Write and Execute some Spark SQL quickly in your own Web Editor.
Initially published on https://medium.com/data-querying/a-sparksql-editor-via-hue-and-the-spark-sql-server-f82e72bbdfc7
Apache Spark is popular for wrangling/preparing data, especially when embedding some SQL snippets to keep the data manipulation programs declarative and simpler.
One good news is that the SQL syntax is very similar to Apache Hive so the very powerful Hive autocomplete of Hue works very well.
Here we will describe how to integrate with the Spark SQL Thrift Server interface that might be already available in your stack.
The article comes with a One click demo setup. The scenario is pretty simple and about batch querying, we will see for more live data in a dedicated follow-up episode.
For fetching the Docker Compose configuration and starting everything:
mkdir spark
cd spark
wget https://raw.githubusercontent.com/romainr/query-demo/master/spark/docker-compose.yml
docker-compose up -d
>
Creating network "spark_default" with the default driver
Creating hue-database ... done
Creating livy-spark ... done
Creating spark-master ... done
Creating spark-sql ... done
Creating hue ... done
Then those URLs will be up:
- http://127.0.0.1:8080/ Spark Master Web UI
- http://127.0.0.1:4040/environment/ Thrift SQL UI
- http://127.0.0.1:7070 Spark Master
- http://localhost:8998 Livy REST Server
For stopping everything:
docker-compose down
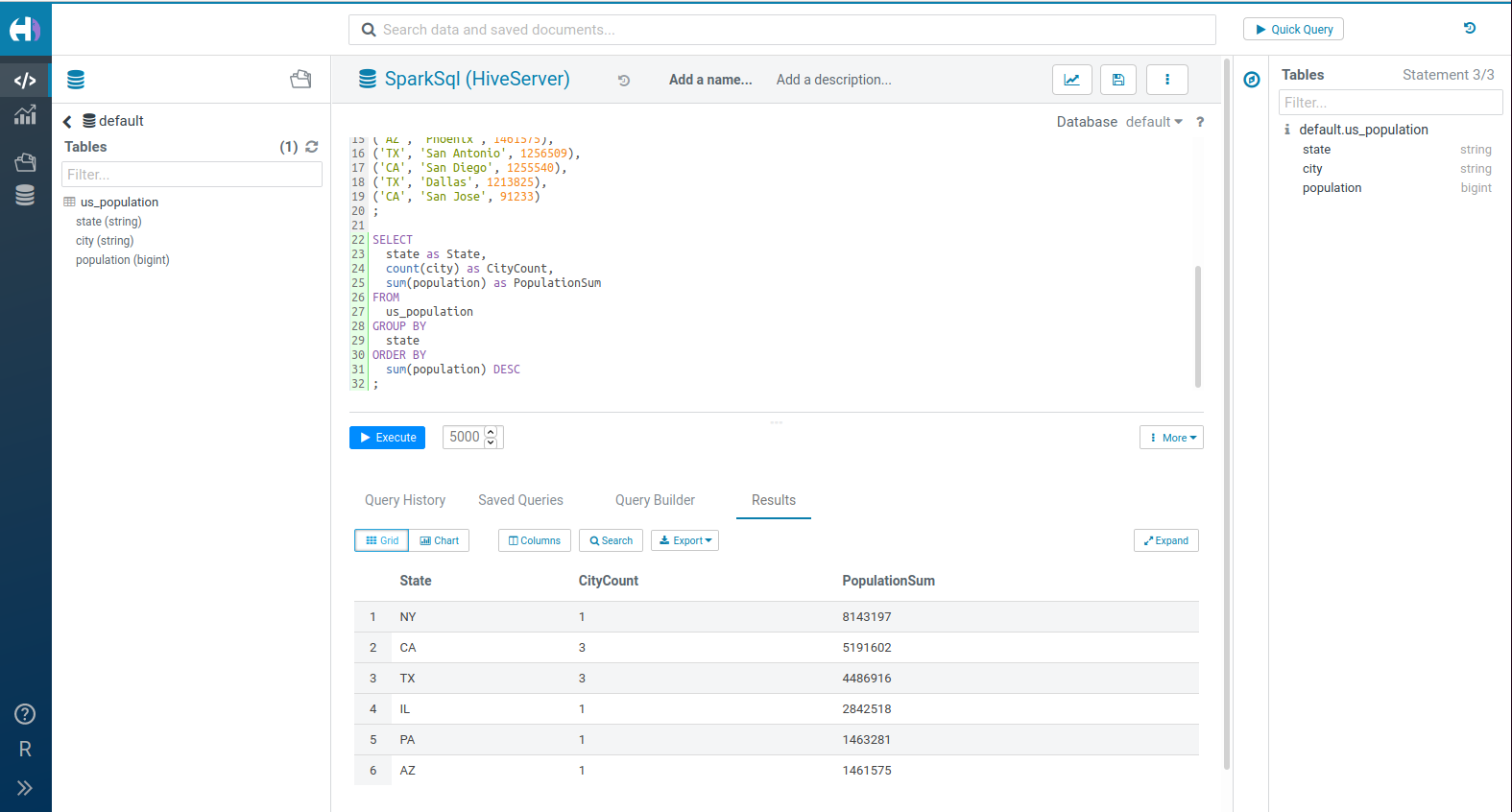
Hello World
How to create a SQL table representing some cities and number of inhabitants:
CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2),
city VARCHAR(20),
population BIGINT
)
;
INSERT INTO us_population
VALUES
('NY', 'New York', 8143197),
('CA', 'Los Angeles', 3844829),
('IL', 'Chicago', 2842518),
('TX', 'Houston', 2016582),
('PA', 'Philadelphia', 1463281),
('AZ', 'Phoenix', 1461575),
('TX', 'San Antonio', 1256509),
('CA', 'San Diego', 1255540),
('TX', 'Dallas', 1213825),
('CA', 'San Jose', 91233)
;
SELECT
state as State,
count(city) as CityCount,
sum(population) as PopulationSum
FROM
us_population
