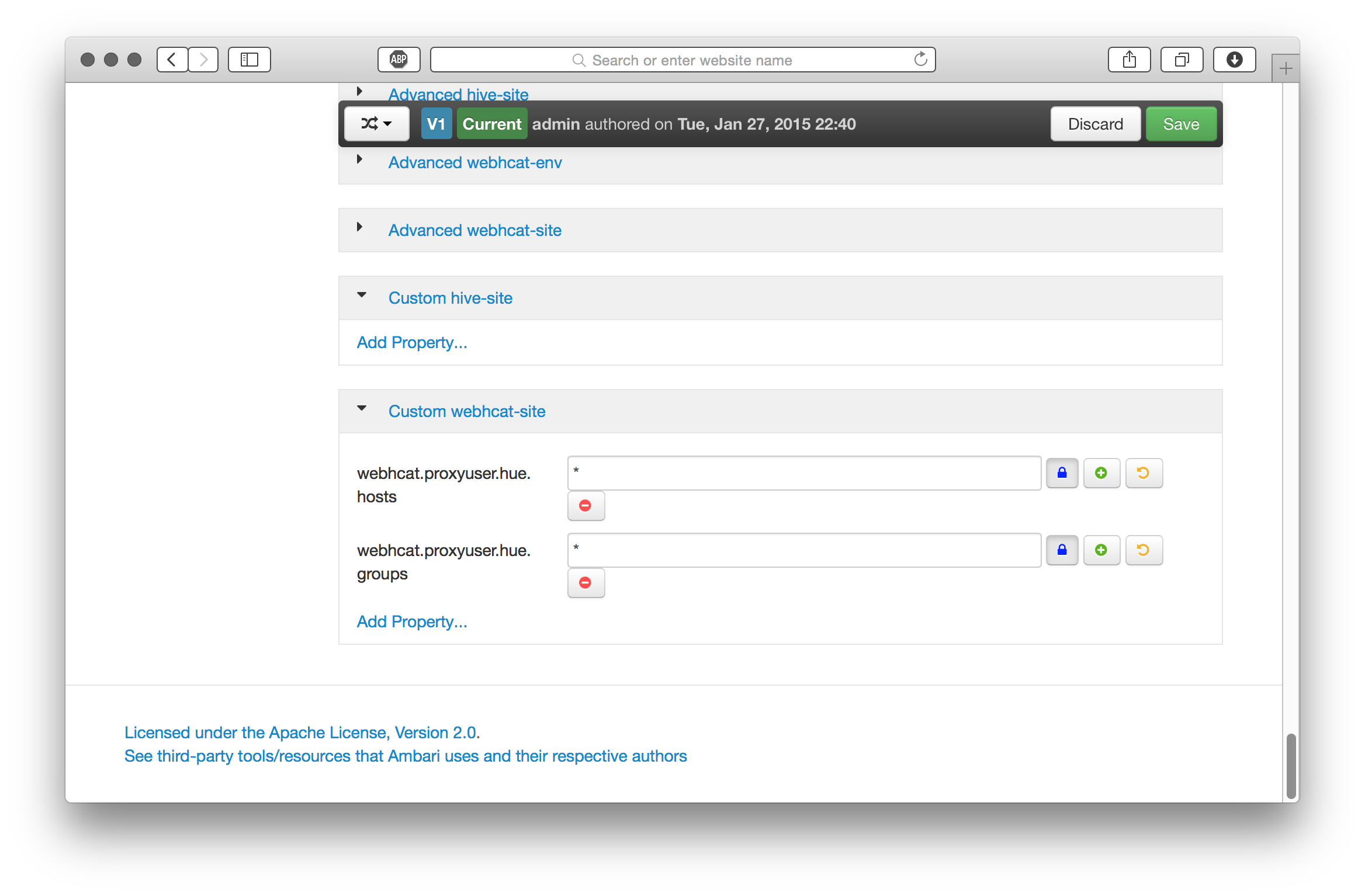
Once these cluster configuration updates have been set, save, and restart these services on the respective cluster nodes.
