Hi Big Data Explorers,
The Hue Team is glad to thanks all the contributors and release Hue 4.4! ![]()
The focus of this release was to improve the self service SQL troubleshooting and stability.
This release comes with 450 commits and 80+ bug fixes! For all the changes, check out the release notes.
Go grab the tarball or source, and give it a spin! And for a quick try, ‘docker pull gethue/4.4.0’ or open-up demo.gethue.com.
Here is a list of the main improvements.
Easier Self Service Query Troubleshooting
Hue has great assistance for finding tables in the Data Catalog and getting recommendations on how to write (better) queries with the smart autocomplete, providing popular values and notifying of dangerous operations. When executing queries, however, it might be difficult to understand why they would be slow.
A new feature in 6.2 introduces a prettier display of the SQL Query Profile, which helps understand why/where the query bottlenecks are and how to optimize the query.
Example of how query plan displayed in the previous release:
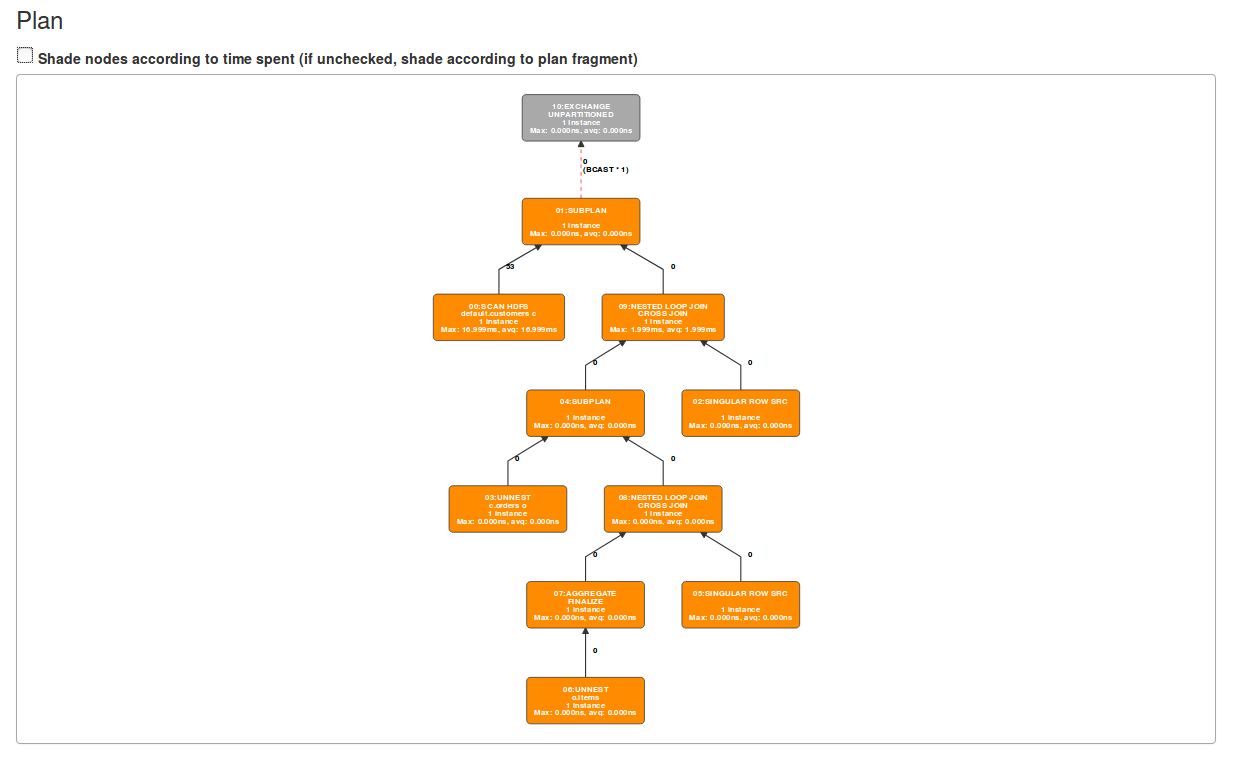
And what it looks like now:
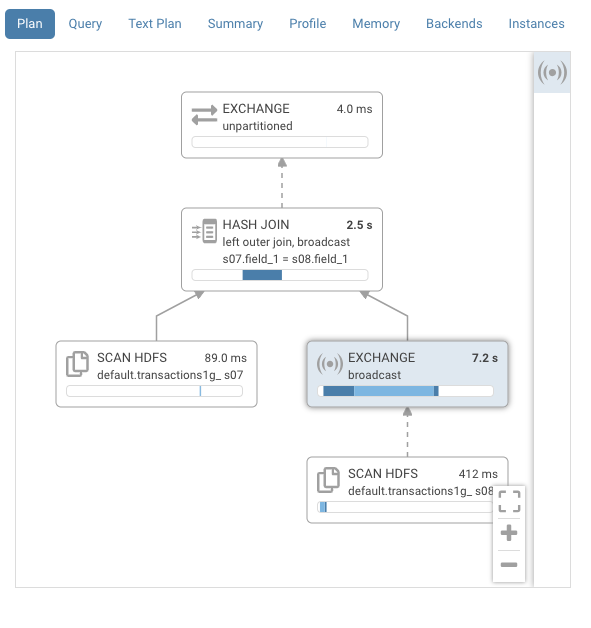
Note that on top of the much simpler visualization, tips are provided when available:
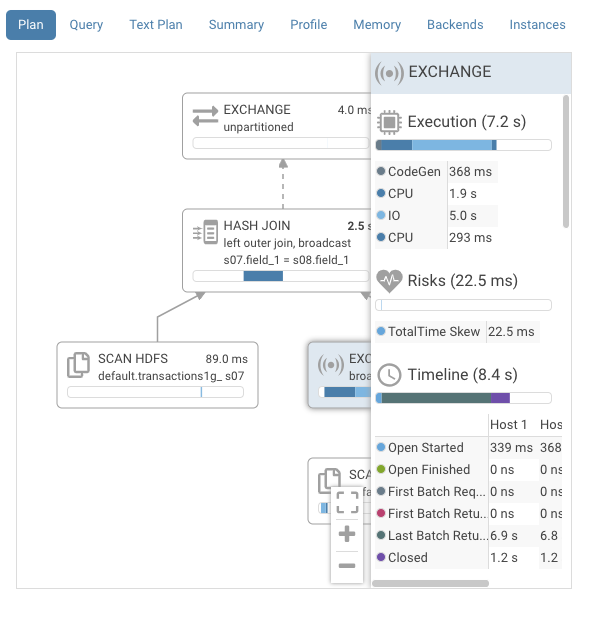
Please read more about this feature in this complete self-troubleshooting scenario.
Additionally, one of the most requested fixes was implemented: releasing query resources after the query has finished and they are no longer needed.
First, on the Apache Impala side, the query execution status will properly say if the query is actively running (“processing” data) or just “open but finished” (meaning just “keeping” the results but not using resources).
In addition, the new parameter NUM_ROWS_PRODUCED_LIMIT will even notify Impala to truncate any query execution as soon as this maximum number of result rows has been returned. This will release resources early on large SELECT operations where only the first few rows are actually displayed (which is the primary use case in Hue).
