Using AWS S3 Signed URLs to list buckets, keys and manage files.
SQL querying opens up your data and helps users take decisions backed by hard facts. However, what if the data they need is not present already in the Data Warehouse?
In order to provide a more self service experience, they could bring their own data to query or join, then export and share the query results files etc.
Here is a real life scenario where signed URLs have been introduced in the Hue Editor project.
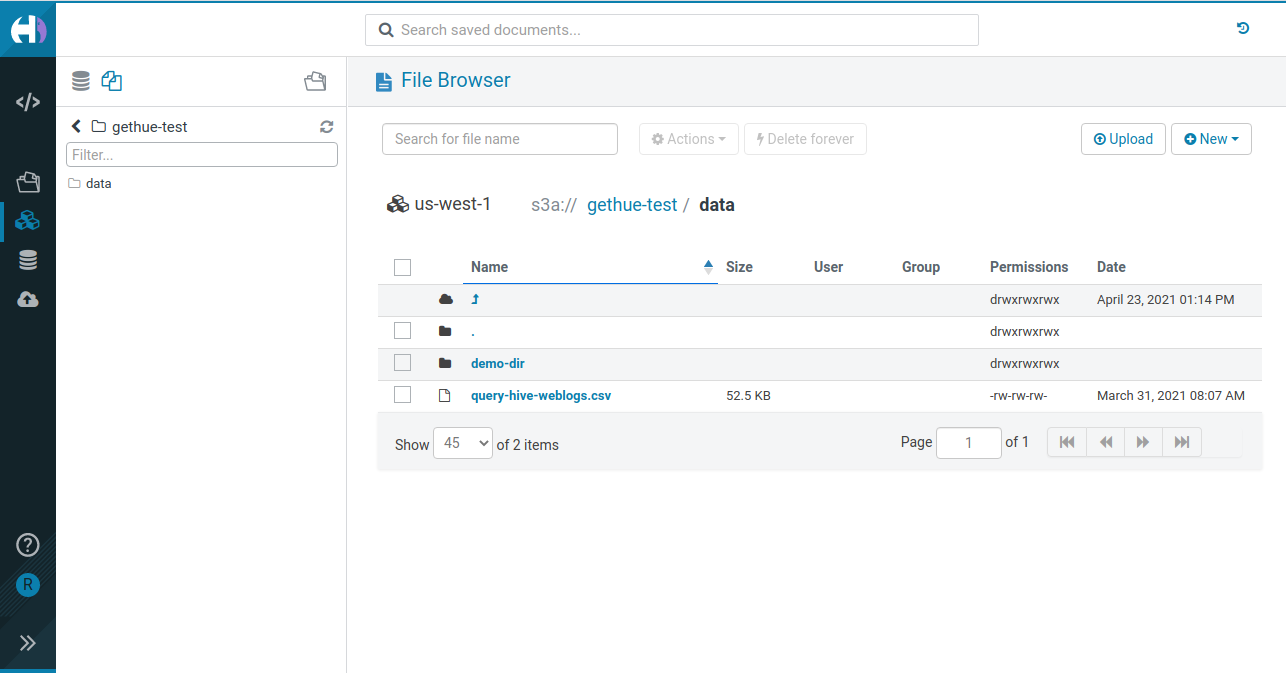
Same and consistent File Browsing interface be it for HDFS, S3, ADLS in Hue
The Hue SQL Editor has been providing transparent access to the Cloud storages since the early days via its File Browser. It is a quite popular app as otherwise giving direct access to the native S3 or ADLS Web UI is clunky and not Cloud agnostic (also the interfaces are not designed for simplicity and non engineers). Moreover, most of the SQL users are used to the HDFS Browser which looks the same.
However, this usually creates some headache to the cluster administrators as the need to provide a set of S3 credential keys to the Hue Server and have them being shared by everyone. Not very safe. Allowing the File Browser to only admin will then restrict the functionality and we get back to square one.
