|
ambari.localadmin
|
<td>
<div dir="ltr">
Ambari, Hue, Nagios, Ganglia
</div>
</td>
</tr>
<tr>
<td>
<div dir="ltr">
phd1.localadmin
</div>
</td>
<td>
<div dir="ltr">
HAWQ SMaster, NameNode, HiveServer2, Hive Metastore, ResourceManager, WebHCat Server, DataNode, HAWQ Segment, RegionServer, NodeManager, PXF
</div>
</td>
</tr>
<tr>
<td>
<div dir="ltr">
phd2.localadmin
</div>
</td>
<td>
<div dir="ltr">
App Timeline Server, History Server, HBase Master, Oozie Server, SNameNode, Zookeeper Server, DataNode, HAWQ Segment, RegionServer, NodeManager, PXF
</div>
</td>
</tr>
<tr>
<td>
<div dir="ltr">
phd3.localadmin
</div>
</td>
<td>
<div dir="ltr">
HAWQ Master, DataNode, HAWQ Segment, RegionServer, NodeManager, PXF
</div>
</td>
</tr>
</table>
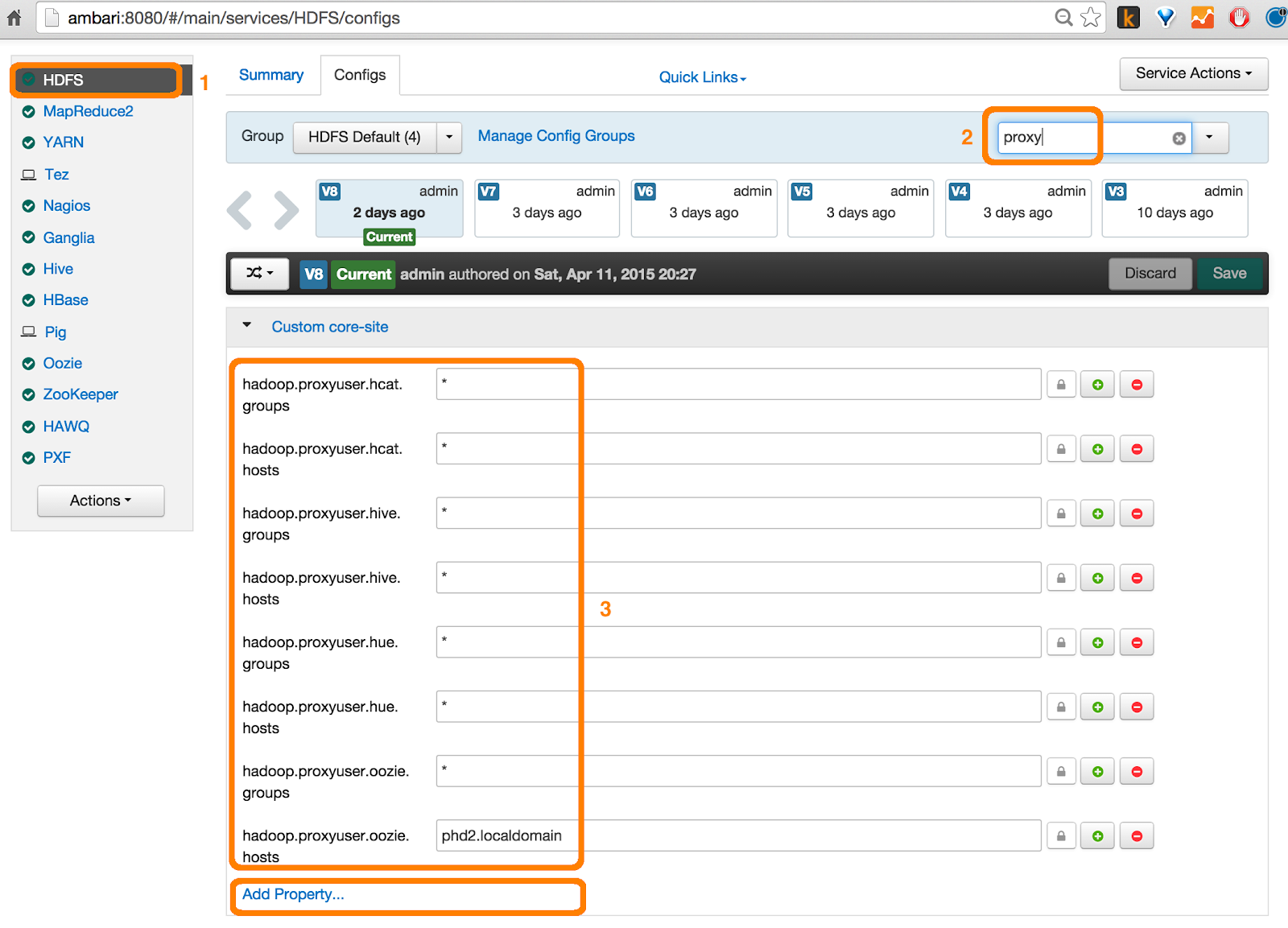
Only the modification from the the default hue configuration properties are listed below. Configuration is aligned with PHD3.0 cluster with the following topology:
###########################################################################
# General configuration for core Desktop features (authentication, etc)
###########################################################################
[desktop]
# Set this to a random string, the longer the better.
# This is used for secure hashing in the session store.
secret_key=bozanovakozagoza
# Time zone name
time_zone=Europe/Amsterdam
# Comma separated list of apps to not load at server startup.
# e.g.: pig,zookeeper
app_blacklist=impala,indexer
###########################################################################
# Settings for the RDBMS application
###########################################################################
[librdbms]
# The RDBMS app can have any number of databases configured in the databases
# section. A database is known by its section name
# (IE sqlite, mysql, psql, and oracle in the list below).
[[databases]]
