There are exciting new features coming in Hue 4.1 and later in CDH 6 next year. One of which is Hue’s brand new tool to import data from relational databases to HDFS file or Hive table using Apache Sqoop 1. It enables us to bring large amount of data into the cluster in just few clicks via interactive UI. This Sqoop connector was added to the existing import data wizard of Hue.
In the past, importing data using Sqoop command line interface could be a cumbersome and inefficient process. The task expected users to have a good knowledge of Sqoop . For example they would need put together a series of required parameters with specific syntax that would result in errors easy to make. Often times getting those correctly can take a few hours of work. Now with Hue’s new feature you can submityour Sqoop job in minutes. The imports run on YARN and are scheduled by Oozie. This tutorial offers a step by step guide on how to do it.
Tutorial
What you’ll need
First you’ll need to have a running cluster with Apache Sqoop, Apache YARN, Apache Oozie and Hue configured in it.
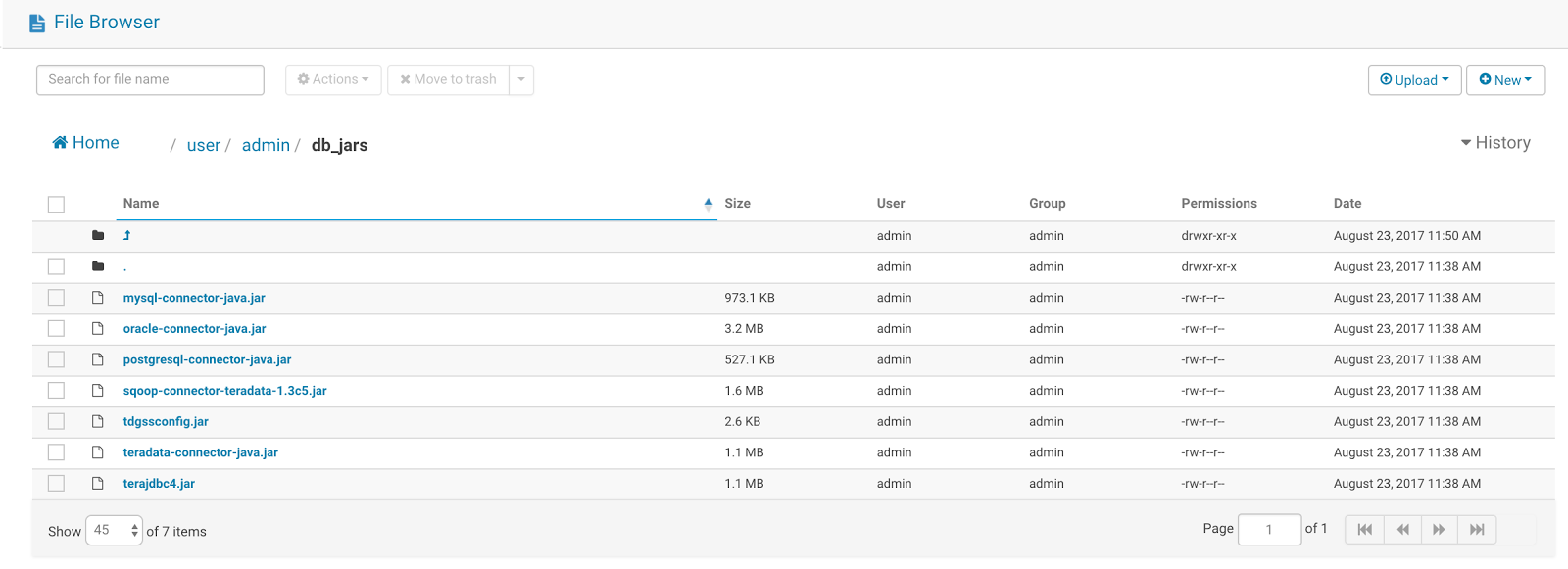
Next you’ll need to install your database specific JDBC jars. To do so place them in a directory somewhere on HDFS.
And to get the MySQL autocomplete would need to configure the Lib RDBMS and notebook: https://gethue.com/custom-sql-query-editors/
Additionally, you would need to turn on the feature by setting enable_sqoop to true under the indexer section in the Hue ini.

Note:
If using Cloudera Manager, check how to add properties in hue.ini safety valve and put the above parameter value there.