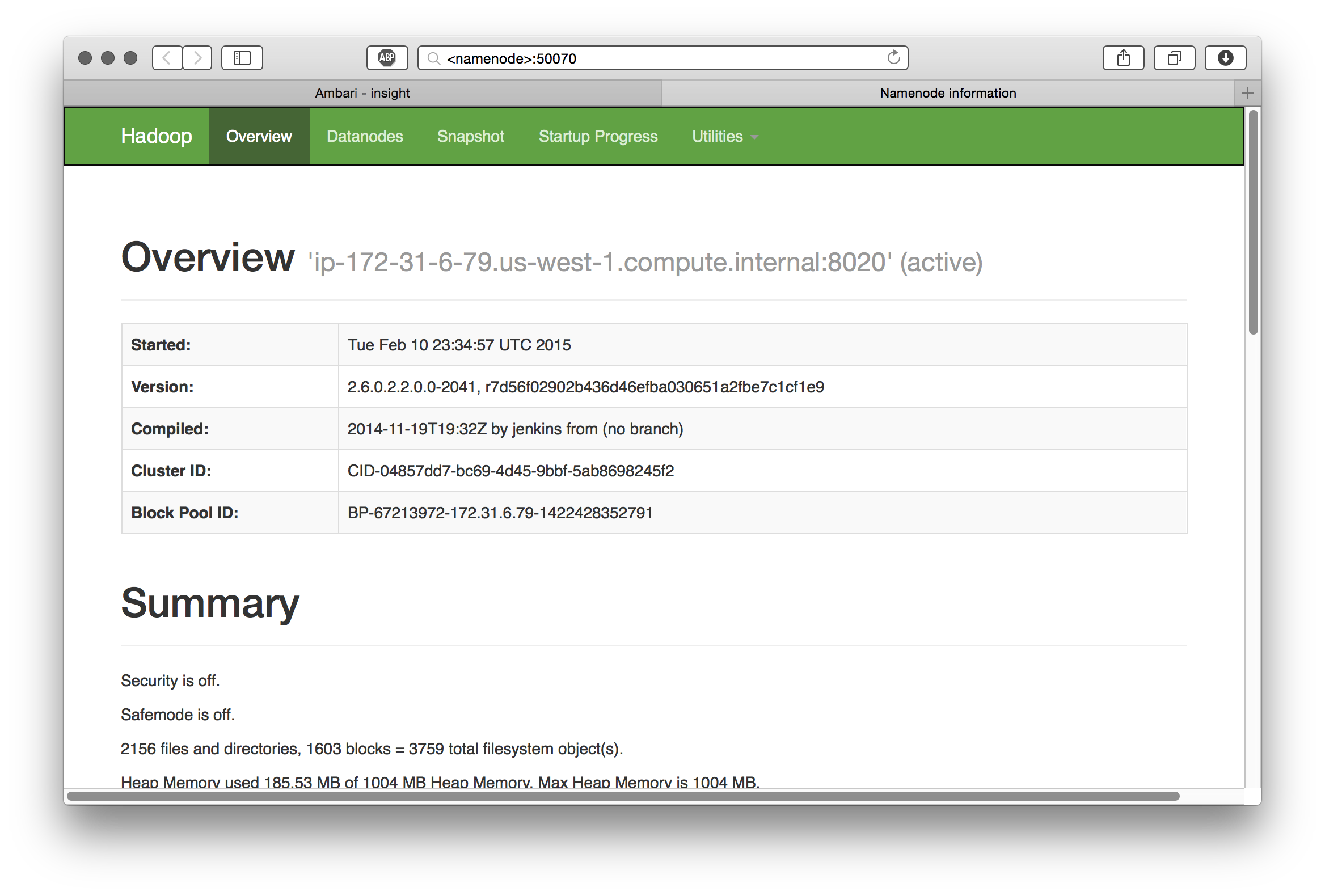
Confirm WebHDFS is running:
HUE Configuration
The HUE configuration file can be found at ‘/usr/local/hue/desktop/conf/hue.ini’
Be sure to make a backup before editing!
We’ll need to populate ‘hue.ini’ with our cluster’s configuration information.
Examples are included below, but will vary with your cluster’s configuration.
In this example, the cluster is small, so our cluster NodeNode also happens to be the Hive Server, Hive Metastore, HBase Master, one of three Zookeepers, etc.
