Hi Big Data Adventurers,
The Hue Team is glad to thanks all the contributors and release Hue 3.11! ![]()
The focus was on the integration with Amazon Cloud Service and improving the SQL user experience. More than 700 commits on top of 3.10 went in! Go grab the tarball release and give it a spin!
Here is a list of the main improvements. For all the changes, check out the release notes.
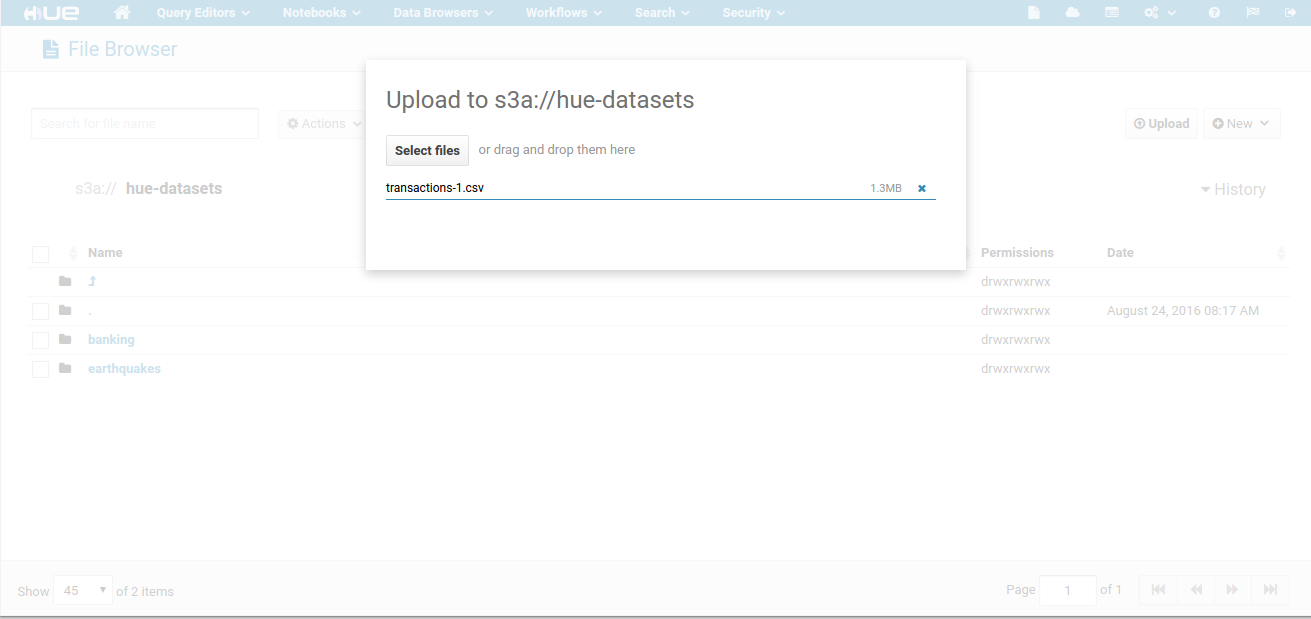
S3 Browser
Hue can be setup to read and write to a configured S3 account, and users can directly query from and save data to S3 without any intermediate moving/copying to HDFS:
- List, browse
- Upload, download
- Create external Hive table
- Export query result
- List S3 URI in Sentry
- Set Oozie coordinator dependencies on S3 paths
- Read more about it here...
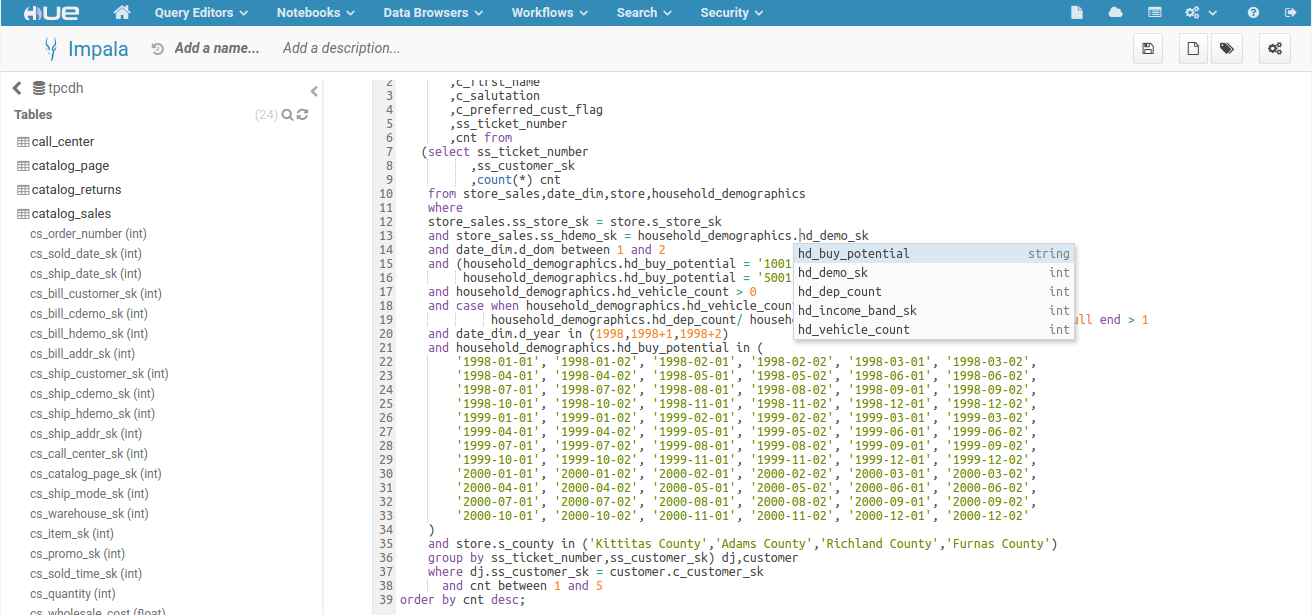
SQL Autocompleter
To make your SQL editing experience better we’ve created a brand new autocompleter. The old one had some limitations and was only aware of parts of the statement being edited. The new autocompleter knows all the ins and outs of the Hive and Impala SQL dialects and will suggest keywords, functions, columns, tables, databases, etc. based on the structure of the statement and the position of the cursor.
