Update September 2016: this post is getting replaced by https://gethue.com/how-to-schedule-spark-jobs-with-spark-on-yarn-and-oozie/
Hue offers a notebook for Hadoop and Spark, but here are the following steps that will successfully guide you to execute a Spark Action from the Oozie Editor.
Run job in Spark Local Mode
To submit a job locally, Spark Master can be one of the following
- local: Run Spark locally with one worker thread.
- local[k]: Run Spark locally with K worker threads.
- local[*]: Run Spark with as many worker threads as logical cores on your machine.
Insert the Mode as client and provide local/HDFS jar path in Jars/py field. You would also need to specify the App name, Main class to the Jar and arguments (if any) by clicking on the ARGUMENTS+ button.
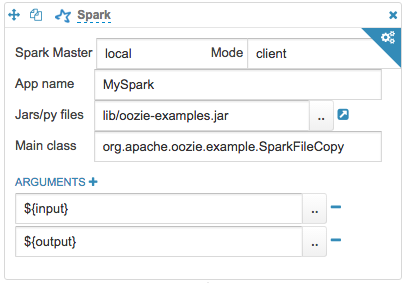
**Note: **Spark's local mode doesn't run with Kerberos.
Run job on Yarn
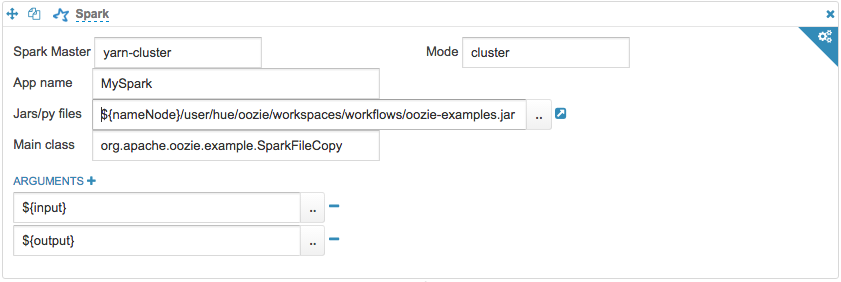
To submit a job on Yarn Cluster, you need to change Spark Master to yarn-cluster, Mode to cluster and give the compete HDFS path for the Jar in Jars/py files field.
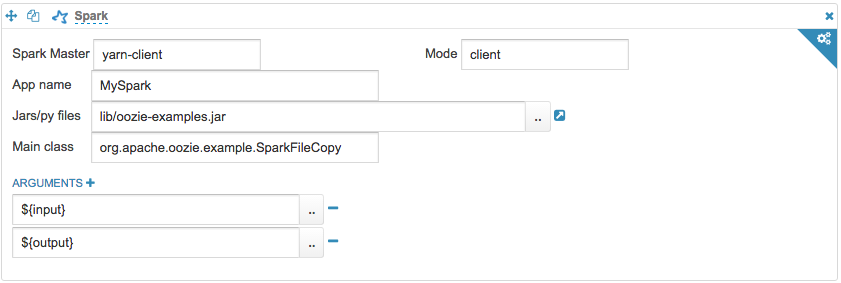
Similarly, to submit a job on yarn-client, change Spark Master to yarn-client, Mode to client, keeping rest of the fields same as above. Jar path can be local or HDFS.
Additional Spark-action properties can be set by clicking the settings button at the top right corner before you submit the job.
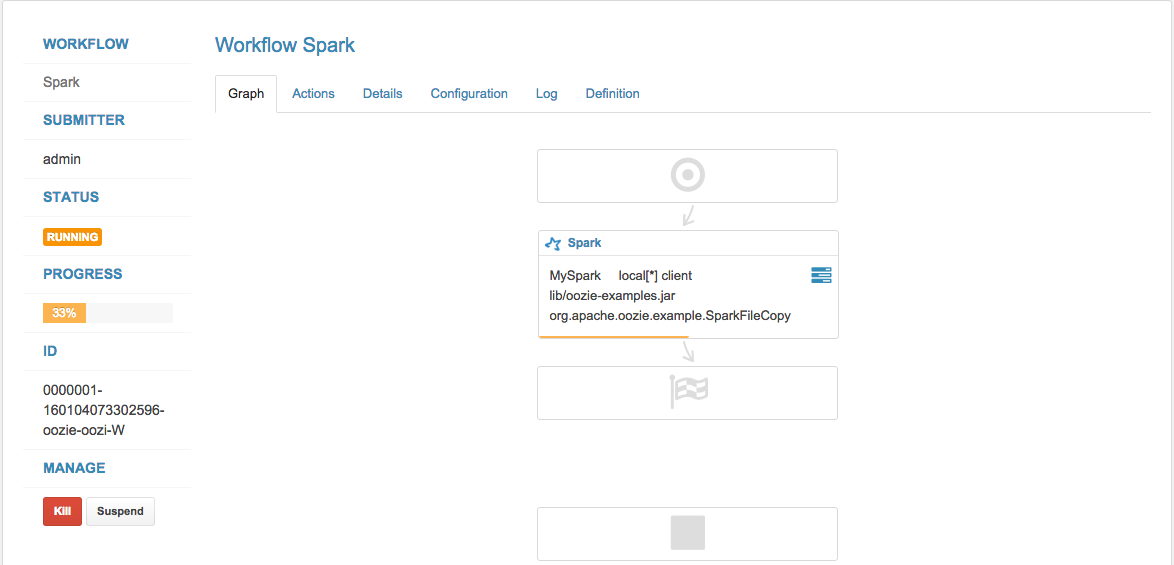
**Note: **If you see the error “Required executor memory (xxxxMB) is above the max threshold…", please increase ‘yarn.scheduler.maximum-allocation-mb’ in Yarn config and restart Yarn service from CM.
Next version is going to include HUE-2645, that will make the UI simple and more intuitive. As usual feel free to comment on the hue-user list or @gethue!