Hi Data Crunchers,
Are you looking at executing your SQL queries more easily? Here is a series of various querying improvements coming in the next release of Hue!
New Databases
Hue is getting a more polished experience with Apache Phoenix, Apacke Flink SQL and Apache Spark SQL (via Apache Livy).
Apache Phoenix
Apache Phoenix makes it easy to query the Apache HBase database via SQL. Now the integration is fully working out of the box and several corner cases (e.g. handle the default Phoenix database, list tables and column in the left assist, impersonation support…) have been fixed.
Apache Flink SQL
Apache Flink support for SQL querying data streams is maturing and also getting a first integration with the Editor.
Note Support for KsqlDB is also making progress as they both share similar functionalities: live queries and result grid
Apache SparkSql
SparkSql is very popular and getting a round of improvements when executing SQL queries via Apache Livy. Note that the traditional SqlAlchemy connectors or HiveServer Thrift are working too.
UDF / Functions
Dynamic listing
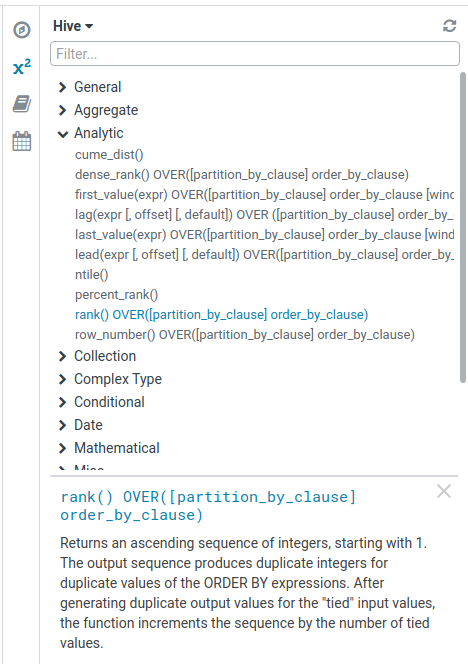
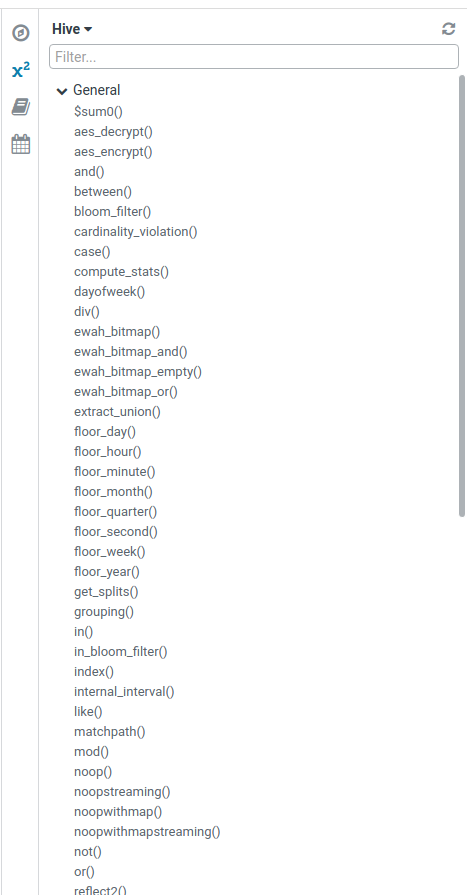
Not all the functions are listed in the editor (some are registered at the session/company level, some have been created after a Hue release, some are missing and can be added etc…).
Now the editor will ask the Database for its full list of functions and add the missing ones in the General section.
Arguments
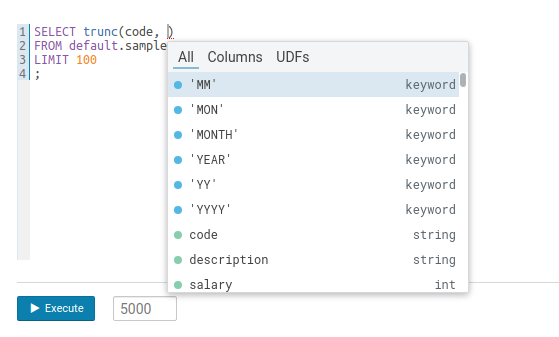
Argument positioning is now understood and the constant arguments of popular functions are also available. For example the formats for date conversion in position two will now be showcased to the user.
