Initially published on https://medium.com/data-querying/live-sql-querying-live-logs-and-sending-live-updates-easily-e6297150cf92
Log analysis tutorial from an Apache Kafka data stream via Flink SQL, ksqlDB & Hue Editor.
Real time queries on streams on data is a modern way to perform powerful analyses as demoed in the previous post. This time we will see a more personalized scenario by querying our own logs generated in the Web Query Editor.
First, thank you to the community for all the improvements on the open source projects mentioned below, with in particular Flink Version 1.12 and the SQL gateway as well as the Hue Editor.
The goal is to demo the current SQL capabilities and ease of use of interactively building queries on streams of data.
Querying a data log stream via Flink SQL and ksqlDB
Architecture
The article comes with a live demo setup so that you can play with the products easily locally.
Raw logs from the Hue Editor..
[29/Dec/2020 22:43:21 -0800] access INFO 172.21.0.1 romain - "POST /notebook/api/get_logs HTTP/1.1" returned in 30ms 200 81
.. are being collected via Fluentd, which forwards them directly to a Kafka topic after filtering out the non access/INFO rows (to keep the data simpler).
{"container_id":"7d4fa988b26e2034670bbe8df3f1d0745cd30fc9645c19d35e8004e7fcf8c71d","container_name":"/hue","source":"stdout","log":"[29/Dec/2020 22:43:21 -0800] access INFO 172.21.0.1 romain - \"POST /notebook/api/get_logs HTTP/1.1\" returned in 30ms 200 81"}
This data is then picked from the Kafka topic, then analyzed interactively before being turned into a long running query calculating how many API calls per logged-in user are being made within rolling windows of 10 seconds.
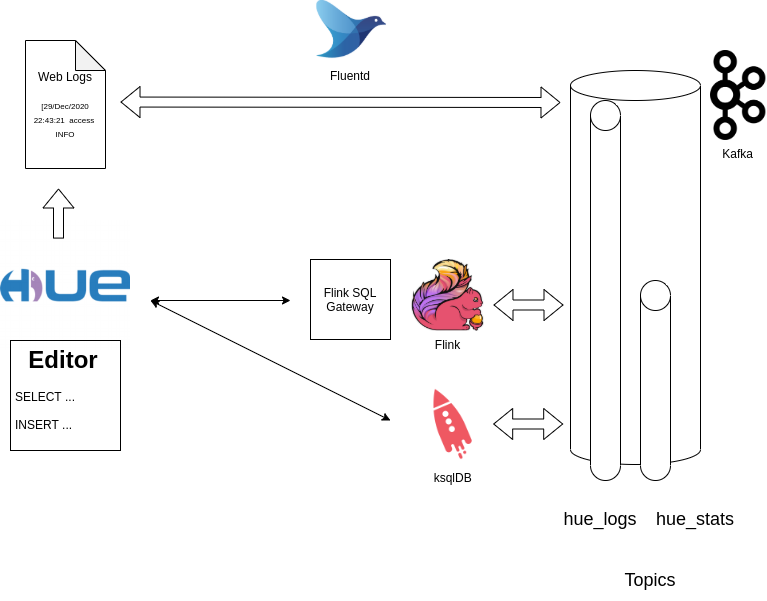
Live stream analysis Architecture
Demo
For fetching the Docker Compose configuration and starting everything:
mkdir stream-sql-logs
cd stream-sql-logs
wget https://raw.githubusercontent.com/romainr/query-demo/master/stream-sql-logs/docker-compose.yml
docker-compose up -d
>
Creating network "stream-sql-logs_default" with the default driver
Creating hue-database ... done
Creating stream-sql-logs_jobmanager_1 ... done
Creating stream-sql-logs_fluentd_1 ... done
Creating stream-sql-logs_zookeeper_1 ... done
Creating ksqldb-server ... done
Creating hue ... done
Creating stream-sql-logs_taskmanager_1 ... done
Creating flink-sql-api ... done
Creating stream-sql-logs_kafka_1 ... done
Then those URLs will be up:
- http://localhost:8888/ Hue Editor
- http://localhost:8081/ Flink Dashboard
For stopping everything:
docker-compose down
Scenario
While interacting with the Web Editor, Web logs are being generated. We will ingest a subset of them into a Kafka Topic that we will query via Flink SQL. ksqlDB is used to prove that at the end of the day all the SQL SELECTs and INSERTs are purely going through standard Kafka topics.
Once again, the TUMBLE function is used to easily create live windows of aggregation.
We logged-in as two separate users (‘demo’ and ‘romain’) to show the grouping by username.
One of the novelty in Flink is the new UPSERT into Kafka connector, which will let us send the rolling aggregated data back into Kafka. This enables further downwards consumption by reporting or alerting systems which can simply read from the topic.
