Spark SQL
Update December 2020 Executing Spark SQL via the Spark Thrift Server
Spark SQL is convenient for embedding clean data querying logic within your Spark apps. Hue brings an Editor so that it is easier to develop your SQL snippets.
As detailed in the documentation, Spark SQL comes with different connectors. Here we will just show with Livy.
Apache Livy provides a bridge to a running Spark interpreter so that SQL, pyspark and scala snippets can be executed interactively.
In the hue.ini configure the API url:
[spark]
# The Livy Server URL.
livy_server_url=http://localhost:8998
And as always, make sure you have an interpreter configured:
[notebook]
[[interpreters]]
[[[sparksql]]]
name=Spark SQL
interface=livy
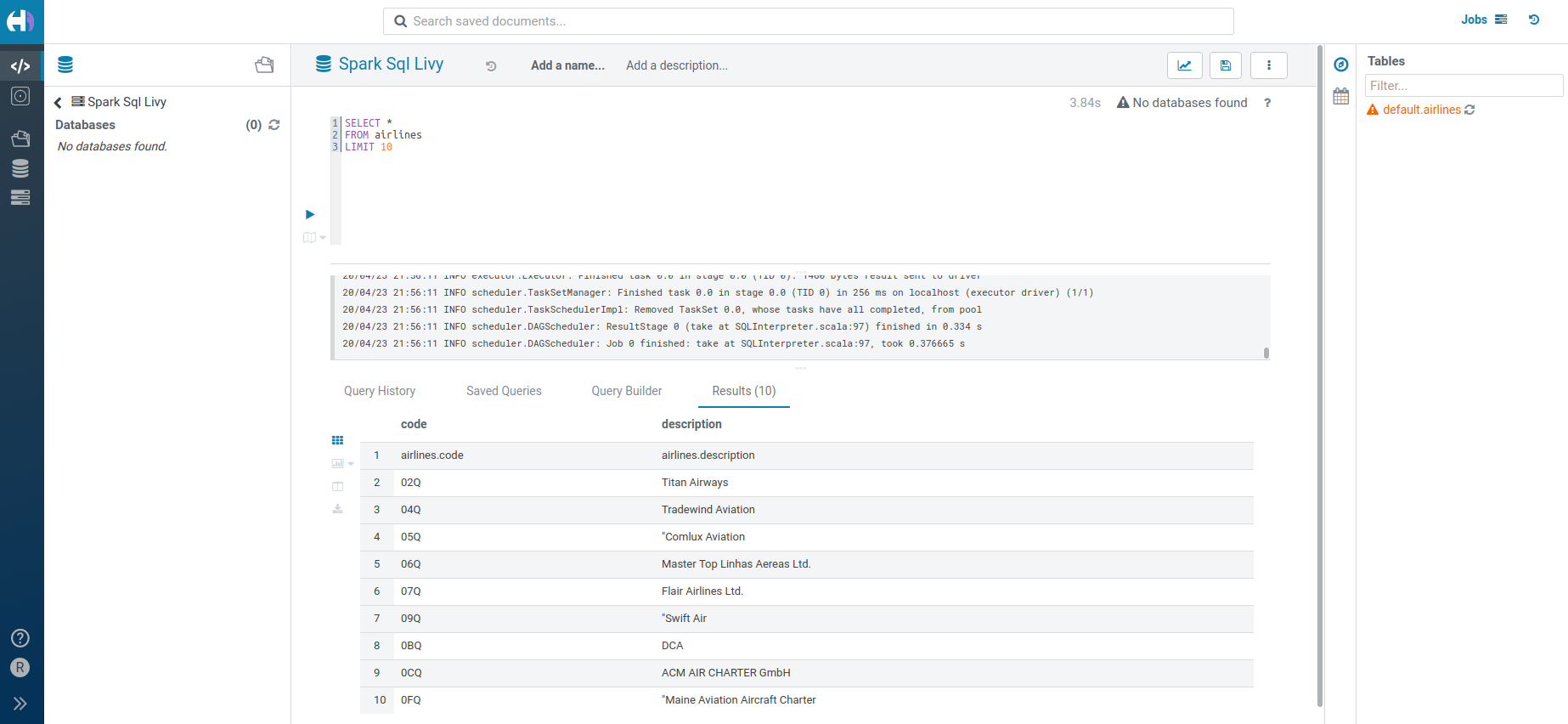
And that's it, the editor will appear:
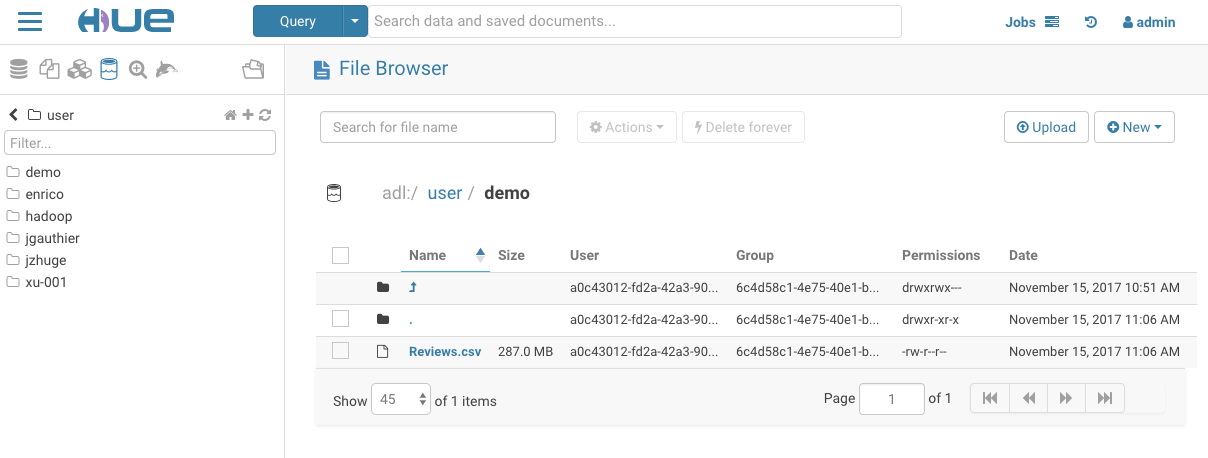
One advantage of using Hue is its File Browser for HDFS / S3 / Azure and full security (Kerberos and even using the real user credentials via Knox IdBroker integration).
Here are some of the future improvements:
- Database/table/column autocomplete is currently empty
- SQL grammar autocomplete can be extended
- SQL Scratchpad module to allow a mini SQL Editor popup is in progress
Any feedback or question? Feel free to comment here or on the Forum and quick start SQL querying!
Romain from the Hue Team