- Brand new SQL grammar for Hive and Impala
- Support all the major operations like SELECT, CREATE, DROP
- Autocomplete UDFs and show their documentation
- Weight keywords and columns by importance
- Infer the types and propose compatible columns or UDFs
- Read more about it here...
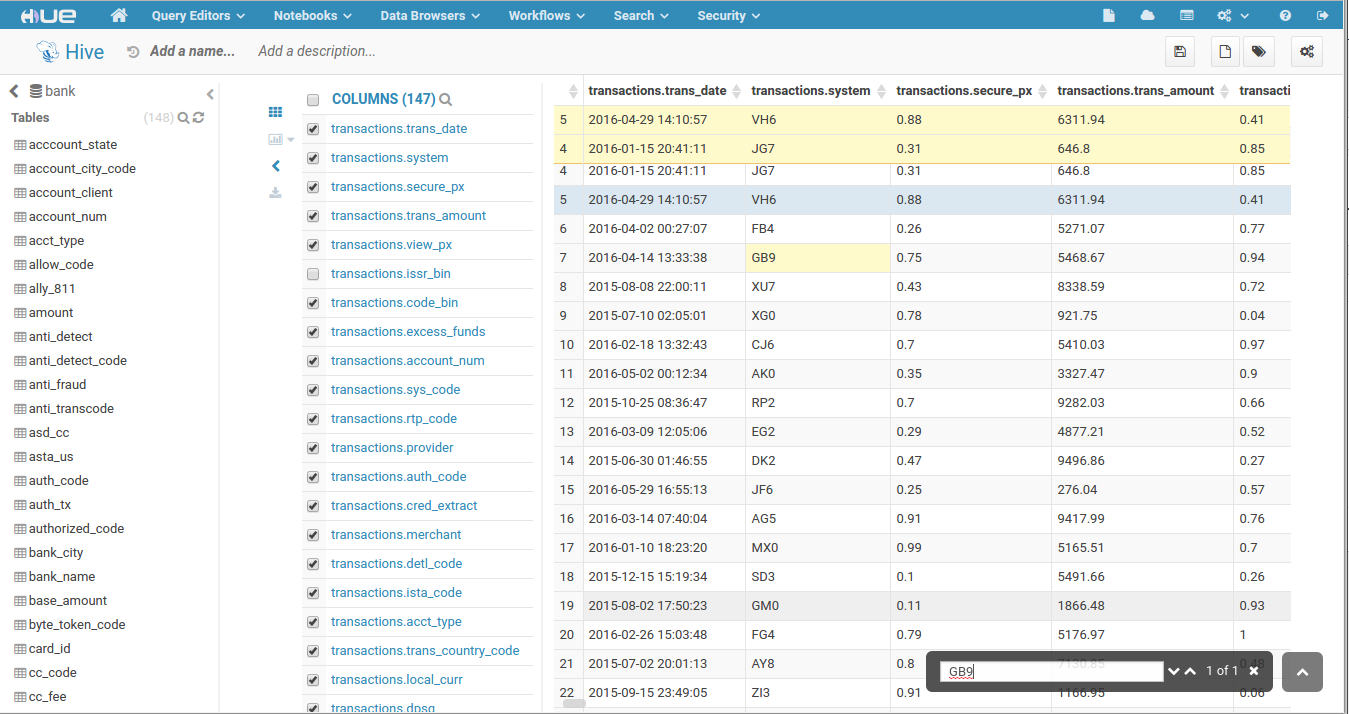
SQL Result Refinements
The SQL Editor now brings a completely re-written result grid that improves the performances allowing big tables to be displayed without the browser to crash, plus some nifty tools for you.
- Result grid improvements
- Timeout popup when Impala hangs on fetch result
- Offer to fix certain rows
- Search through the results
- Excel download now has a progress status
- Fixed resultset legend and header when scrolling throught the results
- Column and type search
- Optimized to display hundred columns
- Export SQL query result to Solr
- Read more about it here...
Solr Indexer
In the past, indexing data into Solr has been quite difficult. The task involved writing a Solr schema and a morphlines file then submitting a job to YARN to do the indexing. Often times getting this correct for non trivial imports could take a few days of work. Now with Hue’s new feature you can start your YARN indexing job in minutes. This tutorial offers a step by step guide on how to do it.
Read more about it here…
Conferences

It was a pleasure to present at the Hadoop Summit in California:
Team Retreats

Next!
Next iteration (Hue 3.12, estimated for end of 2016) will focus on SQL improvements, job monitoring and more Cloud integration.
Hue 4 design will get more real, with the goal of becoming the equivalent of “Gmail for queries for Big Data”. The current apps are being unified into the new Editor and the whole Hue will become a single app in order to provide a much smoother and faster UX.
Onwards!
As usual thank you to all the project contributors and for sending feedback and participating on the hue-user list or @gethue!