We’re very excited to officially introduce Amazon S3 (Amazon Simple Storage Service) integration in Hue with Hue’s 3.11 release. Hue can be setup to read and write to a configured S3 account, and users can directly query from and save data to S3 without any intermediate moving/copying to HDFS.
S3 Configuration in Hue
Hue’s filebrowser can now allow users to explore, manage, and upload data in an S3 account, in addition to HDFS.
In order to add an S3 account to Hue, you’ll need to configure Hue with valid S3 credentials, including the access key ID and secret access key: http://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSGettingStartedGuide/AWSCredentials.html
These keys can securely stored in a script that outputs the actual access key and secret key to stdout to be read by Hue (this is similar to how Hue reads password scripts). In order to use script files, add the following section to your hue.ini configuration file:
[aws]
[[aws_accounts]]
[[[default]]]
access_key_id_script=/path/to/access_key_script
secret_access_key_script= /path/to/secret_key_script
allow_environment_credentials=false
region=us-east-1
Alternatively (but not recommended for production or secure environments), you can set the access_key_id and secret_access_key values to the plain-text values of your keys:
[aws]
[[aws_accounts]]
[[[default]]]
access_key_id=s3accesskeyid
secret_access_key=s3secretaccesskey
allow_environment_credentials=false
region=us-east-1
The region should be set to the AWS region corresponding to the S3 account. By default, this region will be set to ‘us-east-1’.
Integrating Hadoop with S3
In addition to configuring Hue with your S3 credentials, Hadoop will also need to be configured with the S3 authentication credentials in order to read from and save to S3. This can be done by setting the following properties in your core-site.xml file:
fs.s3a.awsAccessKeyId
AWS access key ID
fs.s3a.awsSecretAccessKey
AWS secret key
For more information see http://wiki.apache.org/hadoop/AmazonS3
With Hue and Hadoop configured, we can verify that Hue is able to successfully connect to your S3 account by restarting Hue and checking the configuration page. You should not see any errors related to AWS, and you should notice an additional dropdown option in the Filebrowser menu from the main navigation:
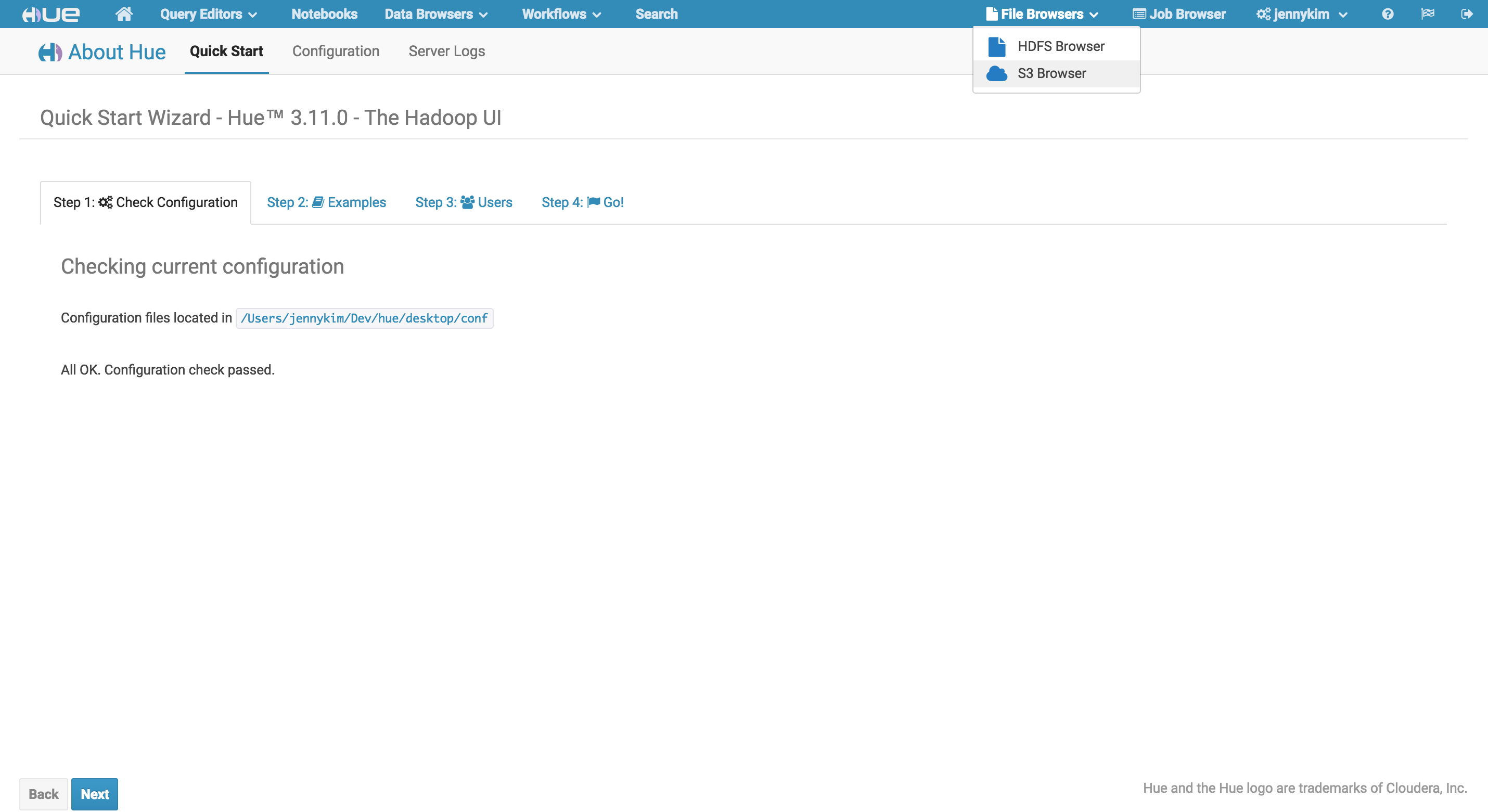
Exploring S3 in Hue’s Filebrowser
Once Hue is successfully configured to connect to S3, we can view all accessible buckets within the account by clicking on the S3 root.
Users can also create new buckets or delete existing buckets from this view.
NOTE: Unique Bucket Names