Selecting source Tables
Now let’s get started!
In this tutorial, we’ll be importing a table from Teradata to Apache Hive. Click on the hamburger menu on the left pane and select the option on the bottom-left corner of your screen to navigate to Hue’s indexer section. Select External Database from the Type drop-down.
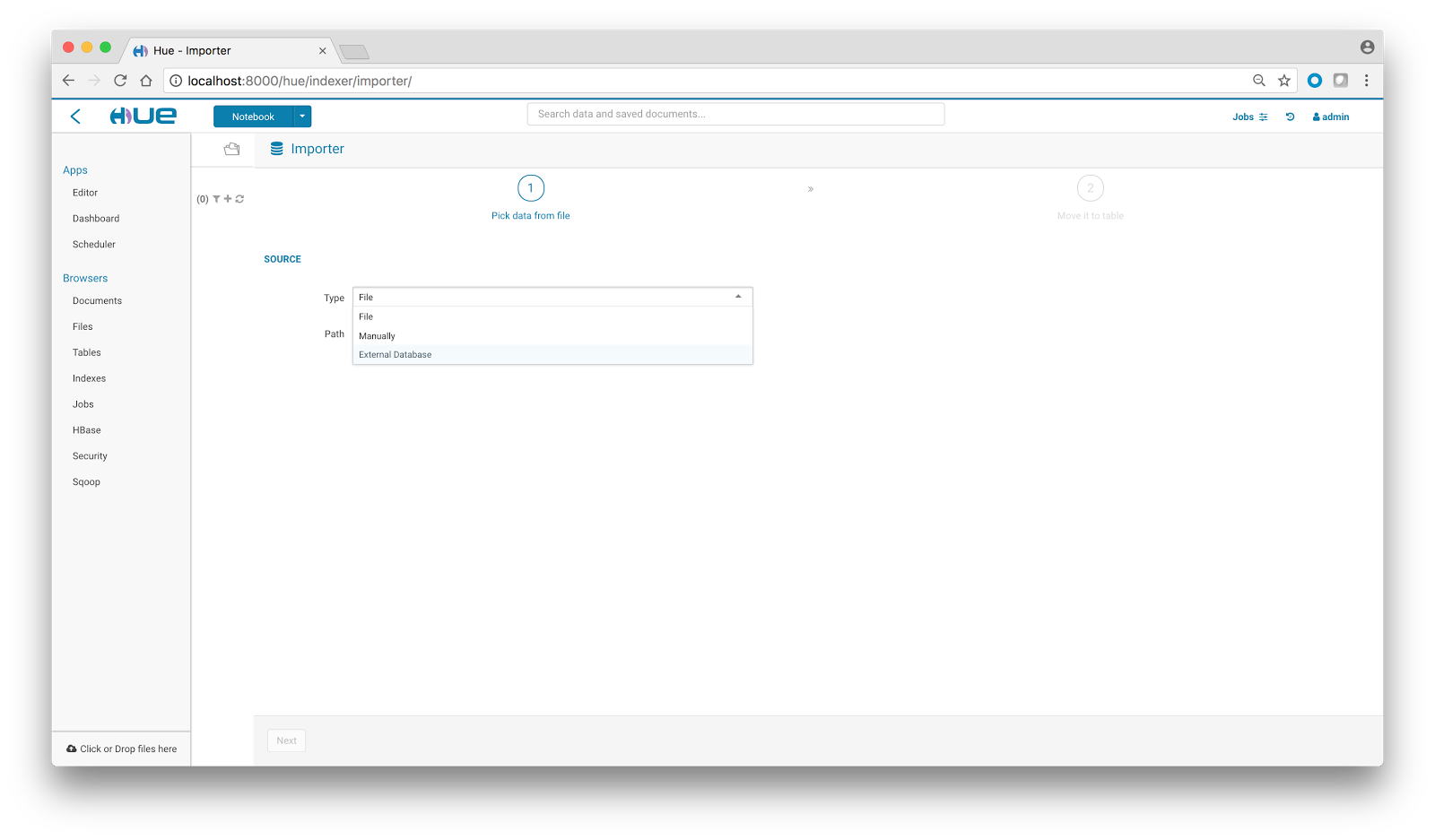
There are two modes for selecting the database:

Note: The JDBC option in either of the modes allows us to point to database using JDBC specific credentials.
