Overview of Iceberg
Apache Iceberg is a high-performance format for huge analytic tables. Iceberg brings the reliability and simplicity of SQL tables to big data, while making it possible for engines like Spark, Trino, Flink, Presto, Hive and Impala to safely work with the same tables, at the same time.
Hue supports various dialects such as Hive, Impala, SparkSQL, Phoenix, and so on. In the past year, Hue importer has been upgraded with new features and improvements. You can import local files, drag and drop files into the Hue importer, create Phoenix tables, and create tables from excel files for these dialects in a few clicks. You just need to load the data and submit it. In this release, Hue supports creating Iceberg tables in Hive, and Impala dialects.
Steps
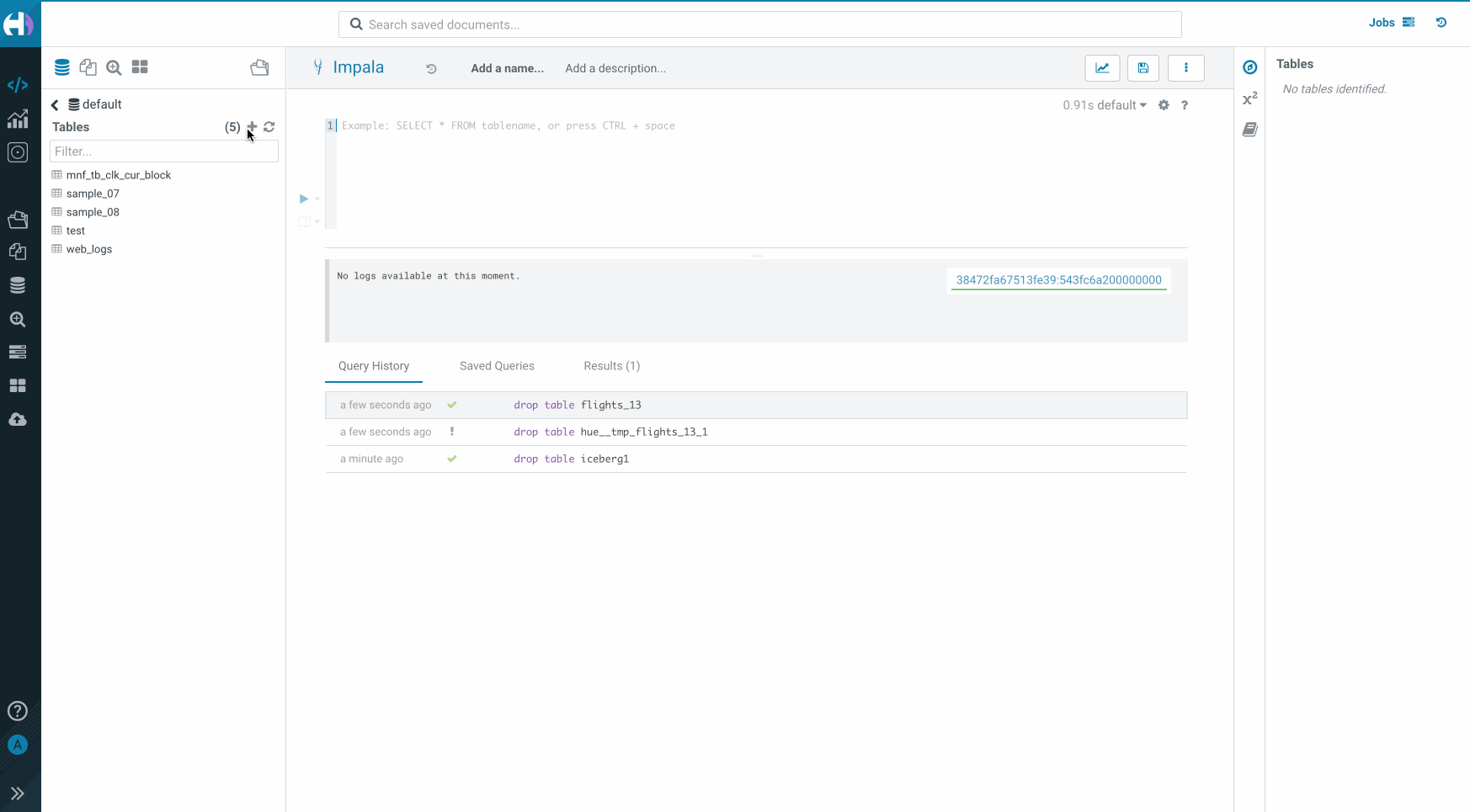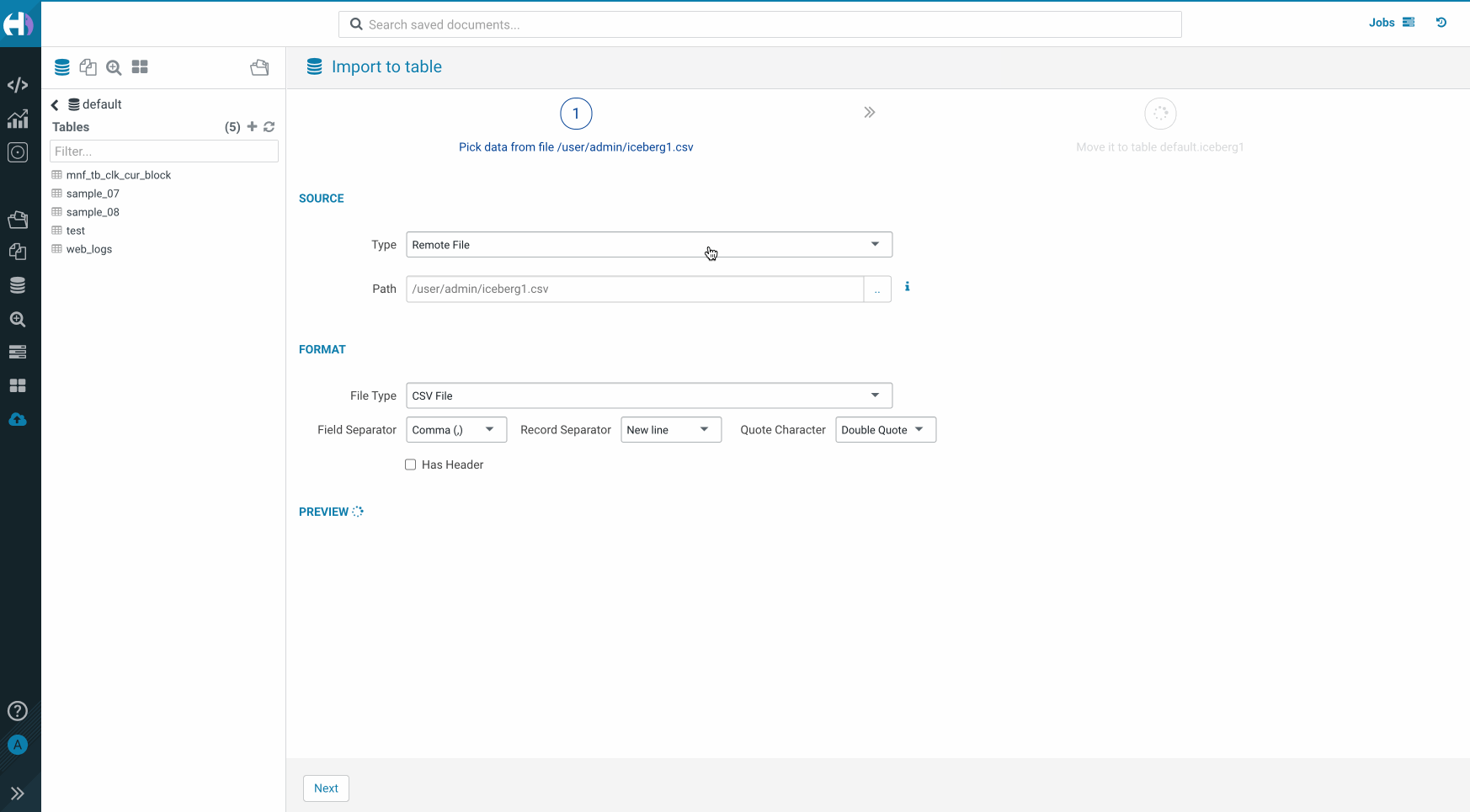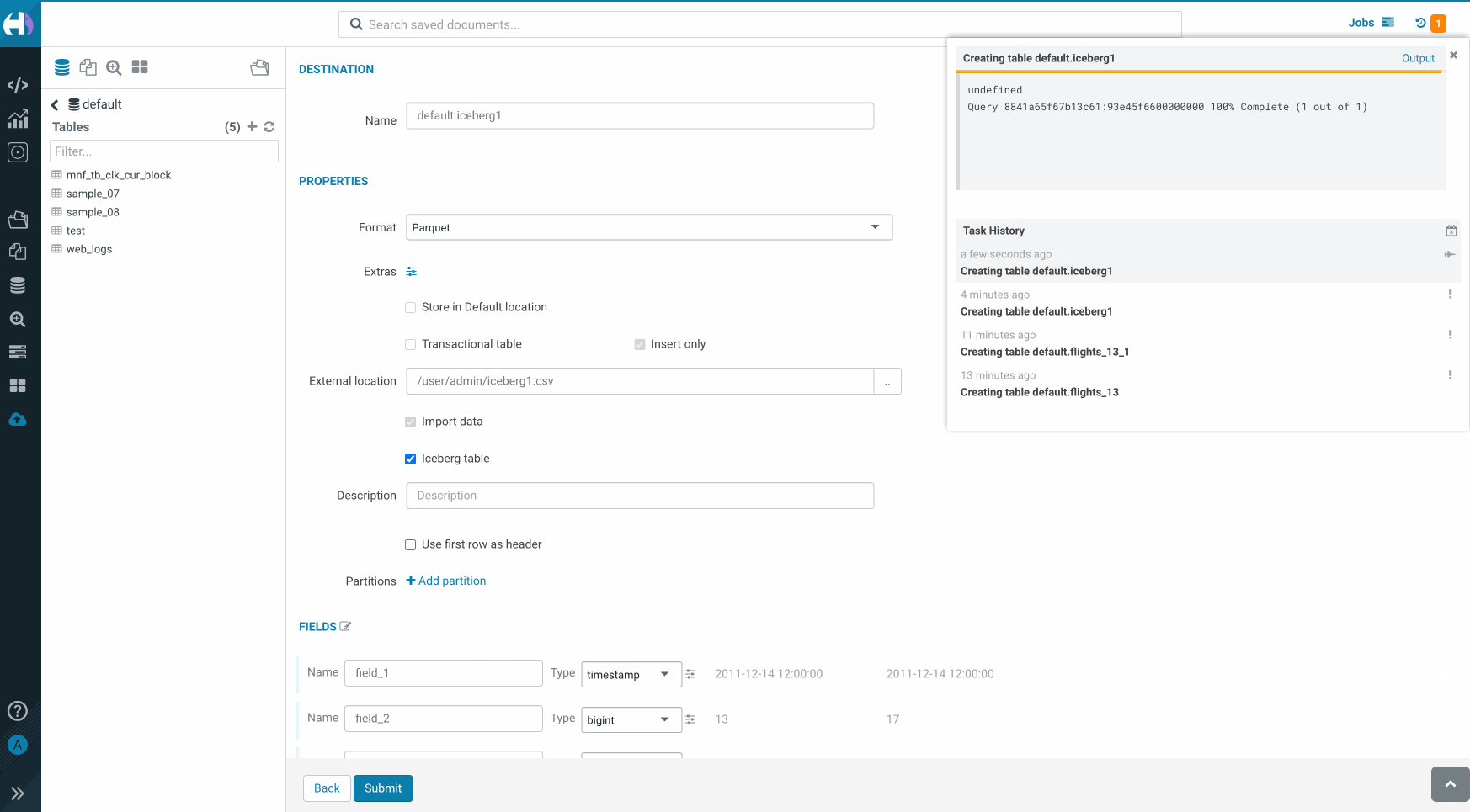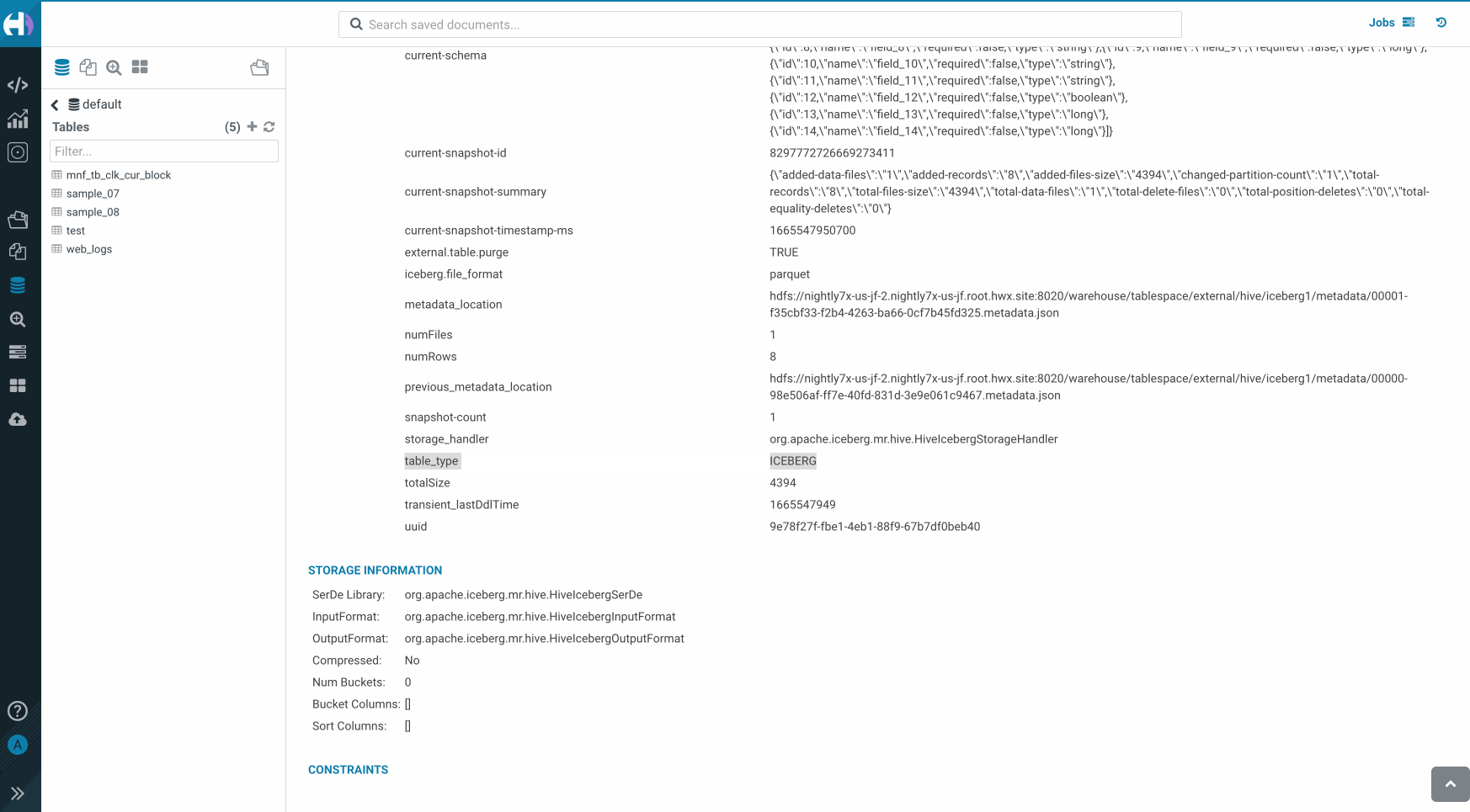
- Go to the Hue importer and select Remote file from drop down menu.
- Select a file from which you want to create a table.
- Click Next and select the Iceberg table option.
- Configure the column types and tweak other parameters as needed.
- Click Submit.
You can try this feature in the latest Hue version.
For feedback, questions, or suggestions, feel free to comment here or on the Forum or on the Discussion and quick start SQL querying!
Onwards!
Ayush from the Hue Team