Dans ce tutoriel, nous utilisons les données publiques de Bay Area BikeShare afin de visualiser les déplacements en vélo des utilisateurs et ainsi mieux comprendre l'utilisation de la plate-forme. Nous utiliserons Hue qui fournit un tableau de bord dynamique pour chercher ainsi que son nouveau Spark Notebook pour enrichir les données.
Nous vous recommandons de commencer avec le jeu de données http://www.bayareabikeshare.com/datachallenge mais pour les gens impatients, nous fournir un sous-ensemble des voyages prêts à être indexées ainsi que les données météorologiques à traiter plus tard avec Spark. Le Notebook peut être téléchargé et importé ou tout simplement copie collé depuis ici.
Cette démo combinée avec la présentation en temps réel en streaming Spark ont été présentés à des conférences comme Hadoop Summit et Big Data Day LA .
Bon Vélo!
Video en Anglais, avec un accent Francais 😉
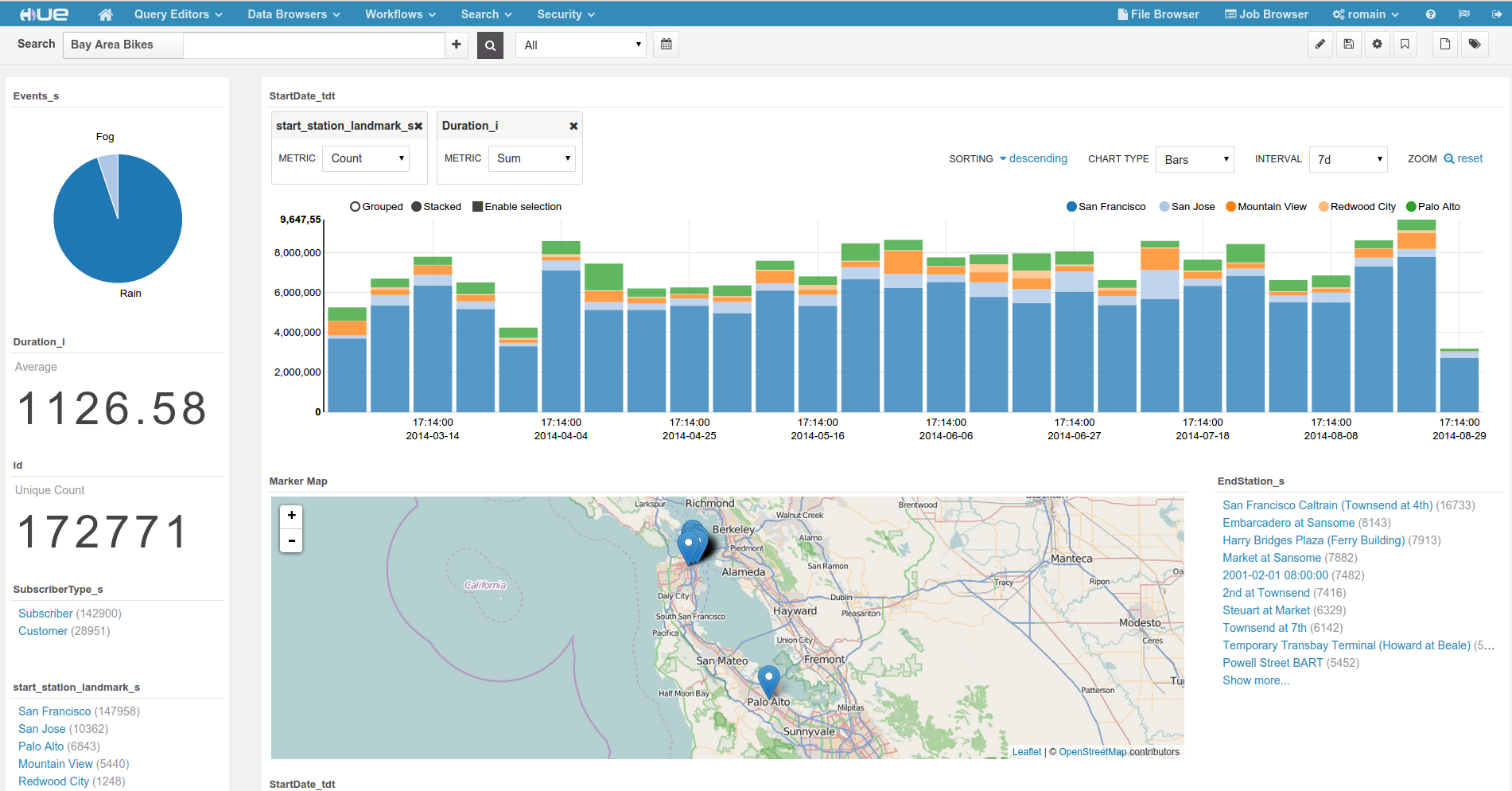
Comme d'habitude hésitez pas à commenter sur la liste utilisateur ou @gethue !
Conseil
Un moyen rapide pour indexer les données avec Solr:
bin/solr create_collection -c bikes
URL=http://localhost:8983/solr
u="$URL/bikes/update?commitWithin=5000"
curl $u -data-binary @/home/test/index_data.csv -H 'Content-type:text/csv'