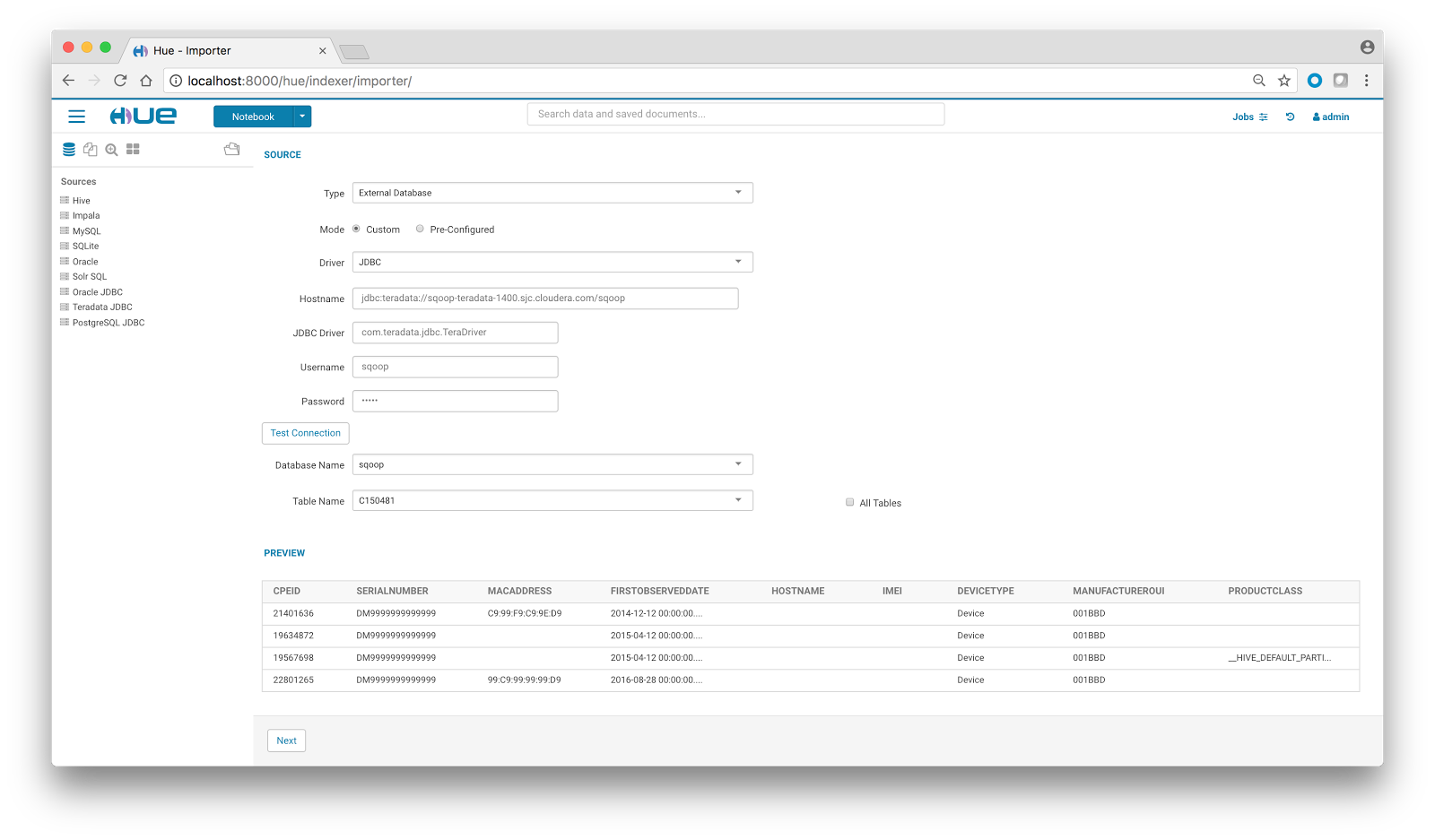
We’ll choose the custom mode for now, give the database credentials and initiate a Test Connection. Once the test passes, a dropdown gets populated with list of database names. On database selection, the list of table names populates up. On table selection, a quick preview comes handy. You can also check the All Tables option to import all the tables of a particular database in one go.