Better compatibility with Hive in HDP
Apache Hive has typically been very innovative in the Hortonworks distribution. In upstream the support for Hive on Tez and Hive LLAP was improved. Now:
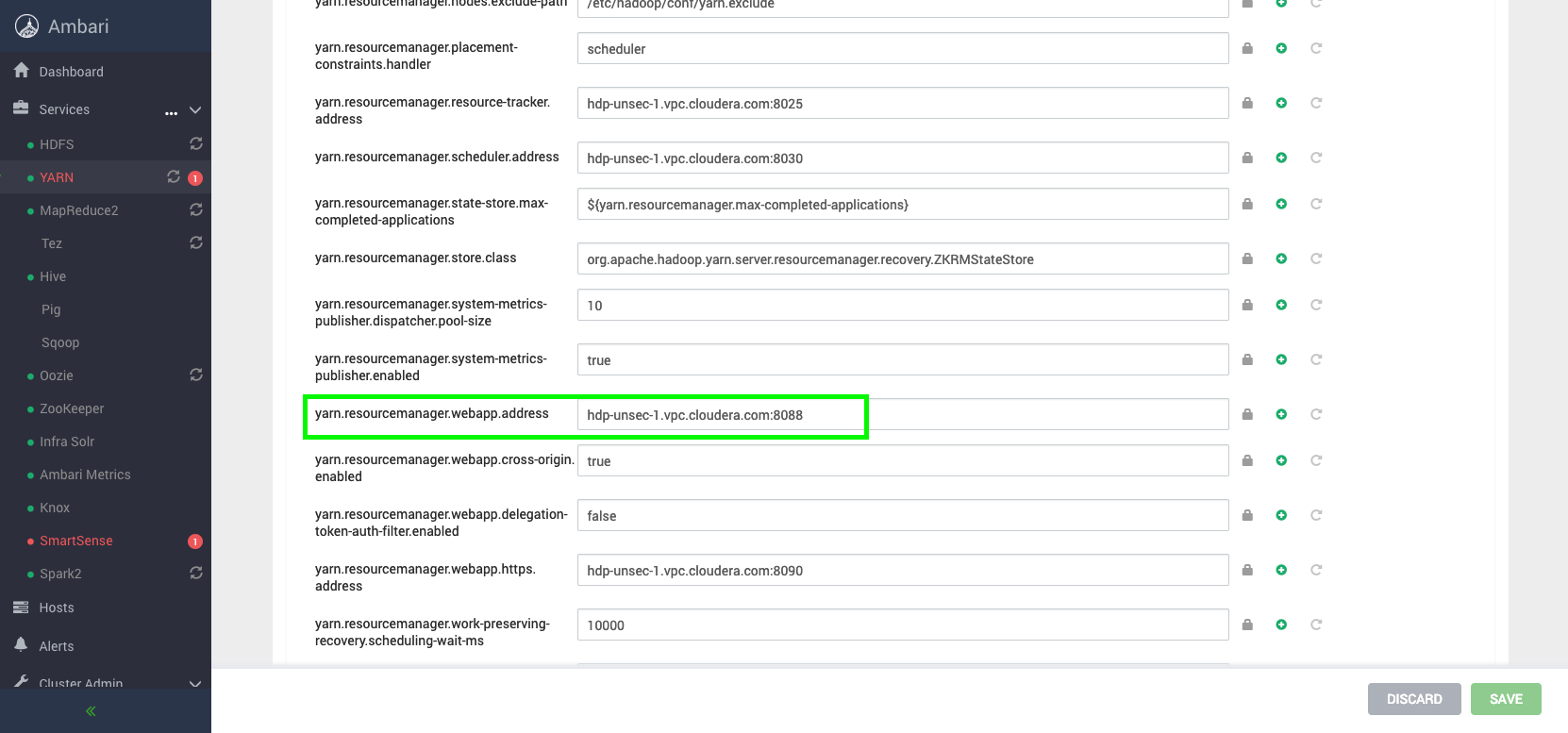
Note that currently Hue is not officially supported in HDP. However, if you want to experiment, you can learn how to configure Hue in HDP and set it up on your own, or get help from Cloudera Professional Services to do it for you.
Misc Improvements
More than 80 bugs were fixed to improve the supportability and stability of Hue. The full list is in the release notes but here are the top ones:
In addition, the Hue Docker image was simplified, so that it is easier to quickly get started and play/test the latest features.

Last but not least, the upstream and downstream documentation just got the first pass of a revamp, with a better table of contents, restyling, and updated instructions. In particular, on the upstream docs, reporting issues or sending a suggestion is one click away via GitHub, so feel free to send some pull requests!
Thank you to everybody using the product and who contributed to this release. Now off to the next one!
As usual thank you to all the project contributors and for sending feedback and participating on the hue-user list or @gethue!
Onwards!