WebHDFS needs to point to our cluster NameNode:

Configure the correct values for our YARN cluster Resource Manager, Hive, Oozie, etc:
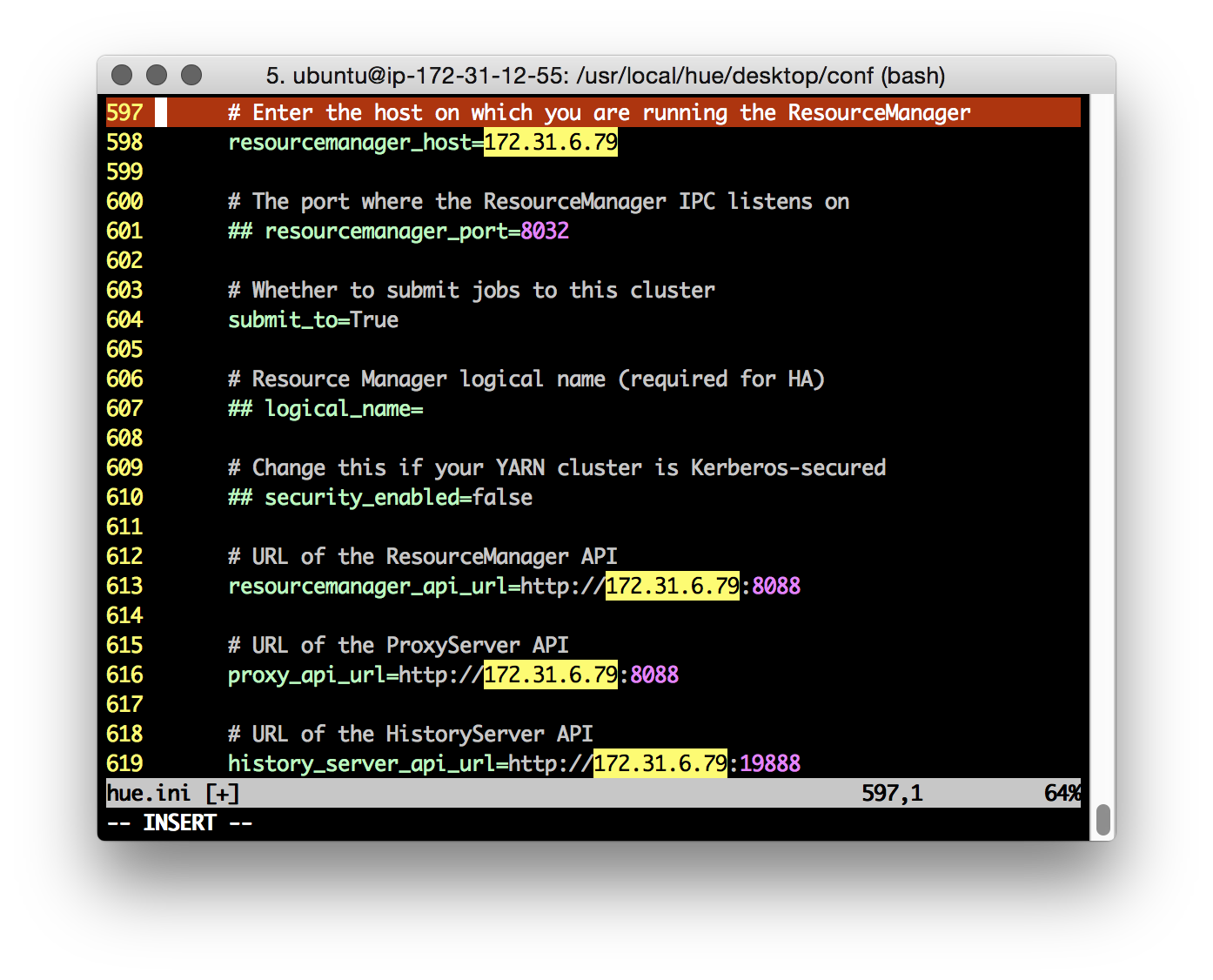
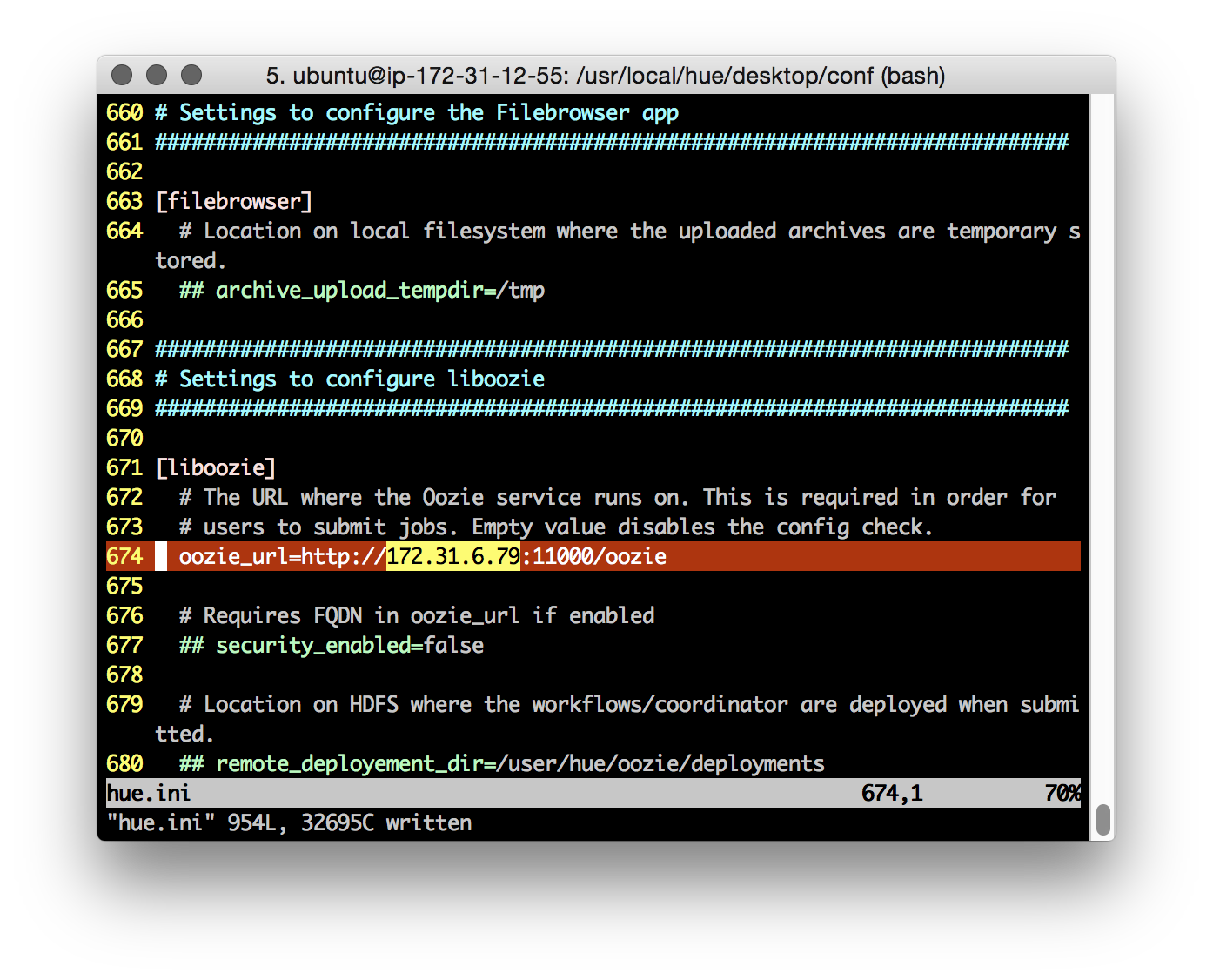