Selecting Destination
Once we are done with the source page, click on Next to navigate to the destination page. Here, select the Destination type which could be a HDFS file or Hive table. Also select all the database specific jars which are needed by Sqoop to run the import job. Since we selected Teradata, we’ll select all the teradata-specific jars.

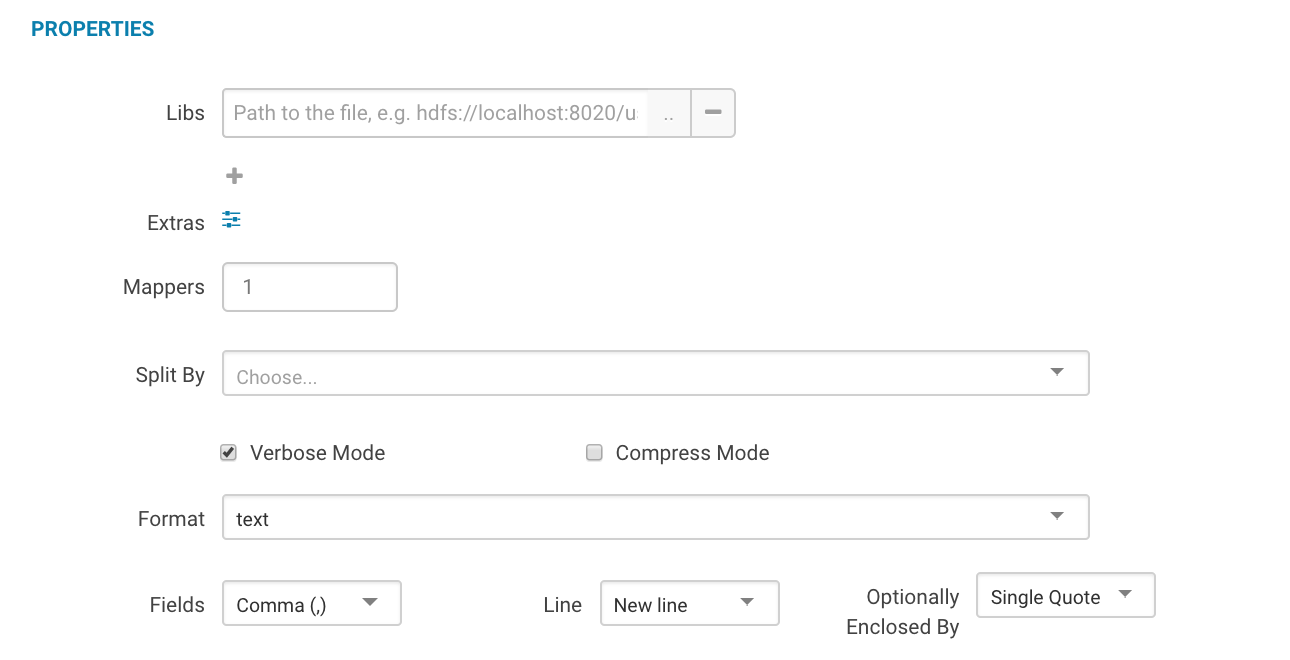
We can also add extra options like mapper number, output data format, delimiters, verbose mode, split-by option, compress mode, etc to our import job. This is explained in detail in documentation section.
We can even rename column names and filter out the columns which are not needed by unchecking the Keep checkbox.
