Real time data querying is becoming a modern standard. Who wants to wait until the next day or week when needing to take decision now?
Apache Flink SQL is an engine now offering SQL on bounded/unbounded streams of data. The streams can come from various sources and here we picked the popular Apache Kafka.
This tutorial is based on the great Flink SQL demo Building an End-to-End Streaming Application but focuses on the end user querying experience.
Note Here is a follow-up post demoing how to do calculations on rolling logs windows via TUMBLE and INSERT them into another stream.
Components
To keep things simple, all the pieces have been put together in a “one-click” Docker Compose project which contains:
- Flink cluster from the Flink SQL demo
- The Flink SQL Gateway in order to be able to submit SQL queries via the Hue Editor. Previously explained in SQL Editor for Apache Flink SQL
- A Hue Editor already configured with the Flink Editor
We also bumped the Flink version from 1.11.0 to 1.11.1 as the SQL Gateway requires it. As Flink can query various sources (Kafka, MySql, Elastic Search), some additional connector dependencies have also been pre-installed in the images.
One-line setup
For fetching the configurations and starting everything:
mkdir stream-sql-demo
cd stream-sql-demo
wget https://raw.githubusercontent.com/romainr/query-demo/master/stream-sql-demo/docker-compose.yml
docker-compose up -d
>
Creating network "stream-sql-demo_default" with the default driver
Creating hue-database ... done
Creating stream-sql-demo_jobmanager_1 ... done
Creating stream-sql-demo_mysql_1 ... done
Creating ksqldb-server ... done
Creating stream-sql-demo_zookeeper_1 ... done
Creating flink-sql-api ... done
Creating stream-sql-demo_taskmanager_1 ... done
Creating hue ... done
Creating ksqldb-cli ... done
Creating stream-sql-demo_kafka_1 ... done
Creating stream-sql-demo_datagen_1 ... done
Then those URLs will be up:
- http://localhost:8888/ Hue Editor
- http://localhost:8081/ Flink Dashboard
As well as the Flink SQL Gateway:
curl localhost:8083/v1/info
> {"product_name":"Apache Flink","version":"1.11.1"}
For stopping everything:
docker-compose down
Query Experience
Notice that the Live SQL requires the New Editor which is in beta. In addition to soon offer multiple statements running at the same time on the same editor page and more robustness, it also bring the live result grid.
More improvements are on the way, in particular in the SQL autocomplete and Editor 2. In the future, the Task Server with Web Sockets will allow long running queries to run as separate tasks and prevent them from timing-out in the API server.
Note
In case you have an existing Hue Editor and want to point to the Flink, just activate it via this config change:
[desktop]
enable_hue_5=true
[[interpreters]]
[[[flink]]]
name=Flink
interface=flink
options='{"url": "http://localhost:8083"}'
Flink SQL
The Flink documentation as well as its community have a mine of information. Here are two examples to get started querying:
- A mocked stream of data
- Some real data going through a Kafka topic
Hello World
This type of table is handy, it will generates records automatically:
CREATE TABLE datagen (
f_sequence INT,
f_random INT,
f_random_str STRING,
ts AS localtimestamp,
WATERMARK FOR ts AS ts
) WITH (
'connector' = 'datagen',
'rows-per-second'='5',
'fields.f_sequence.kind'='sequence',
'fields.f_sequence.start'='1',
'fields.f_sequence.end'='1000',
'fields.f_random.min'='1',
'fields.f_random.max'='1000',
'fields.f_random_str.length'='10'
)
That can then be queried:
SELECT *
FROM datagen
LIMIT 50
Tumbling
One uniqueness of Flink is to offer SQL querying on windows of times or objects. The main scenario is then to Group the rolling blocks of records together and perform aggregations.
