Hue 3.8 brings a new way to directly submit Spark jobs from a Web UI.
Last year we released Spark Igniter to enable developers to submit Spark jobs through a Web Interface. While this approach worked, the UX left a lot to be desired. Programs had to implement an interface, be compiled beforehand and YARN support was lacking. We also wanted to add support for Python and Scala, focusing on delivering an interactive and iterative programming experience similar to using a REPL.
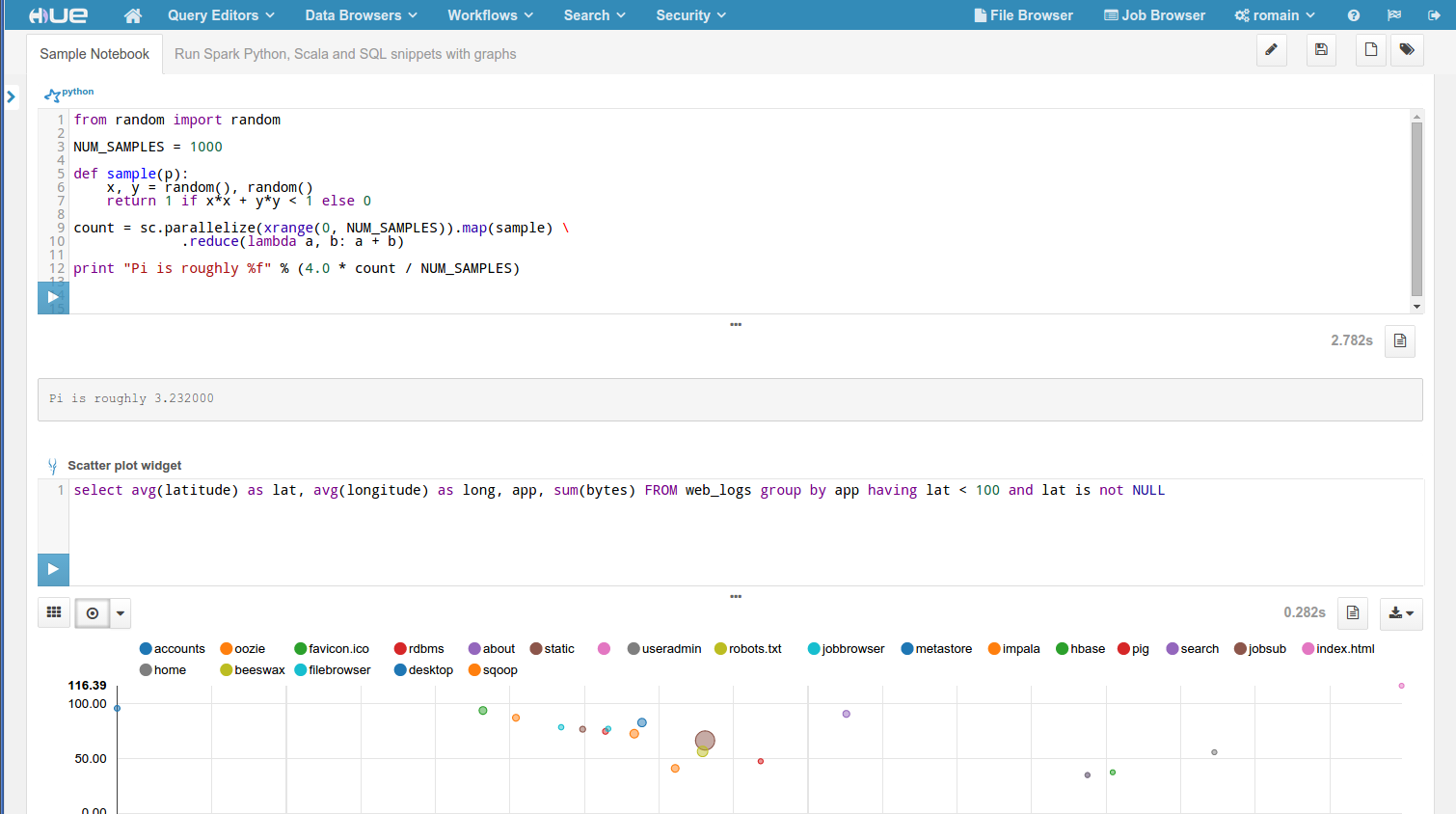
This is for this that we started developing a new Spark REST Job Server that could provide these missing functionalities. On top of it, we revamped the UI for providing a Python Notebook-like feeling.
Note that this new application is pretty new and labeled as ‘Beta’. This means we recommend trying it out and contributing, but its usage is not officially supported yet as the UX is going to evolve a lot!
This post describes the Web Application part. We are using Spark 1.3 and Hue master branch.
Based on a new:
- Spark REST Job Server
- Notebook Web UI
Supports:
- Scala
- Python
- Java
- SQL
- YARN
If the Spark app is not visible in the ‘Editor’ menu, you will need to unblacklist it from the hue.ini:
[desktop]
app_blacklist=
Note: To override a value in Cloudera Manager, you need to enter verbatim each mini section from below into the Hue Safety Valve: Hue Service → Configuration → Service-Wide → Advanced → Hue Service Advanced Configuration Snippet (Safety Valve) for hue_safety_valve.ini
On the same machine as Hue, go in the Hue home:
If using the package installed:
cd /usr/lib/hue
Recommended
Use Livy Spark Job Server from the Hue master repository instead of CDH (it is currently much more advanced): see build & start the latest Livy
If not, use Cloudera Manager:
cd /opt/cloudera/parcels/CDH/lib/
HUE_CONF_DIR=/var/run/cloudera-scm-agent/process/-hue-HUE_SERVER-#
echo $HUE_CONF_DIR
export HUE_CONF_DIR
Then cd to hue directory And start the Spark Job Server from the Hue home:
./build/env/bin/hue livy_server
You can customize the setup by modifying these properties in the hue.ini:
[spark]
\# URL of the REST Spark Job Server.
server_url=http://localhost:8090/
\# List of available types of snippets
languages='[{"name": "Scala", "type": "scala"},{"name": "Python", "type": "python"},{"name": "Impala SQL", "type": "impala"},{"name": "Hive SQL", "type": "hive"},{"name": "Text", "type": "text"}]'
\# Uncomment to use the YARN mode
\## livy_server_session_kind=yarn
Next
This Beta version brings a good set of features, a lot more is on the way. In the long term, we expect all the query editors (e.g. Pig, DBquery, Phoenix…) to use this common interface. Later, individual snippets could be drag & dropped for making visual dashboards, notebooks could be embedded like in Dropbox or Google docs.
We are also interested in getting feedback on the new Spark REST Job Server and see what the community thinks about it (contributions are welcomed ;).
As usual feel free to comment on the hue-user list or @gethue!