Autocomplete
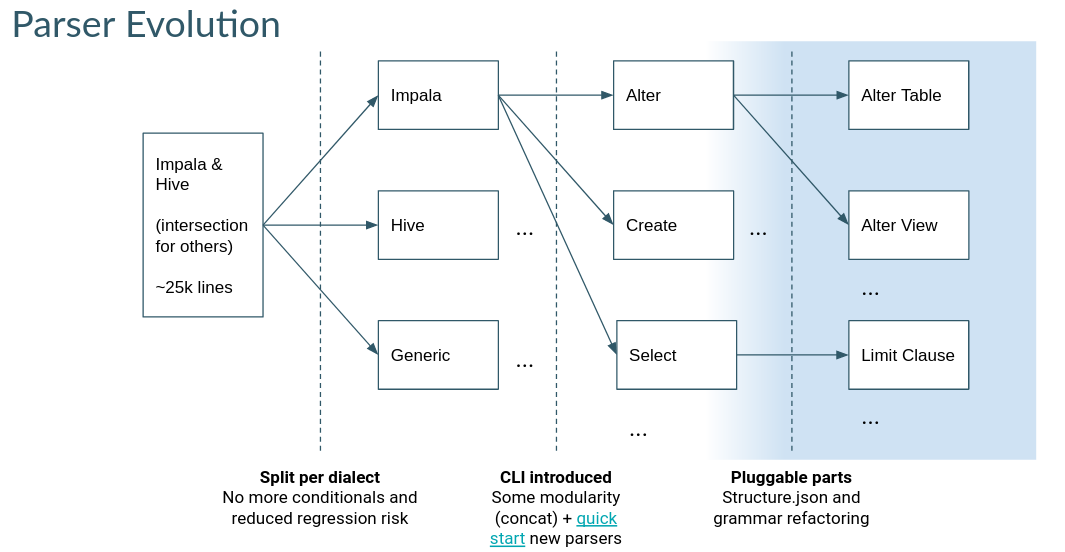
Build your own parser
The parser is being extracted in smaller reusable pieces structure.json with first goal of supporting Apache Calcite SQL subsets. The Parser SDK has more more detailed information.
e.g. structure.json is composed of generic and specific grammar pieces that are reusable across SQL parsers.
structure.json
[...],
"../generic/select/select.jison",
"../generic/select/select_conditions.jison",
"select/select_stream.jison",
"../generic/select/union_clause.jison",
"../generic/select/where_clause.jison",
[...]
select_stream.jison
SelectStatement
: 'SELECT' 'STREAM' OptionalAllOrDistinct SelectList
;
SelectStatement_EDIT
: 'SELECT' 'STREAM' OptionalAllOrDistinct 'CURSOR'
{
if (!$3) {
parser.suggestKeywords(['ALL', 'DISTINCT']);
}
}
;
It is moving away from the non scalable stategy of building big independent parsers to building parsers with shared grammar operations:
Scheduled Hive Queries
Hive 4 natively supports scheduling queries via SQL statements. The autocomplete now supports the SQL syntax as well as the right assist documentation.
* create
create scheduled query Q1 executed as joe scheduled '1 1 * * *' as update t set a=1;
* change schedule
alter scheduled query Q1 cron '2 2 * * *'
* change query
alter scheduled query Q1 defined as select 2
* disable
alter scheduled query Q1 set disabled
* enable
alter scheduled query Q1 set enabled
* list status
select * from sysdb.scheduled_queries;
* drop
drop scheduled query Q1
Note that a fancier mini UI will come with HUE-3797 so that monitoring or scheduling queries is only two clicks away (cf. the right Assist Panel).