GROUP BY
state
ORDER BY
sum(population) DESC
;
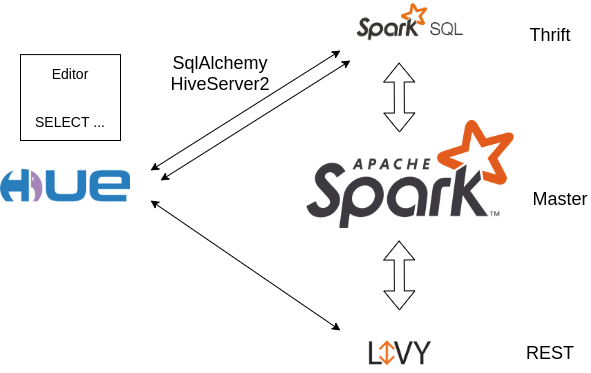
Which interface for connecting with the Spark SQL Server?
We previously demoed how to leverage Apache Livy to submit some Spark SQL via Hue. As detailed there, Livy was initially created within the Hue project and offers a lightweight submission of interactive or batch PySpark / Scala Spark /SparkSql statements.
However one main drawback is that it might appear less official than the Distributed SQL Engine (also known as “Thrift Server”) shipped within Spark.
Hue can connect to the Spark SQL Thrift Server via two interfaces:
- SqlAlchemy: connector based on the universal Python lib
- HiveServer2: Hue’s native connector for Hive
Long story short: the main advantage of SqlAlchemy is to be have more SparkSql nits ironed out but queries are submitted synchronously (i.e. queries of more than a few seconds don’t have progress report yet and long ones will time out, unless the Hue Task Server is setup).
So we recommend to get started with SqlAlchemy but help report/contribute back small fixes on the HiveServer2 API which is more native/advanced.
Note: SqlAlchemy interface requires the Hive connector which does not work out of the box because of the issue #150. But Hue ships and show a slightly patched module that works: https://github.com/gethue/PyHive
Configurations
In the hue.ini configure the connectors and make sure you installed the PyHive connector as shown in the docs:
[notebook]
[[interpreters]]
[[[sparksql-alchemy]]]
name=SparkSql (via SqlAlchemy)
interface=sqlalchemy
options='{"url": "hive://localhost:10000/default"}'
[[[sparksql]]]
# Must be named 'sparksql', hostname and more options are
# in the 'spark' section
name=SparkSql (via HiveServer2)
interface=hiveserver2
[spark]
sql_server_host=localhost
sql_server_port=10000
What’s next?
Et voila!
Next time we will describe the progress on the Hue SQL Scratchpad component that can be leveraged for easily editing and quick testing embedded SparkSql snippets as well as how to query live data.
Onwards!
Romain