This is when S3 Signed URLs come into the picture and help fix this cumbersomeness:
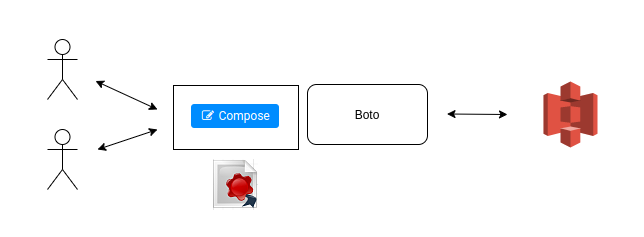
Users interacting with S3 via Hue and a shared credential key (not the best)
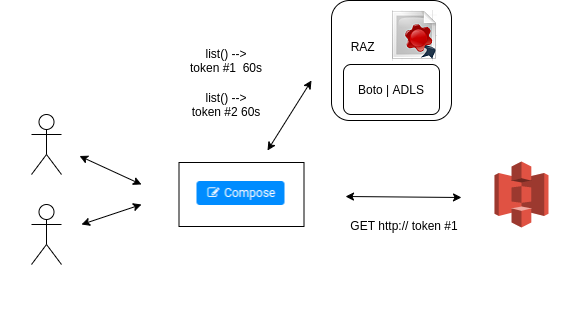
Users getting individual temporary URLs letting them access any S3 resources (safe and fine grain access possible)
Those URLs are usually set to expire (e.g. after 5 minutes) and are “signed”, meaning safe to provide publicly to the users as they can’t modify them without rendering them automatically invalid.
Another benefit is that the Hue Web Server does not need to have any S3 credentials. Hue just asks in this example to a RAZ Server to provide the equivalent URLs for the S3 calls a user wants to make.
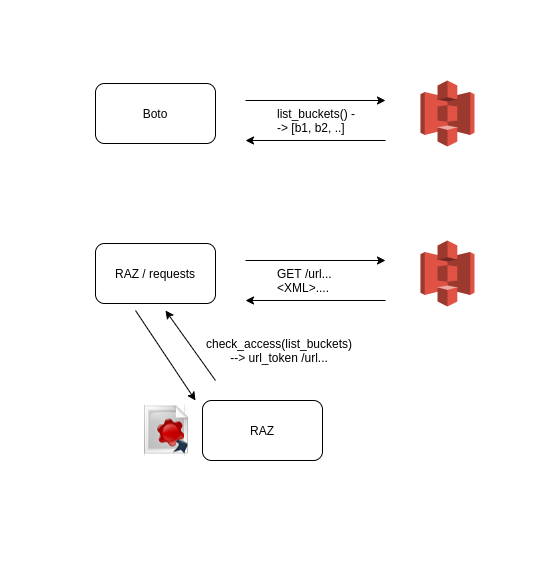
Before (on top), we directly use the AWS Python SDK to call and get a list of buckets, we get back Python objects representing a bucket each. After (bottom), we ask for a special URL and perform HTTP requests directly to S3 without additional authentication, and get back XML data.
This section describes the internal implementation and targets more developers.

Native (Boto) and URL Signed (RAZ) access path in finer details. Most important is to see that the Boto S3 classes need to be overriden to ask or generate a signed URL and do an HTTP call with them instead of getting it all done by the Boto library. There is no more S3 credendials keys and the S3 Connection object is never used (even set to None to guarantee it).
One of the magic piece is the RAZ server, which can convert a S3 call into a signed URL. RAZ is also leveraging Apache Ranger which provides authorization and fine grain permissions (i.e. who can access this bucket? who can upload a file in this directory?)
RAZ is not open source, but the underlying logic of the URL generation is similar to below.
Here are some snippets of code demoing how a call like ‘list buckets’ can be replaced by a Signed S3 URL:
- Boto3: create_presigned_url()
- Boto2: generate_url(), e.g. connection.generate_url(3600, ‘GET’)
And then how to call it and unmarshal back the XML to Python objects:
import boto
import xml.sax
import requests
from boto.resultset import ResultSet
from boto.s3.bucket import Bucket
tmp_url = 'https://s3-us-west-1.amazonaws.com/?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA23E77ZX2HVY76YGL%2F20210422%2Fus-west-1%2Fs3%2Faws4_request&X-Amz-Date=20210422T213700Z&X-Amz-Expires=3600&X-Amz-SignedHeaders=host&X-Amz-Signature=2efc90228ec9255636de27dab661e071a931f0aea7b51a09027f4747d0a78f6e'
response = requests.get(tmp_url)
print(response)
rs = ResultSet([('Bucket', Bucket)])
h = boto.handler.XmlHandler(rs, None)
xml.sax.parseString(response.content, h)
print(rs)
print([k for k in rs[0].list(prefix='data/')])
Which will print the same buckets objects as if we were using native Boto:
> <Response [200]>
[<Bucket: demo-gethue>, <Bucket: gethue-test>]
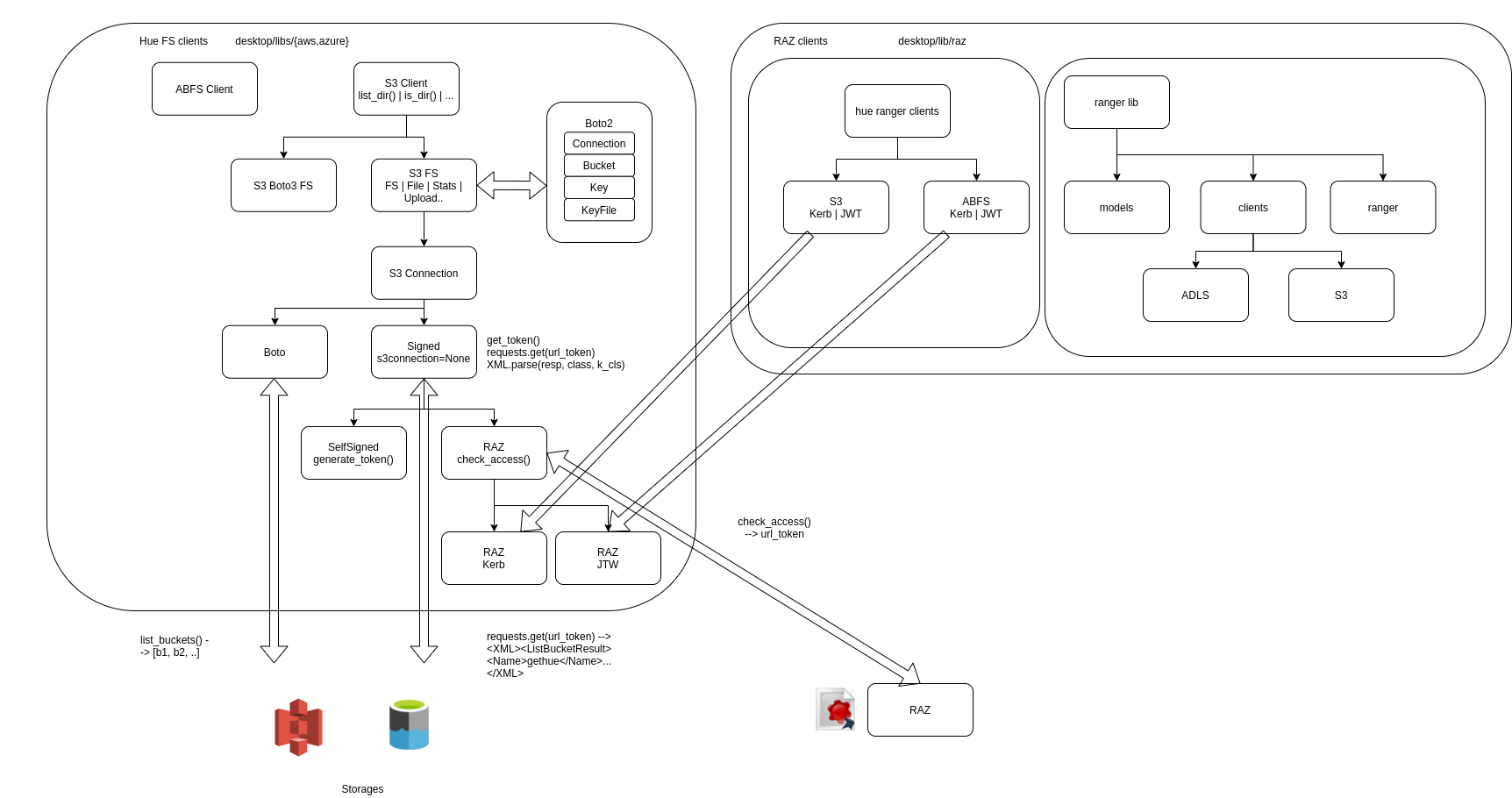 Big picture: mainly on the left side we see the Hue File System lib, which is generic enough to provide File Browsing for any storage system (HDFS, S3 native, S3 via Signed URLs, ADLS…). On the right, this is about how to build clients that can interact with services that can generate signed URLs for each call
Big picture: mainly on the left side we see the Hue File System lib, which is generic enough to provide File Browsing for any storage system (HDFS, S3 native, S3 via Signed URLs, ADLS…). On the right, this is about how to build clients that can interact with services that can generate signed URLs for each call
Yes, it looks complicated but at least one piece on how to provide true Self Service Querying in the Cloud world should be demystified :)
Hue is open source and this feature is expected to land in the next 4.10 release.
In the meantime, happy Data Querying to all!
Romain from the Hue Team