Livy is an open source REST interface for using Spark from anywhere.
Note: Livy is not supported in CDH, only in the upstream Hue community.
It supports executing snippets of code or programs in a Spark Context that runs locally or in YARN. This makes it ideal for building applications or Notebooks that can interact with Spark in real time. For example, it is currently used for powering the Spark snippets of the Hadoop Notebook in Hue.
In this post we see how we can execute some Spark 1.5 snippets in Python.
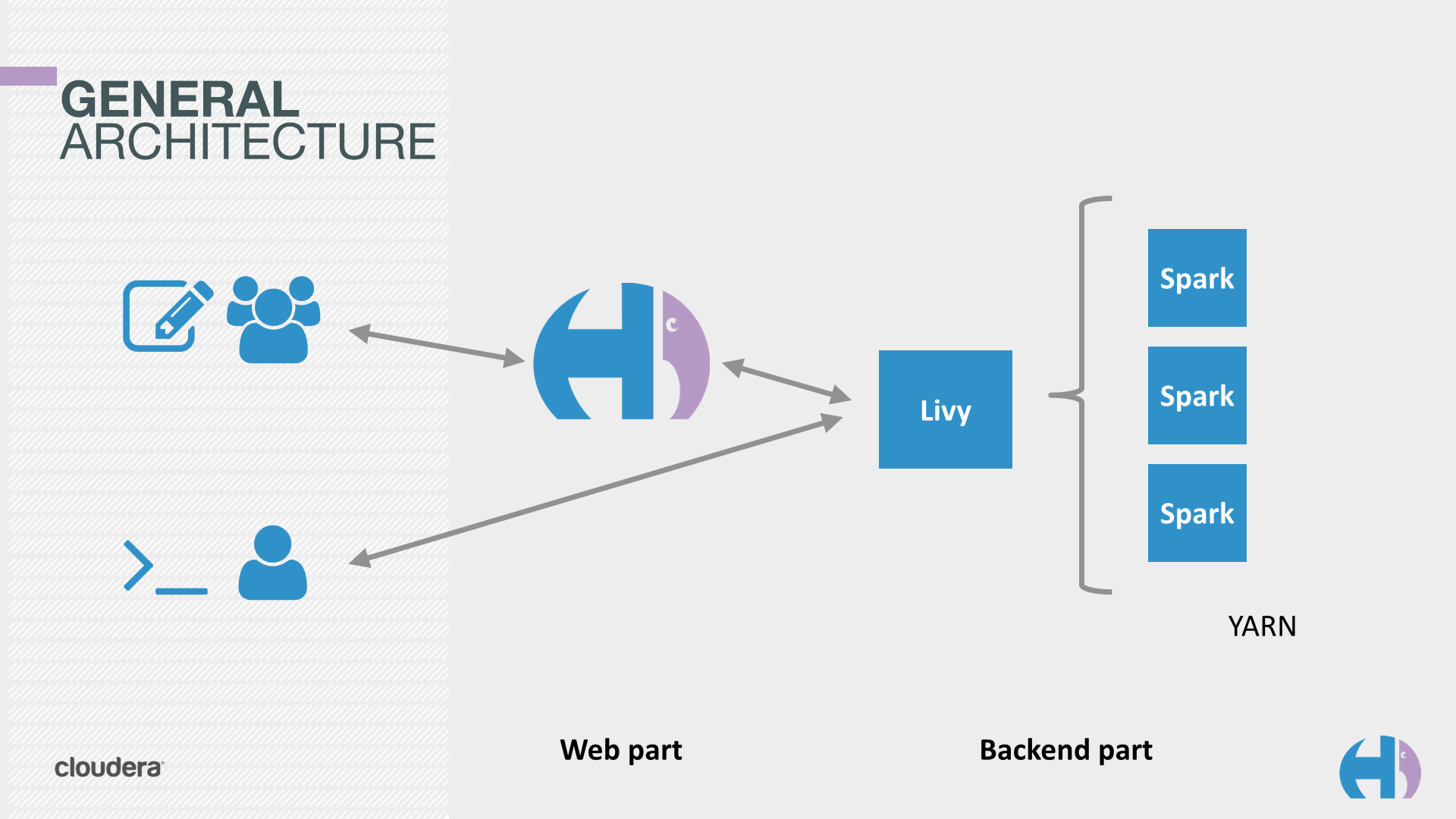
Livy sits between the remote users and the Spark cluster
Starting the REST server
Based on the README, we check out Livy's code. It is currently living in Hue repository for simplicity but hopefully will eventually graduate in its top project.
git clone [email protected]:cloudera/hue.gitThen we compile Livy with
cd hue/apps/spark/java
mvn -DskipTests clean package
Export these variables
export SPARK_HOME=/usr/lib/spark
export HADOOP_CONF_DIR=/etc/hadoop/confAnd start it
./bin/livy-serverNote: Livy defaults to Spark local mode, to use the YARN mode copy the configuration template file apps/spark/java/conf/livy-defaults.conf.tmpl into livy-defaults.conf and set the property:
livy.server.session.factory = yarn
Executing some Spark
As the REST server is running, we can communicate with it. We are on the same machine so will use ‘localhost’ as the address of Livy.
