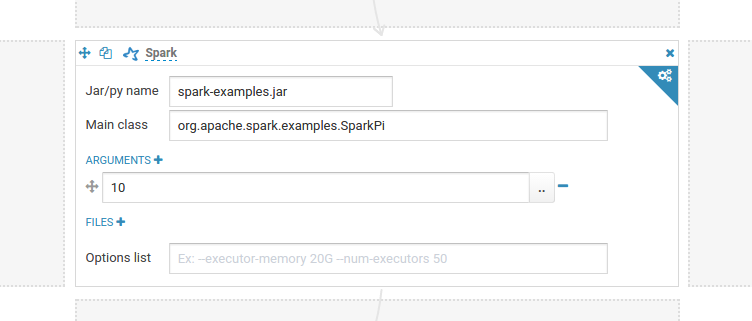
How to run Spark jobs with Spark on YARN? This often requires trial and error in order to make it work.
Hue is leveraging Apache Oozie to submit the jobs. It focuses on the yarn-client mode, as Oozie is already running the spark-summit command in a MapReduce2 task in the cluster. You can read more about the Spark modes here.
Here is how to get started successfully:
PySpark
Simple script with no dependency.
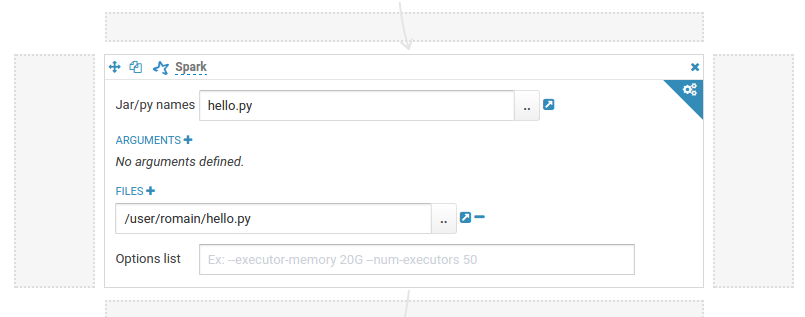
Script with a dependency on another script (e.g. hello imports hello2).
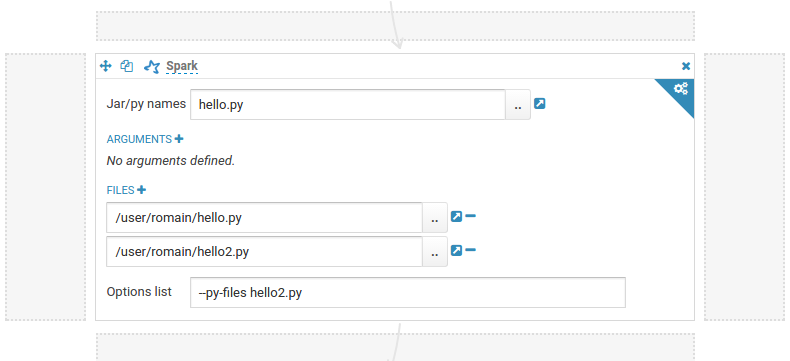
For more complex dependencies, like Panda, have a look at this documentation.
Jars (Java or Scala)
Add the jars as File dependency and specify the name of the main jar:
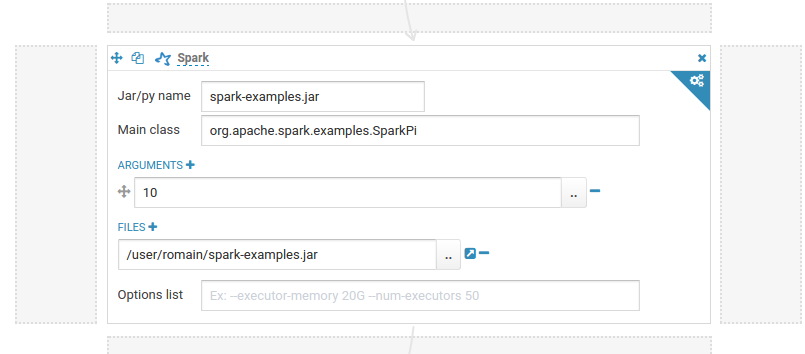
Another solution is to put your jars in the ‘lib’ directory in the workspace (‘Folder’ icon on the top right of the editor).