Aloha Big Questions Askers!
The SQL Editor in Hue 3.11 brings a completely re-written result grid that improves the performances allowing big tables to be displayed without the browser to crash, plus some nifty tools for you.
You can now lock some rows: this will help you compare data with other rows. When you hover a row id, you get a new lock icon. If you click on it, the row automatically sticks to the top of the table.
The column list follows the result grid, can be filtered by data type and can be resized (finally!)
The headers of fields with really long content will follow your scroll position and always be visible
You can now search in the table and the results are highlighted
You can activate the new search either by clicking on the magnifier icon on the results tab, or pressing Ctrl/Cmd + F
The virtual renderer display just the cells you need at that moment
The table you see here has hundreds of columns
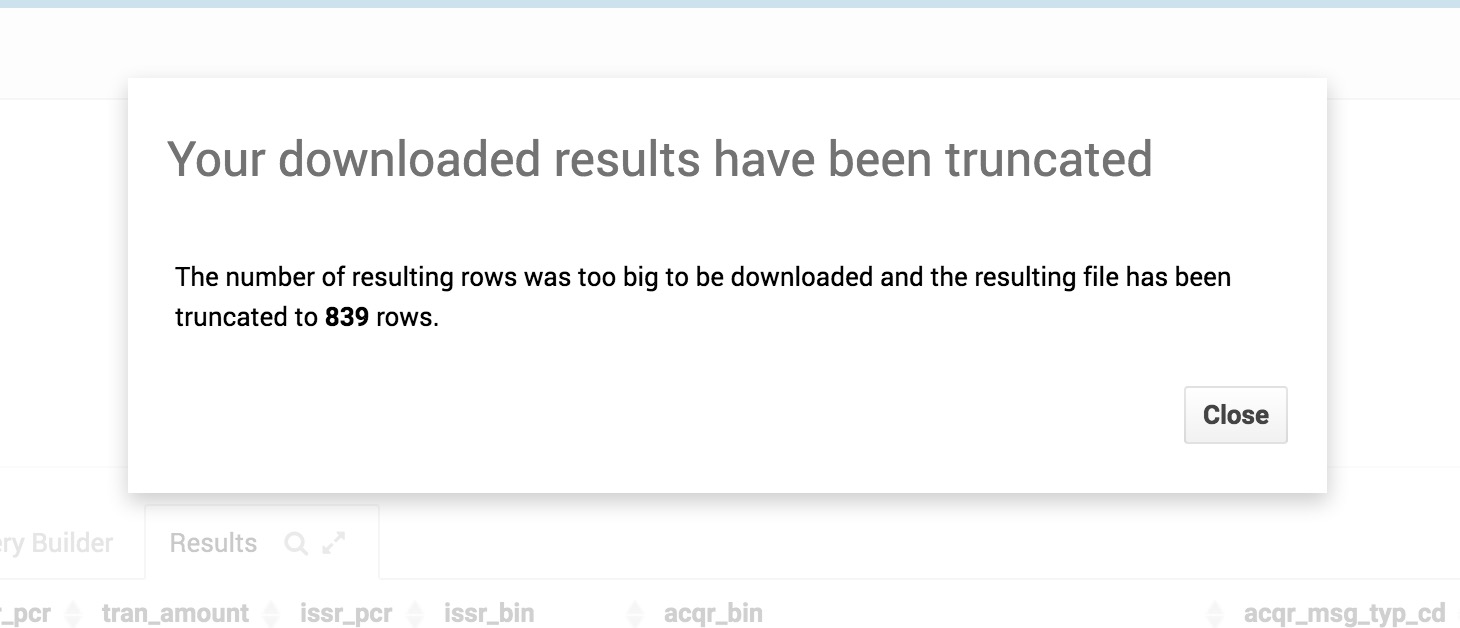
If the download to Excel or CSV takes too long, you will have a nice message now
And Hue will tell you in the download has been truncated too!
As usual you can send feedback and participate on the hue-user list or @gethue!