Let's list our open sessions
curl localhost:8998/sessions
{"from":0,"total":0,"sessions":[]}
Note
You can use
| python -m json.toolat the end of the command to prettify the output, e.g.:
curl localhost:8998/sessions/0 | python -m json.tool
There is zero session. We create an interactive PySpark session
curl -X POST -data '{"kind": "pyspark"}' -H "Content-Type: application/json" localhost:8998/sessions
{"id":0,"state":"starting","kind":"pyspark","log":[]}
Sessions ids are incrementing numbers starting from 0. We can then reference the session later by its id.
Livy supports the three languages of Spark:
| Kinds |
| spark |
| pyspark |
| sparkr |
We check the status of the session until its state becomes idle: it means it is ready to be execute snippet of PySpark:
curl localhost:8998/sessions/0 | python -m json.tool
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1185 0 1185 0 0 72712 0 -:-:- -:-:- -:-:- 79000
{
"id": 5,
"kind": "pyspark",
"log": [
"15/09/03 17:44:14 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.",
"15/09/03 17:44:14 INFO ui.SparkUI: Started SparkUI at http://172.21.2.198:4040",
"15/09/03 17:44:14 INFO spark.SparkContext: Added JAR file:/home/romain/projects/hue/apps/spark/java-lib/livy-assembly.jar at http://172.21.2.198:33590/jars/livy-assembly.jar with timestamp 1441327454666",
"15/09/03 17:44:14 WARN metrics.MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.",
"15/09/03 17:44:14 INFO executor.Executor: Starting executor ID driver on host localhost",
"15/09/03 17:44:14 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 54584.",
"15/09/03 17:44:14 INFO netty.NettyBlockTransferService: Server created on 54584",
"15/09/03 17:44:14 INFO storage.BlockManagerMaster: Trying to register BlockManager",
"15/09/03 17:44:14 INFO storage.BlockManagerMasterEndpoint: Registering block manager localhost:54584 with 530.3 MB RAM, BlockManagerId(driver, localhost, 54584)",
"15/09/03 17:44:15 INFO storage.BlockManagerMaster: Registered BlockManager"
],
"state": "idle"
}
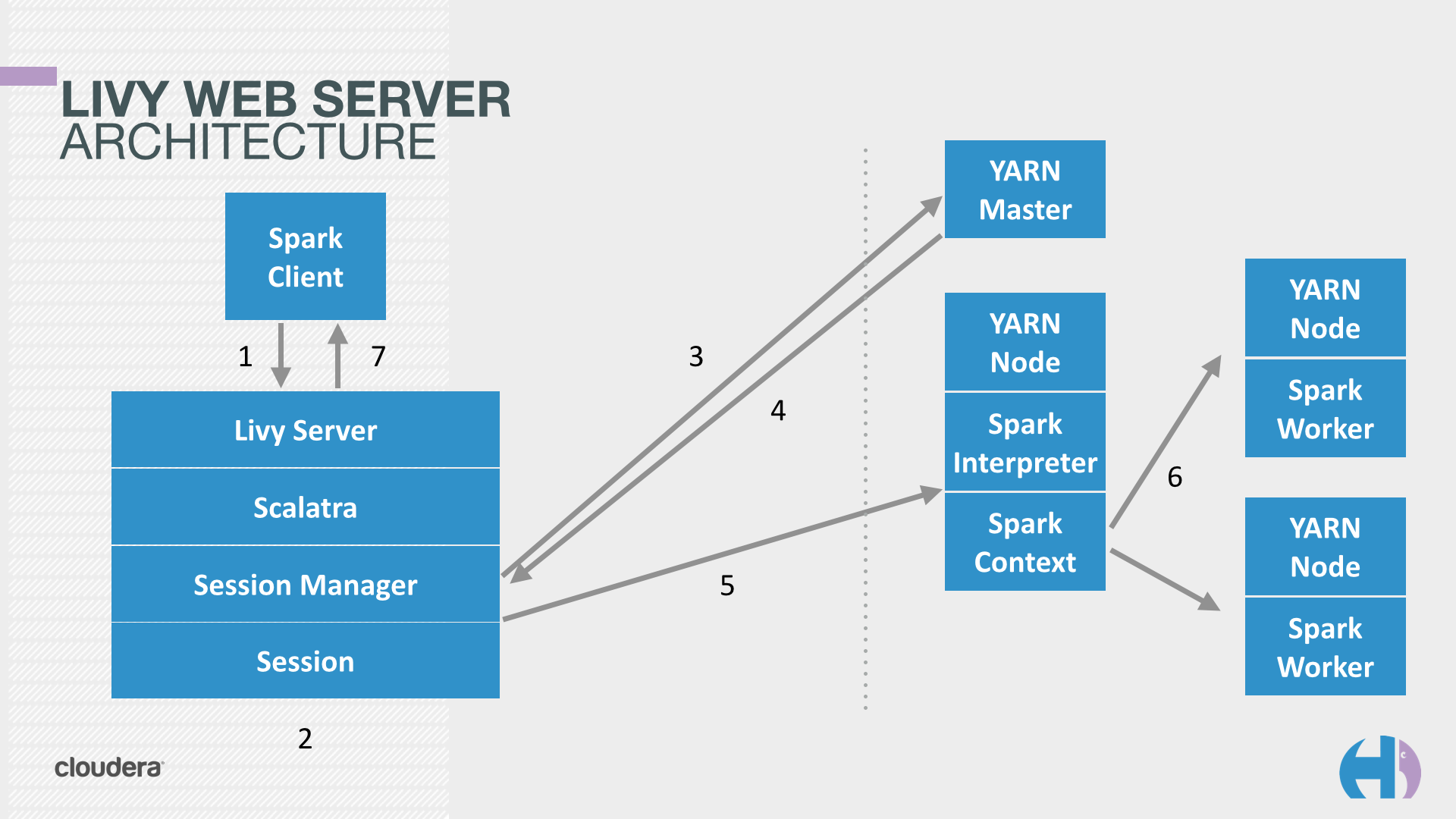
In YARN mode, Livy creates a remote Spark Shell in the cluster that can be accessed easily with REST
When the session state is idle, it means it is ready to accept statements! Lets compute 1 + 1
curl localhost:8998/sessions/0/statements -X POST -H 'Content-Type: application/json' -d '{"code":"1 + 1"}'
{"id":0,"state":"running","output":null}
We check the result of statement 0 when its state is available
curl localhost:8998/sessions/0/statements/0