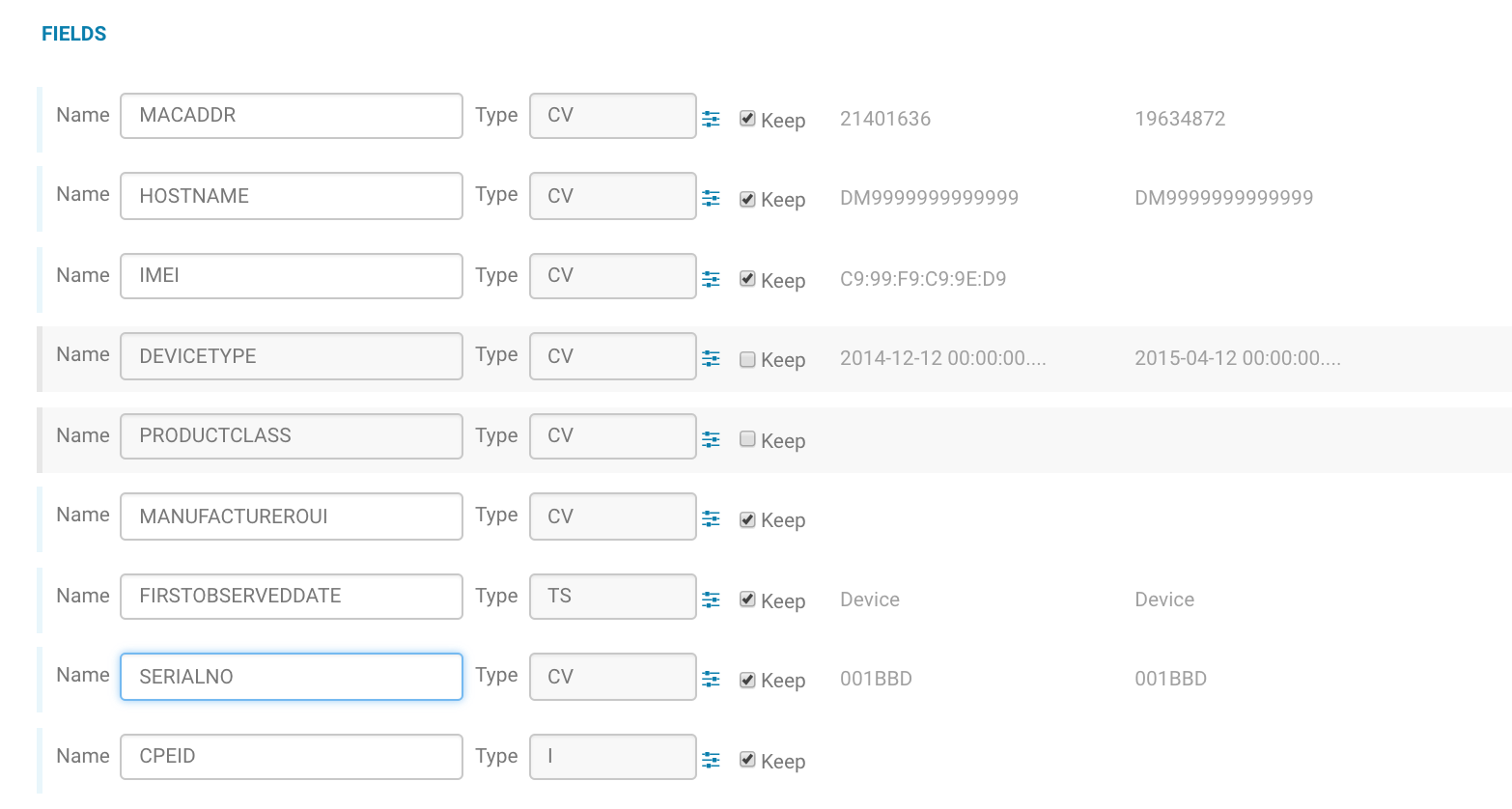
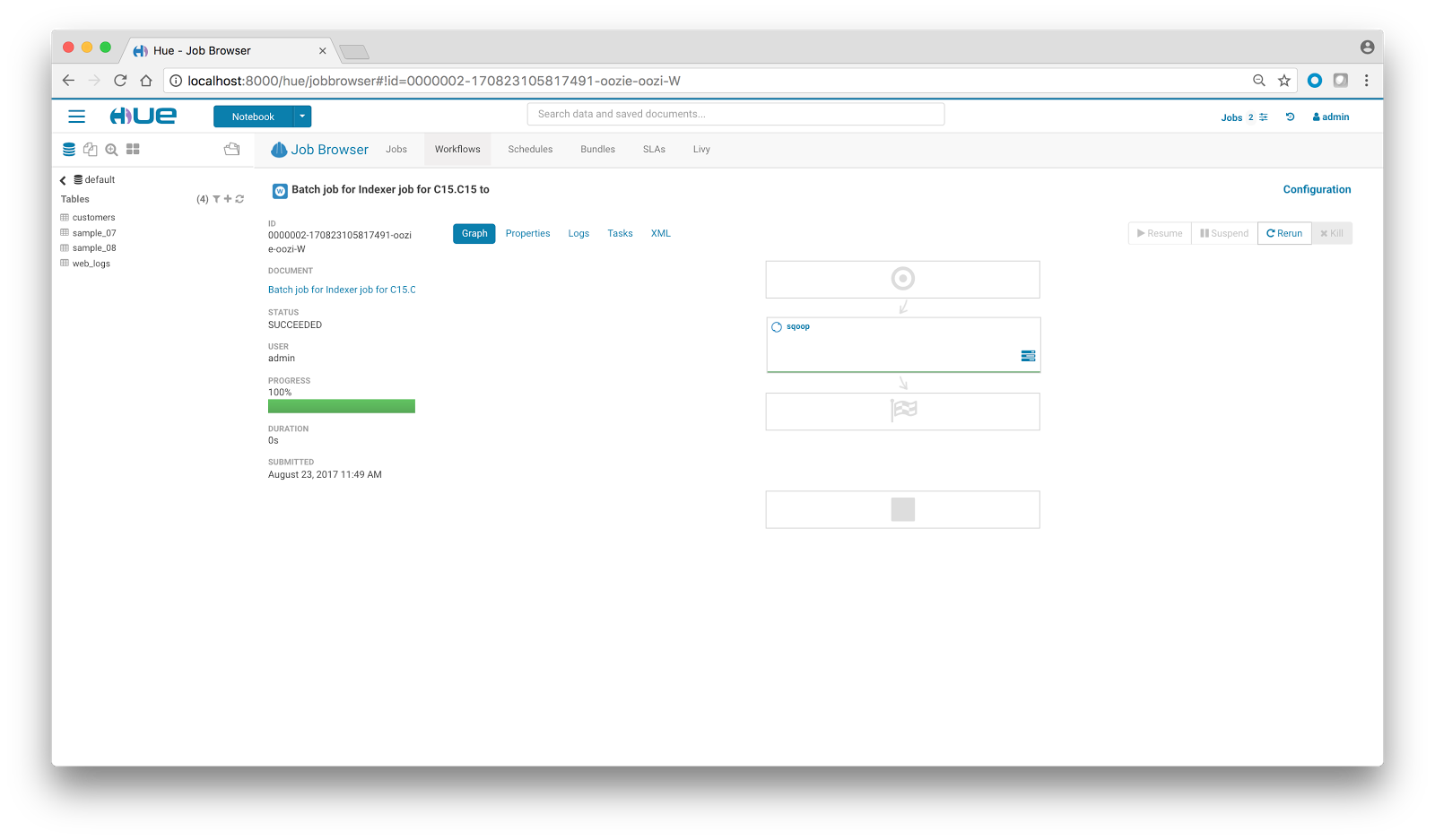
Now, let’s click on the Submit button. On doing so, a Sqoop job is generated which could be tracked in Hue’s Job Browser.
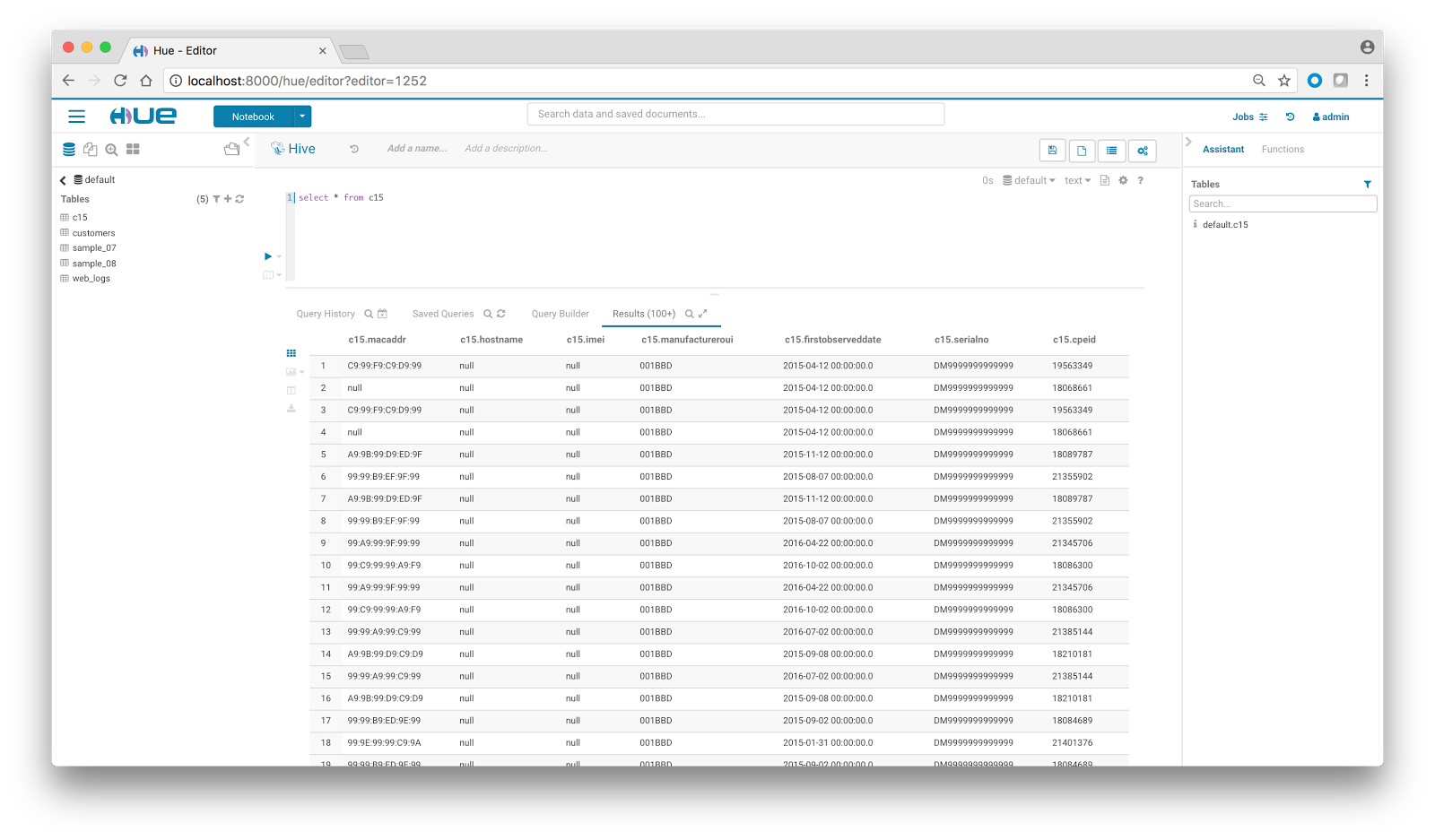
After the completion of the job, we can leverage Hue’s Editor for data processing and query analytics by executing Hive/Impala queries on the freshly imported data.
Documentation
Assembling the lib directory yourself
We’ll need all the required libraries for the Sqoop import job to execute. The requirement is specific to the database which is being used. The jars needed for some of the popular databases are listed below:
- Oracle: oracle-connector-java.jar
- MySQL: mysql-connector-java.jar