❗️ S3 bucket names must be unique across all regions. Hue will raise an error if you attempt to create or rename a bucket with a reserved name.
However, in most cases users will be working directly with keys within a bucket. From the buckets-view, users can click on a bucket to expand its contents. From here, we can view the existing keys (both directories and files) and create, rename, move, copy, or delete existing directories and files. Additionally, we can directly upload files to S3
Create Hive Tables Directly From S3
Hue's Metastore Import Data Wizard can create external Hive tables directly from data directories in S3. This allows S3 data to be queried via SQL from Hive or Impala, without moving or copying the data into HDFS or the Hive Warehouse.
To create an external Hive table from S3, navigate to the Metastore app, select the desired database and then click the “Create a new table from a file” icon in the upper right.
Enter the table name and optional description, and in the “Input File or Directory” filepicker, select the S3A filesystem and navigate to the parent directory containing the desired data files and click the “Select this folder” button. The “Load Data” dropdown should automatically select the “Create External Table” option which indicates that this table will directly reference an external data directory.
Choose your input files’ delimiter and column definition options and finally click “Create Table” when you're ready to create the Hive table. Once created, you should see the newly created table details in the Metastore.
Save Query Results to S3
Now that we have created external Hive tables created from our S3 data, we can jump into either the Hive or Impala editor and start querying the data directly from S3 seamlessly. These queries can join tables and objects that are backed either by S3, HDFS, or both. Query results can then easily be saved back to S3.
TIP: Impala and S3
???? For further advanced use-cases with Impala and S3, read: Analytics and BI on Amazon S3 with Apache Impala (Incubating).
Using Ceph
New end points have been added in https://issues.cloudera.org/browse/HUE-5420
What's Next
Hue 3.11's seamless support for S3 as an additional filesystem is just the beginning of a long-term roadmap for greater data flexibility and portability in the Cloud. Stay tuned for future enhancements like cross file transfers, execution and schedule of queries directly from the object store… that will provide a tighter integration between HDFS, S3, and additional filesystems.
As always, if you have any questions, feel free to comment here or on the hue-user list or @gethue!