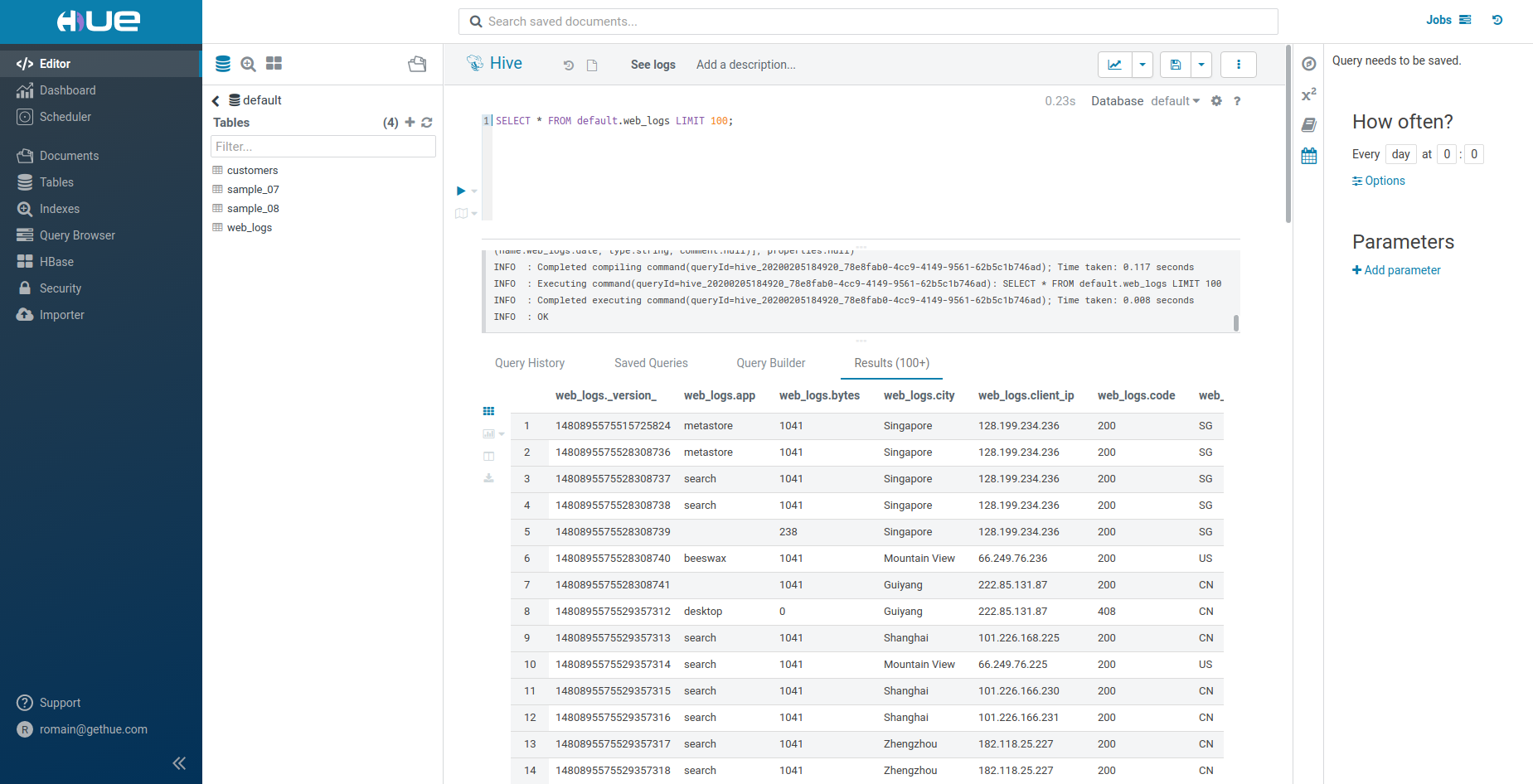
Limit N autocomplete
Now when autocompleting and adding a ‘LIMIT’ to your query, actual sizes will also be proposed.
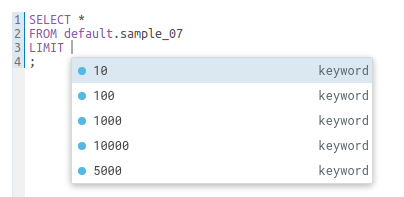
Column Key Icons
Additional icons are available for showing the Foreign Keys, when a column value points to another column in another table. e.g. The head of the business unit must exist in the person table:
![]()
CREATE TABLE person (
id INT NOT NULL,
name STRING NOT NULL,
age INT,
creator STRING DEFAULT CURRENT_USER(),
created_date DATE DEFAULT CURRENT_DATE(),
PRIMARY KEY (id) DISABLE NOVALIDATE
);
CREATE TABLE business_unit (
id INT NOT NULL,
head INT NOT NULL,
creator STRING DEFAULT CURRENT_USER(),
created_date DATE DEFAULT CURRENT_DATE(),
PRIMARY KEY (id) DISABLE NOVALIDATE,
CONSTRAINT fk FOREIGN KEY (head) REFERENCES person(id) DISABLE NOVALIDATE
);
The sample popup now also supports navigating the relationships:
ERD Table
A visual listing of the columns and the foreign key links helps understand quicker the schema and relationships while crafting SQL queries. See a live demo on the documentation page.
Note The new shareable components system will be detailed in a follow-up blog post.