{"id":0,"state":"available","output":{"status":"ok","execution_count":0,"data":{"text/plain":"2"}}}
Note
If the statement is taking less than a few milliseconds, Livy returns the response directly in the response of the POST command.
Statements are incrementing and all share the same context, so we can have a sequences
curl localhost:8998/sessions/0/statements -X POST -H 'Content-Type: application/json' -d '{"code":"a = 10"}'
{"id":1,"state":"available","output":{"status":"ok","execution_count":1,"data":{"text/plain":""}}}
Spanning multiple statements
curl localhost:8998/sessions/5/statements -X POST -H 'Content-Type: application/json' -d '{"code":"a + 1"}'
{"id":2,"state":"available","output":{"status":"ok","execution_count":2,"data":{"text/plain":"11"}}}
Let's close the session to free up the cluster. Note that Livy will automatically inactive idle sessions after 1 hour (configurable).
curl localhost:8998/sessions/0 -X DELETE
{"msg":"deleted"}
Impersonation
Let's say we want to create a shell running as the user bob, this is particularly useful when multi users are sharing a Notebook server
curl -X POST -data '{"kind": "pyspark", "proxyUser": "bob"}' -H "Content-Type: application/json" localhost:8998/sessions
{"id":0,"state":"starting","kind":"pyspark","proxyUser":"bob","log":[]}
Do not forget to add the user running Hue (your current login in dev or hue in production) in the Hadoop proxy user list (/etc/hadoop/conf/core-site.xml):
hadoop.proxyuser.hue.hosts
*
hadoop.proxyuser.hue.groups
*
Additional properties
All the properties supported by spark shells like the number of executors, the memory, etc can be changed at session creation. Their format is the same as when typing spark-shell -h
curl -X POST -data '{"kind": "pyspark", "numExecutors": "3", "executorMemory": "2G"}' -H "Content-Type: application/json" localhost:8998/sessions
{"id":0,"state":"starting","kind":"pyspark","numExecutors":"3","executorMemory":"2G","log":[]}
And that's it! Next time we will explore some more advanced features like the magic keywords for introspecting data or printing images. Then, we will detail how to do batch submissions in compiled Scala, Java or Python (i.e. jar or py files).
The architecture of Livy was presented for the first time at Big Data Scala by the Bay last August and next updates will be at the Spark meetup before Strata NYC and Spark Summit in Amsterdam.
Feel free to ask any questions about the architecture, usage of the server in the comments, @gethue or the hue-user list. And pull requests are always welcomed!