# mysql, oracle, or postgresql configuration.
[[[postgresql]]]
# Name to show in the UI.
nice_name="HAWQ"
name=postgres
engine=postgresql
host=phd3.localdomain
port=5432
user=gpadmin
password=
###########################################################################
# Settings to configure your Hadoop cluster.
###########################################################################
[hadoop]
# Configuration for HDFS NameNode
# ------------------------
[[hdfs_clusters]]
[[[default]]]
# Enter the filesystem uri
fs_defaultfs=hdfs://phd1.localdomain:8020
# Use WebHdfs/HttpFs as the communication mechanism.
# Domain should be the NameNode or HttpFs host.
# Default port is 14000 for HttpFs.
webhdfs_url=http://phd1.localdomain:50070/webhdfs/v1
# Configuration for YARN (MR2)
# ------------------------
[[yarn_clusters]]
[[[default]]]
# Enter the host on which you are running the ResourceManager
resourcemanager_host=phd1.localdomain
# The port where the ResourceManager IPC listens on
resourcemanager_port=8030
# URL of the ResourceManager API
resourcemanager_api_url=http://phd1.localdomain:8088
# URL of the HistoryServer API
history_server_api_url=http://phd2.localdomain:19888
###########################################################################
# Settings to configure liboozie
###########################################################################
[liboozie]
# The URL where the Oozie service runs on. This is required in order for
# users to submit jobs. Empty value disables the config check.
oozie_url=http://phd2.localdomain:11000/oozie
###########################################################################
# Settings to configure Beeswax with Hive
###########################################################################
[beeswax]