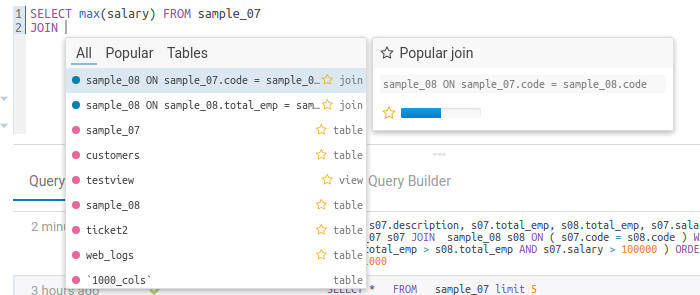
Smart suggestions
A local assistant provides autocomplete suggestions for JOINs and simple Risk alerts (e.g. LIMIT clause missing).
This is a beta feature. Here is how to enable it in the hue.ini.
[medatata]
[[optimizer]]
# Requires Editor v2
mode=local
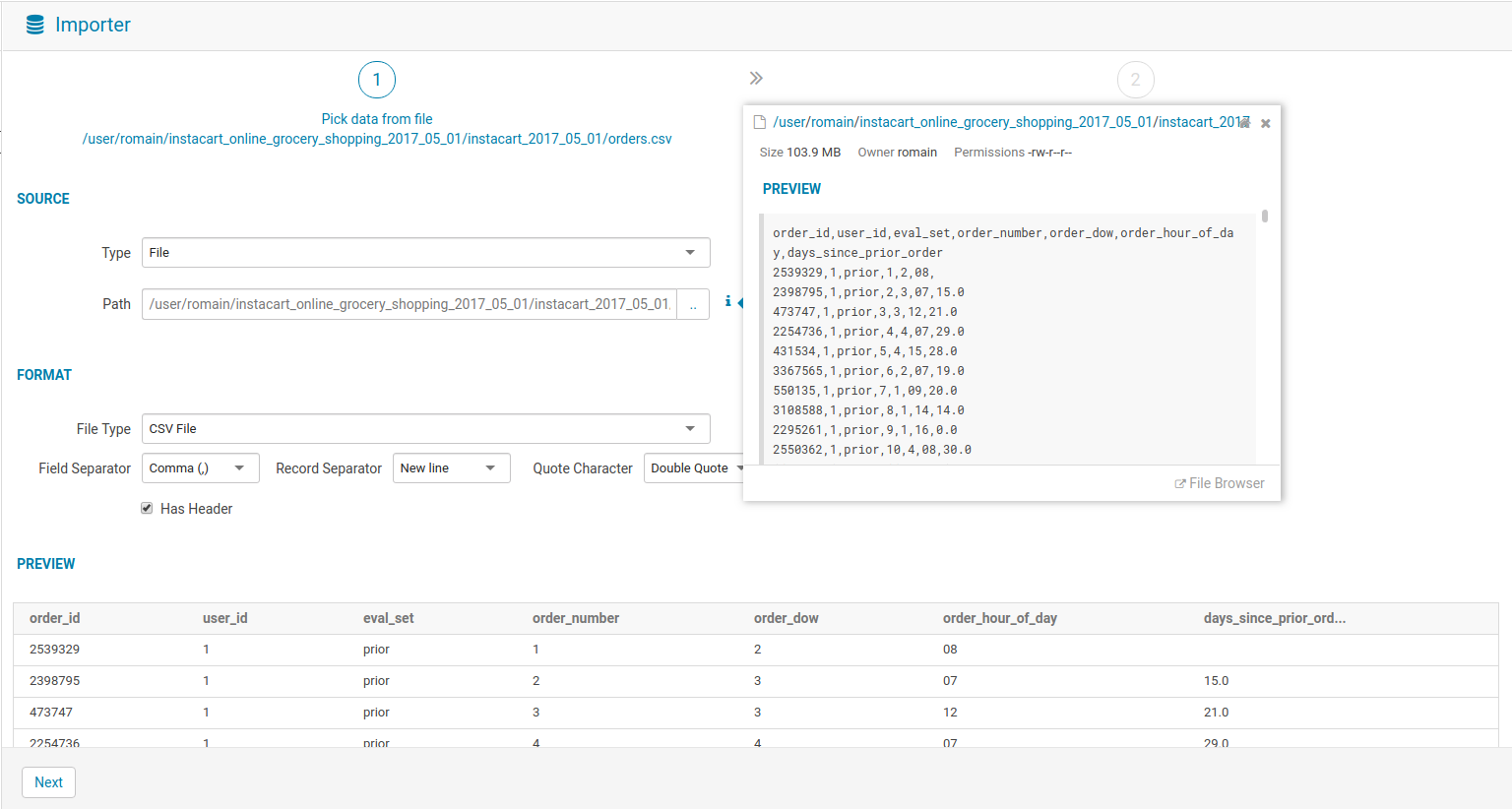
Importer
Some fixes were done on the Data Import Wizard so that creating new SQL tables is easier. Feel free to read more in the previous post
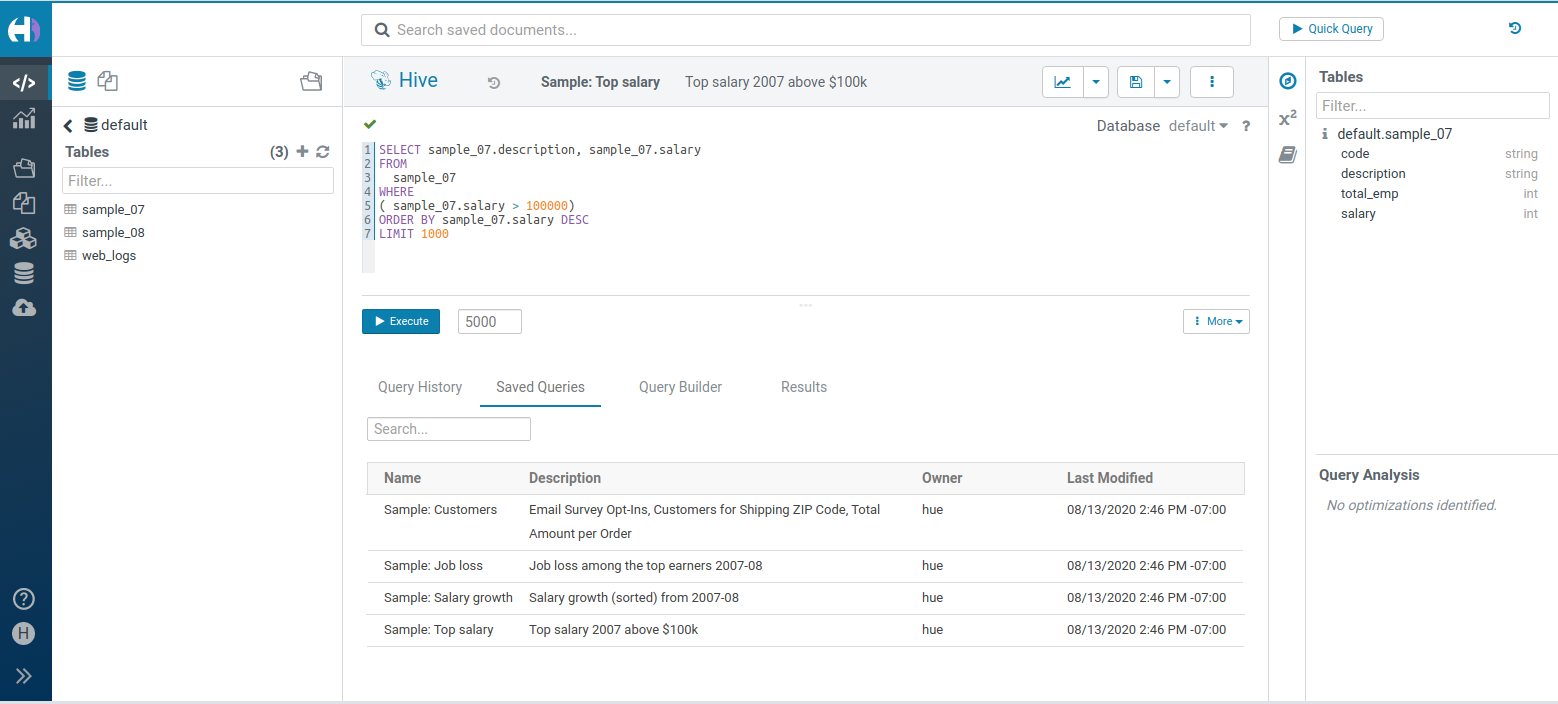
Editor v2 with Connectors
These are beta features and quite a bit of polishing is still needed but it is stable enough that we encourage users to try it and send feedback.
The query execution has been rewritten for better stability and running more than one query at the same time. More details about the new version will be released after the beta.
Here is how to enable it in the hue.ini.
[desktop]
enable_connectors=true
enable_hue_5=true
Note https://demo.gethue.com/ has the new Editor enabled
Any feedback or question? Feel free to comment here or on the Forum and quick start SQL querying!
Onwards!
Romain from the Hue Team