- Teradata: teradata-connector-java.jar, sqoop-connector-teradata-1.3c5.jar, tdgssconfig.jar, terajdbc4.jar
- PostgreSQL: postgresql-connector-java.jar
Settings
Properties provide many other options to further tune the import operations to suit your specific workload.
- Libs: Database specific libraries needed by Sqoop 1
- Mappers: Uses n map tasks to import in parallel
- Split By: Column of the table used to split work units
- Verbose Mode: Print more information while working
- Compress Mode: Enables compression
- Format: Data can be imported in 3 different formats: text, avro, sequence
- Fields: Sets the field separator character (enabled only when format is text)
- Line: Sets the end-of-line character (enabled only when format is text)
- Optionally Enclosed By: Sets a field enclosing character (enabled only when format is text)
Supported Databases
Any database which is supported by Sqoop 1.
Troubleshooting
During the importing process, datatypes of the columns could be changed to HDFS/Hive compatible datatypes. When importing a table, the primary key is used to create the splits for mapper. If there is no primary key, the split-by column needs to be chosen explicitly; failing to do so results in import failure. While doing an all-table import, if all the tables don’t have primary key, the import job fails. Also, if for some reason the job fails, you can figure out the reason for failure from the logs in job tracker. For further assistance, please visit https://sqoop.apache.org/docs/1.4.6/