# Host where HiveServer2 is running.
# If Kerberos security is enabled, use fully-qualified domain name (FQDN).
hive_server_host=phd1.localdomain
# Port where HiveServer2 Thrift server runs on.
hive_server_port=10000
# Choose whether Hue uses the GetLog() thrift call to retrieve Hive logs.
# If false, Hue will use the FetchResults() thrift call instead.
use_get_log_api=false
# Set a LIMIT clause when browsing a partitioned table.
# A positive value will be set as the LIMIT. If 0 or negative, do not set any limit.
browse_partitioned_table_limit=250
# A limit to the number of rows that can be downloaded from a query.
# A value of -1 means there will be no limit.
# A maximum of 65,000 is applied to XLS downloads.
download_row_limit=10000
# Thrift version to use when communicating with HiveServer2
thrift_version=5
###########################################################################
# Settings to configure the Zookeeper application.
###########################################################################
[zookeeper]
[[clusters]]
[[[default]]]
# Zookeeper ensemble. Comma separated list of Host/Port.
# e.g. localhost:2181,localhost:2182,localhost:2183
host_ports=phd2.localdomain:2181
# The URL of the REST contrib service (required for znode browsing)
rest_url=http://phd2.localdomain:9998
###########################################################################
# Settings to configure HBase Browser
###########################################################################
[hbase]
# Comma-separated list of HBase Thrift servers for clusters in the format of '(name|host:port)'.
# Use full hostname with security.
hbase_clusters=(Cluster|phd2.localdomain:9090)
Appendix B: RDBMS view doesn’t show tables workaround
<div dir="ltr">
Credits to Scott Kahler for this workaround!
</div>
<div dir="ltr">
<br class="kix-line-break" />Edit /usr/lib/hue/desktop/libs/librdbms/src/librdbms/server/postgresql_lib.py. Replace the cursor.execute() statements in the get_tables() and get_columns() methods as shown below
</div>
def get_tables(self, database, table_names=[]):
# Doesn’t use database and only retrieves tables for database currently in use.
cursor =self.connection.cursor()
#cursor.execute(“SELECT table_name FROM information_schema.tables WHERE table_schema=’%s'” % database)
cursor.execute(“SELECT table_name FROM information_schema.tables WHERE table_schema NOT IN (‘hawq_toolkit’,’information_schema’,’madlib’,’pg_aoseg’,’pg_bitmapindex’,’pg_catalog’,’pg_toast’)”)
self.connection.commit()
return[row[0]for row in cursor.fetchall()]
def get_columns(self, database, table):
cursor =self.connection.cursor()
#cursor.execute(“SELECT column_name FROM information_schema.columns WHERE table_schema=’%s’ and table_name=’%s'” % (database, table))
cursor.execute(“SELECT column_name FROM information_schema.columns WHERE table_name=’%s’ AND table_schema NOT IN (‘hawq_toolkit’,’information_schema’,’madlib’,’pg_aoseg’,’pg_bitmapindex’,’pg_catalog’,’pg_toast’)”% table)
self.connection.commit()
return[row[0]for row in cursor.fetchall()]
You can automate the update like this:
sudo sed -i “s/=’%s’\” % database/NOT IN (‘hawq_toolkit’,’information_schema’,’madlib’,’pg_aoseg’,’pg_bitmapindex’,’pg_catalog’,’pg_toast’)\”/g”/usr/lib/hue/desktop/libs/librdbms/src/librdbms/server/postgresql_lib.py
sudo sed -i “s/table_schema=’%s’ and table_name=’%s’\” % (database, table)/table_name=’%s’ AND table_schema NOT IN (‘hawq_toolkit’,’information_schema’,’madlib’,’pg_aoseg’,’pg_bitmapindex’,’pg_catalog’,’pg_toast’)\” % table/g”/usr/lib/hue/desktop/libs/librdbms/src/librdbms/server/postgresql_lib.py
Restart Hue
<div dir="ltr">
<p>
<pre><code class="bash">sudo /etc/init.d/hue restart</code></pre>
</p>
</div>
<h1 dir="ltr">
Related links:
</h1>
<div dir="ltr">
<a href="https://gethue.com/hadoop-hue-3-on-hdp-installation-tutorial/">https://gethue.com/hadoop-hue-3-on-hdp-installation-tutorial/</a>
</div>
26 June 2024
Integrating Trino Editor in Hue: Supporting Data Mesh and SQL Federation
Read More
03 May 2023
Discover the power of Apache Ozone using the Hue File Browser
Read More