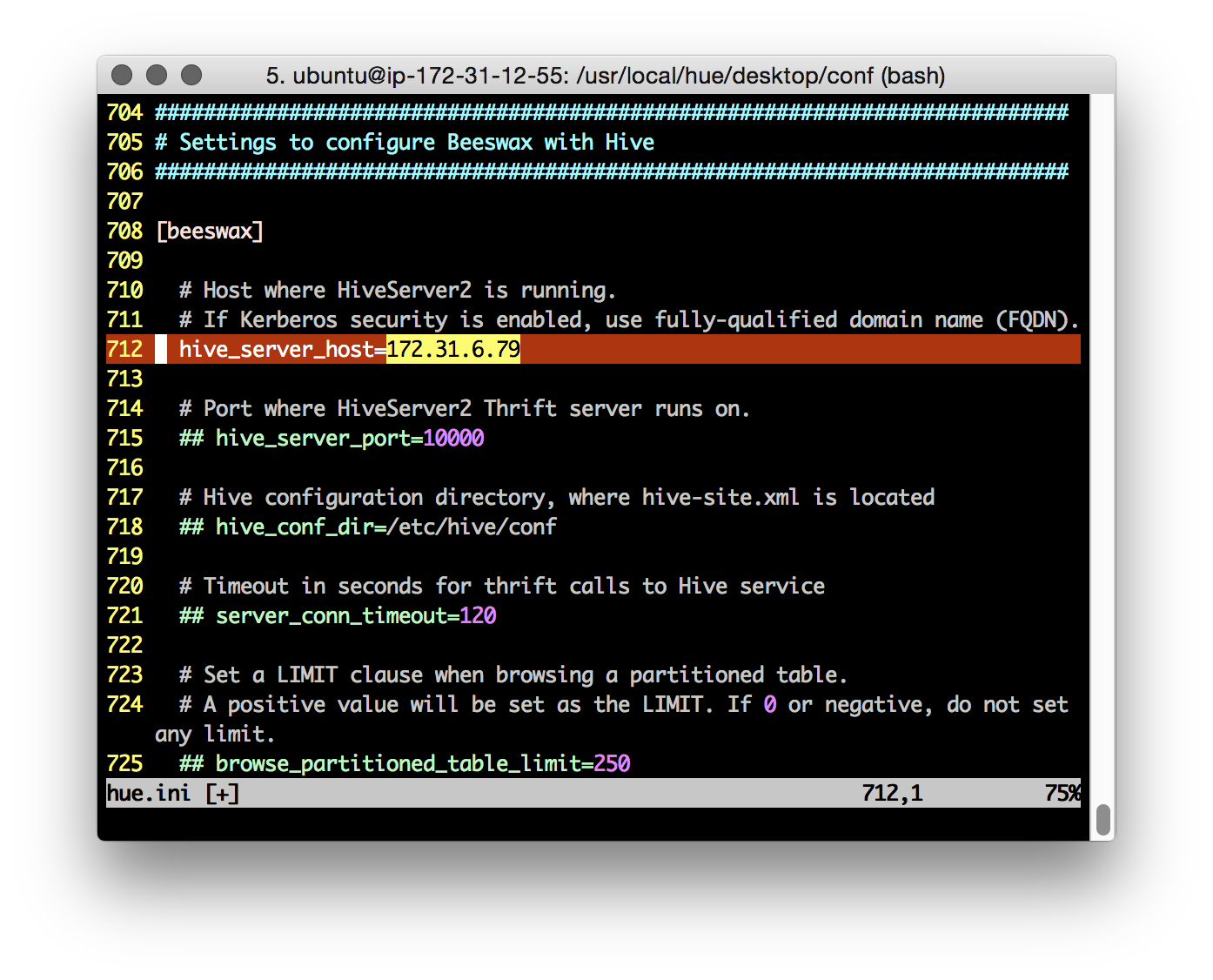

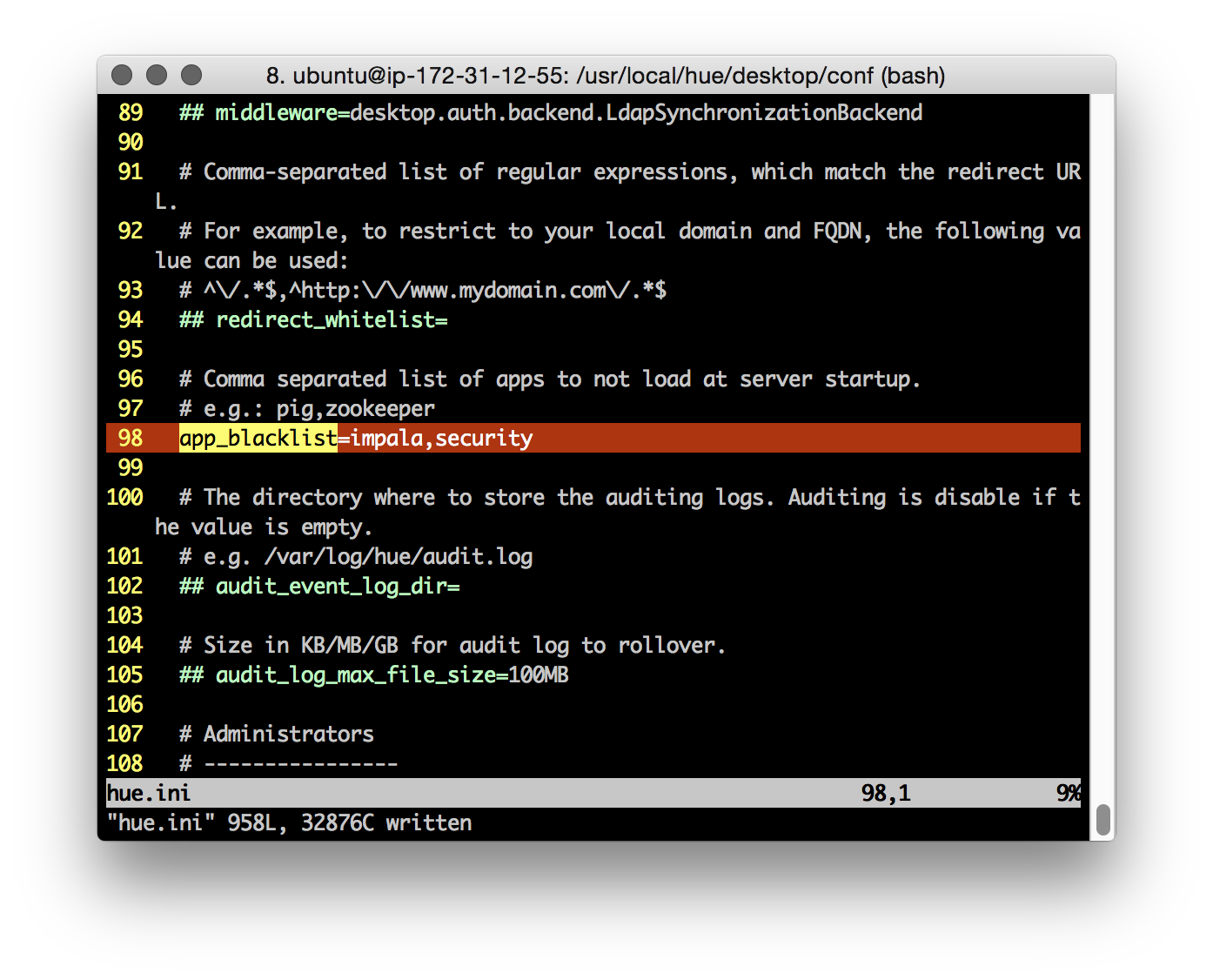
To disable HUE ‘apps’ that aren’t necessary, or are unsupported, for our cluster, use the Desktop ‘app_blacklist’ property. Here I’m disabling the Impala and Sentry/Security tabs (note: the HDFS FACLs tab is disabled if the ‘Security’ app is disabled).
Start HUE on HDP
• We start the HUE server using the ‘supervisor’ command.
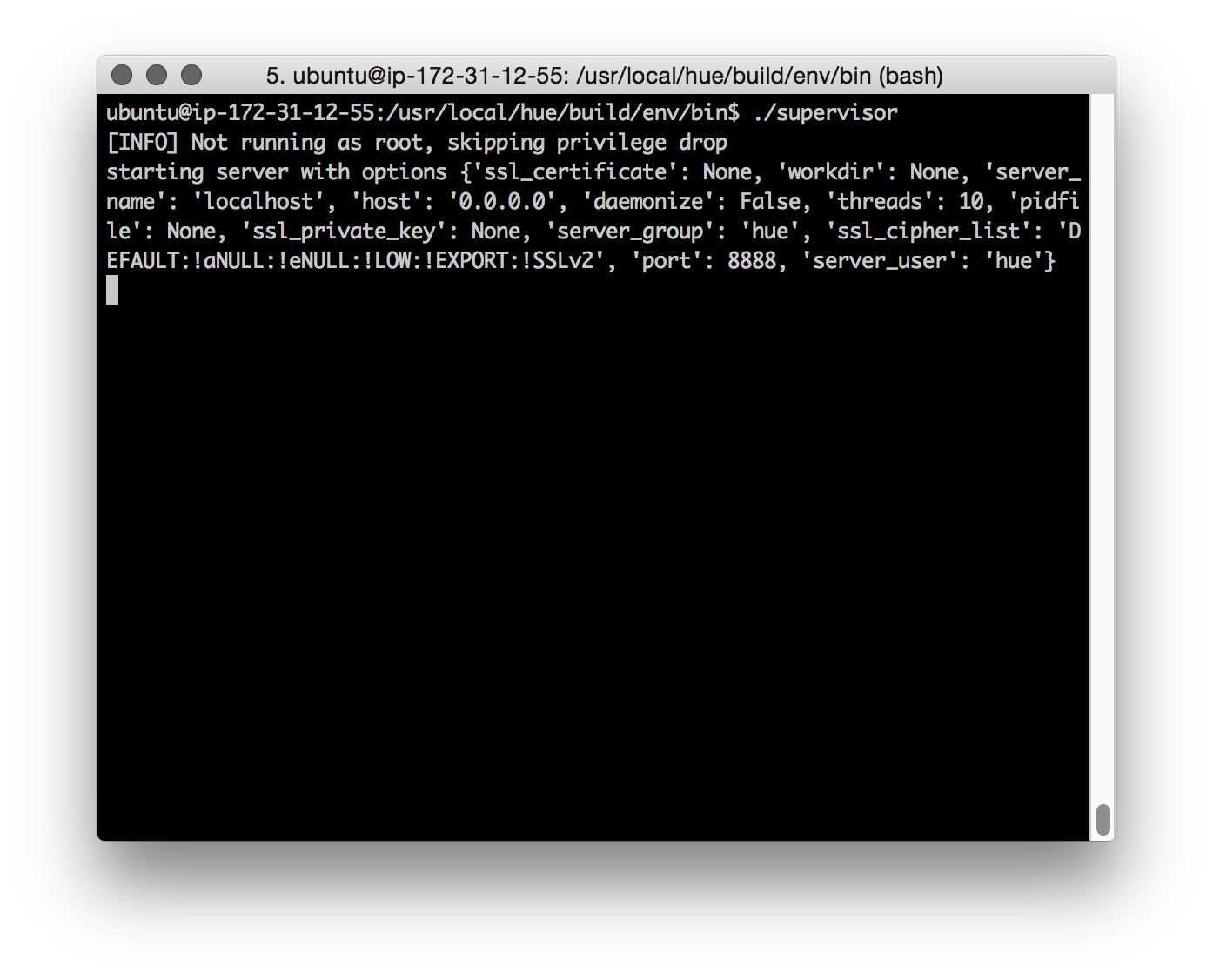
• Use the ‘-d’ switch to start the HUE supervisor in daemon mode
Connect to your new HUE server at its IP address/FQDN and the default port of ‘8888’

It works!