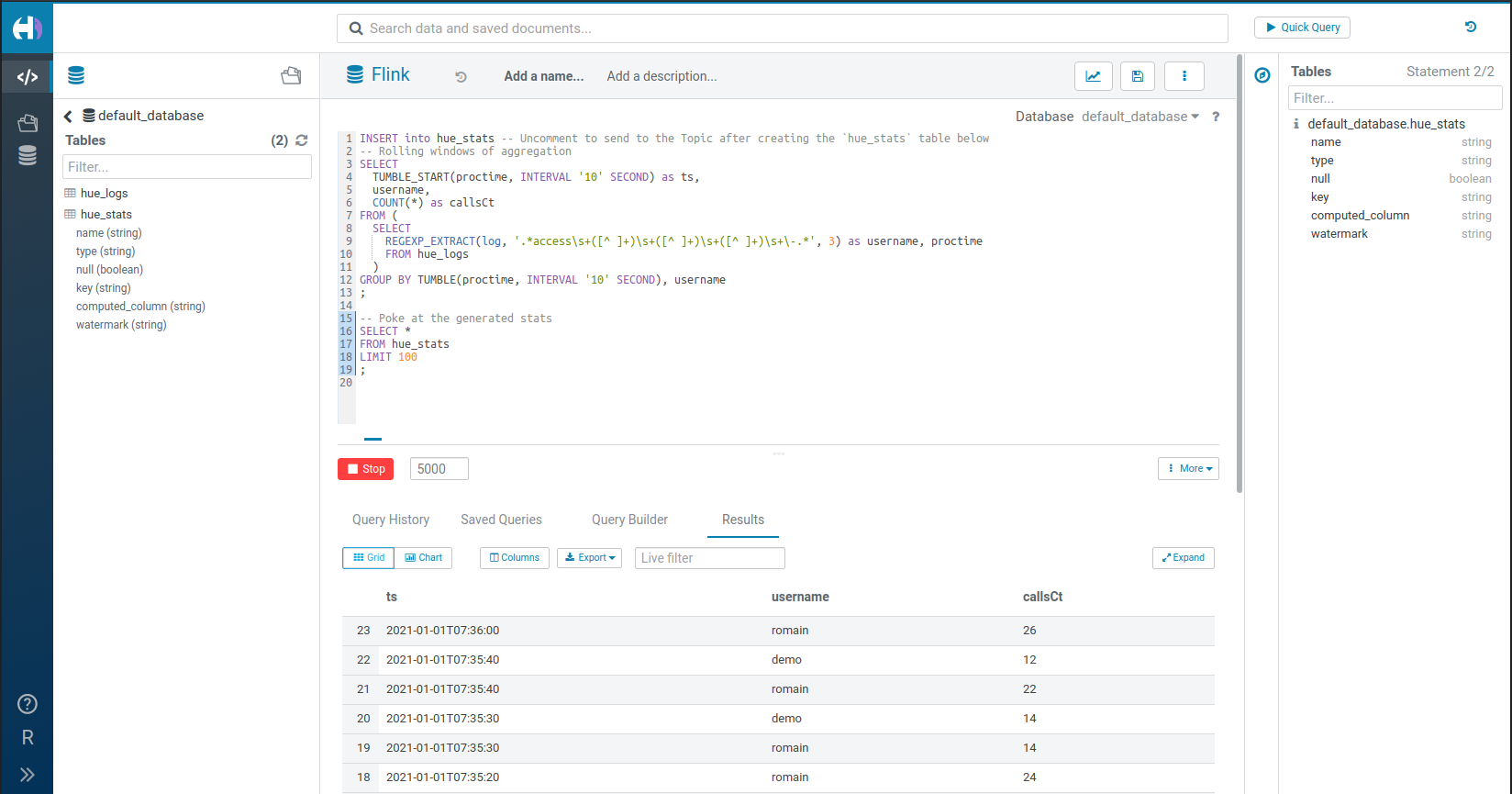 Calculating and inserting a rolling window of live stats into a Kafka Topic
Calculating and inserting a rolling window of live stats into a Kafka Topic
As a follow-up, the querying could be more elaborate via the extraction of the real datetime and HTTP code fields as well as outputting alert messages when the counts go above/below a certain threshold, which is perfect for building a live application on top of it.
One of niceties of the editor is to let you interactively fiddle with SQL functions like REGEXP_EXTRACT, DATE_FORMAT… which can be time consuming to get right.
SQL
Here is the SQL source typed in the Query Editor:
Et voila!
Any feedback or question? Feel free to comment here!
All these projects are also open source and welcome feedback and contributions.
In the case of the Hue Editor, the Forum or Github issues are good places for that. More sophisticated SQL autocompletes and connectors, Web Socket and Celery Task server integrations are some improvement ideas.
Onwards!
Romain