This is more realistic and coming from the FLink SQL demo. The stream of records is coming from the user_behavior Kafka topic:
CREATE TABLE user_behavior (
user_id BIGINT,
item_id BIGINT,
category_id BIGINT,
behavior STRING,
ts TIMESTAMP(3),
proctime AS PROCTIME(), -- generates processing-time attribute using computed column
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND -- defines watermark on ts column, marks ts as event-time attribute
) WITH (
'connector' = 'kafka', -- using kafka connector
'topic' = 'user_behavior', -- kafka topic
'scan.startup.mode' = 'earliest-offset', -- reading from the beginning
'properties.bootstrap.servers' = 'kafka:9094', -- kafka broker address
'format' = 'json' -- the data format is json
)
Poke at some raw records:
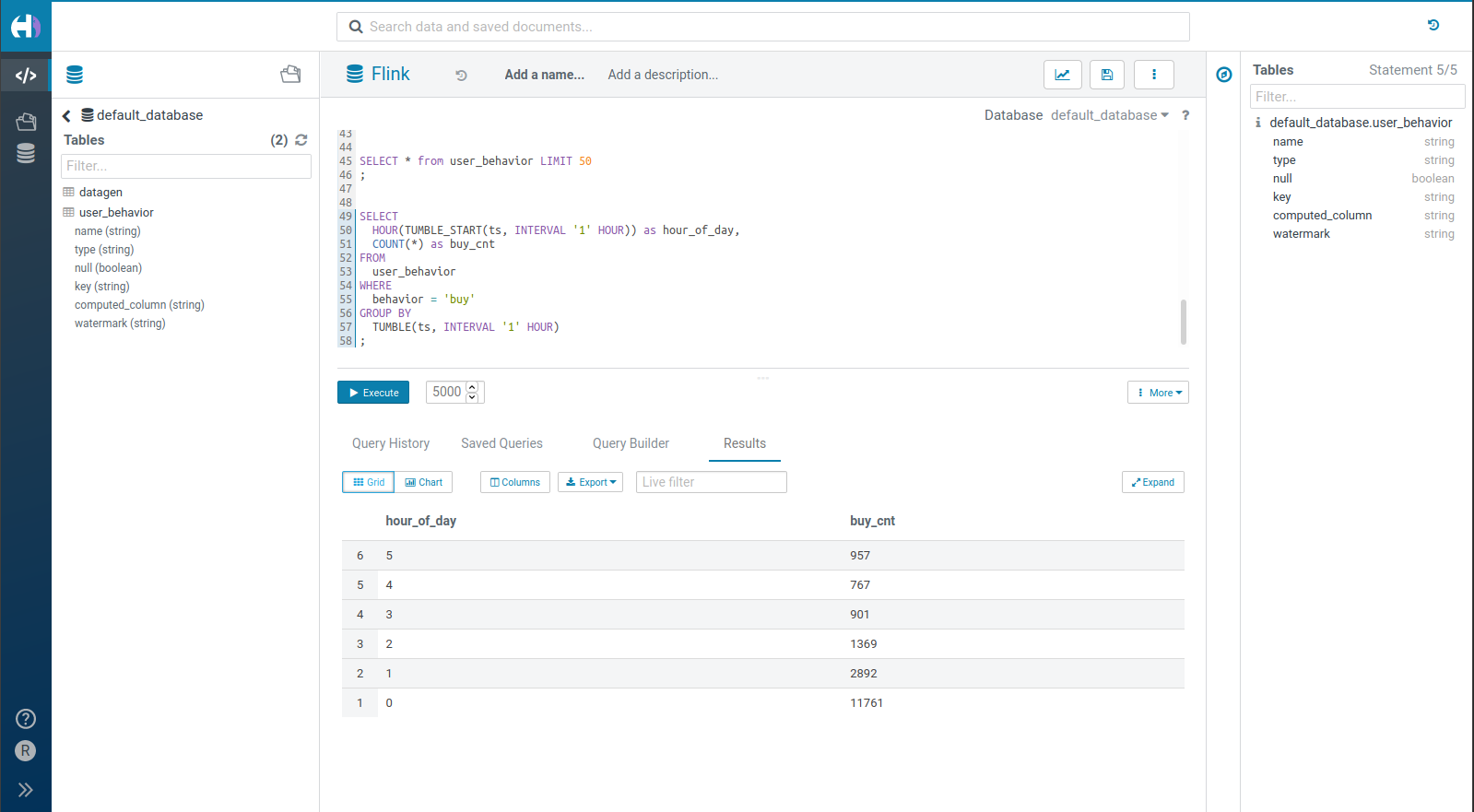
SELECT * from user_behavior LIMIT 50
Or perform a live count of the number of orders happening in each hour of the day:
SELECT
HOUR(TUMBLE_START(ts, INTERVAL '1' HOUR)) as hour_of_day,
COUNT(*) as buy_cnt
FROM
user_behavior
WHERE
behavior = 'buy'
GROUP BY
TUMBLE(ts, INTERVAL '1' HOUR)
In the next episodes, we will demo how to easily create tables directly from raw streams of data via the importer.
Any feedback or question? Feel free to comment here!
All these projects are also open source and welcome feedback and contributions. In the case of the Hue editor the Forum or Github issues are good places for that.
Onwards!
Romain