Congratulations, you’re running HUE 3.7.1 with HDP 2.2!
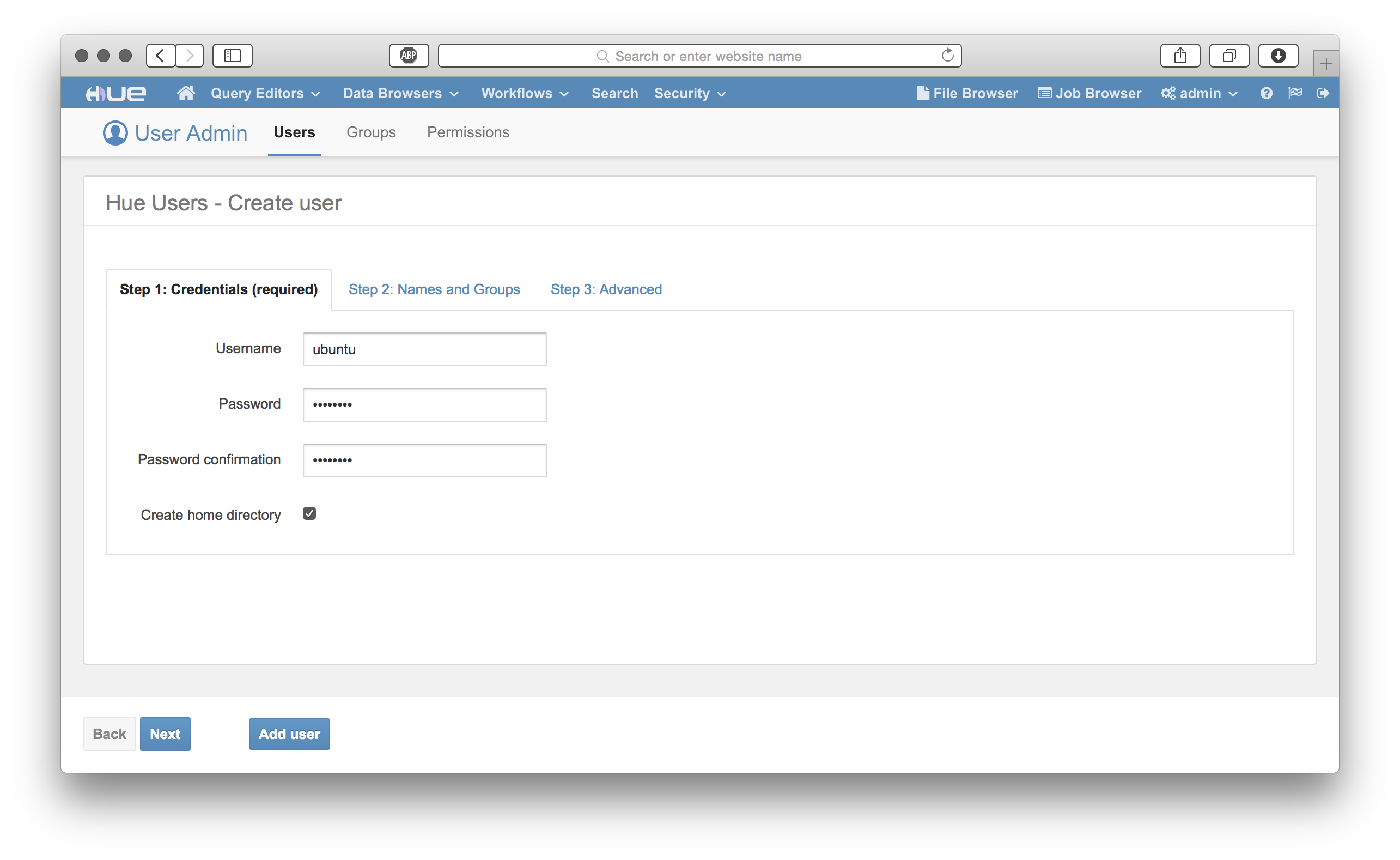
Let’s take a look around at HUE’s great features:
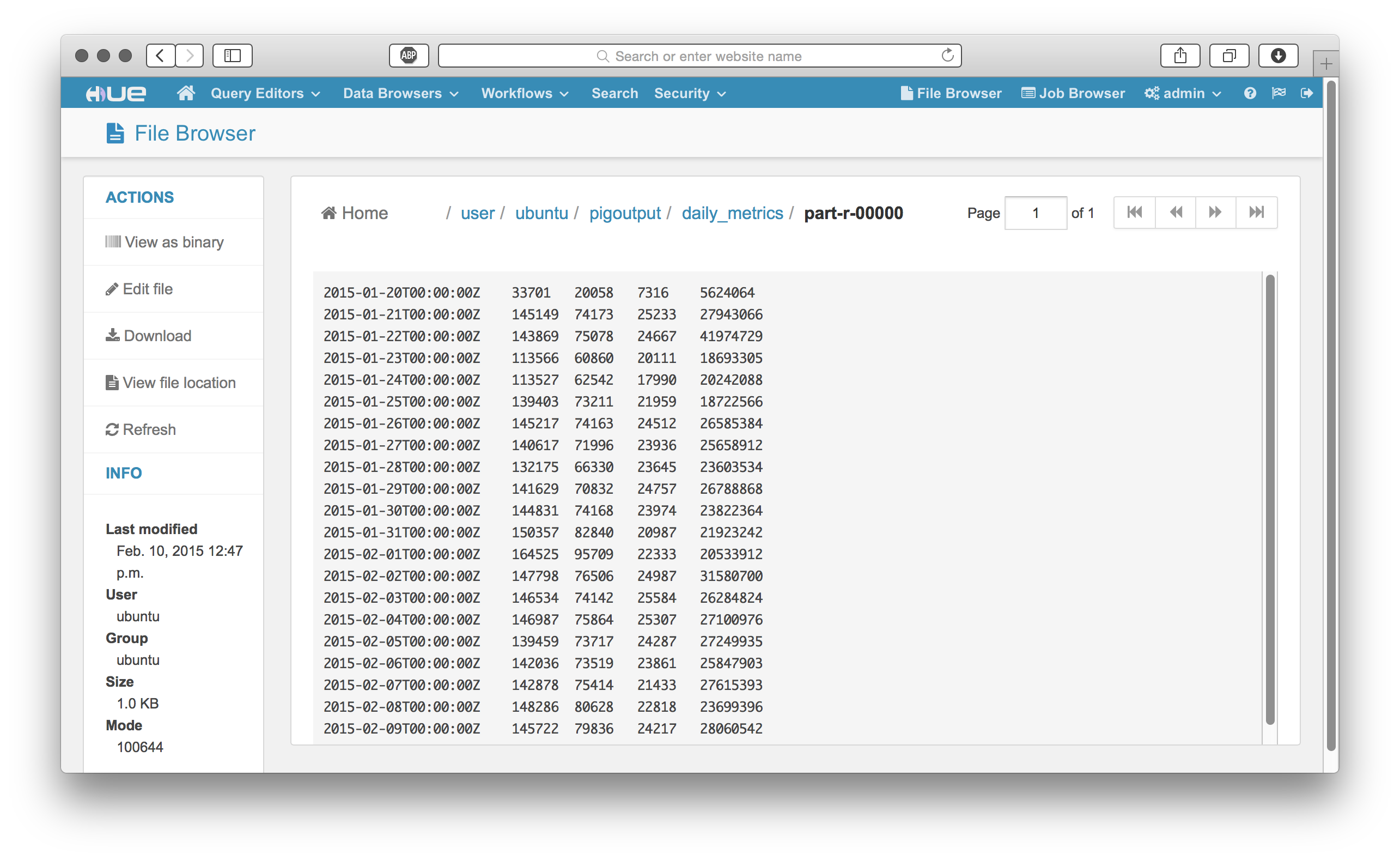

Have any questions? Feel free to contact Andrew or the hue-user list / @gethue!