The Oozie Workflow editor is getting a new generic action that let's you drag & drop any of your Hive query of the SQL Editor. Here it is in action:
- Always in sync with the saved query
- Autocomplete Hive parameter
- Behave like any other actions, can fork, see the logs…
- Generates for you the query files in the HDFS workspace
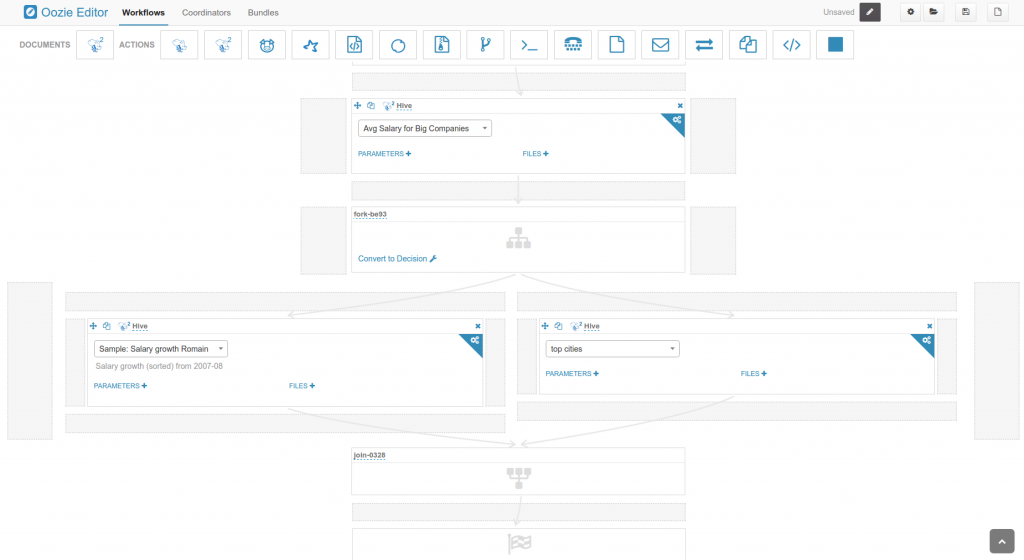
We hope that you like the ease of use of this new drag & drop. Expect more type of documents like Pig, Spark, PySpark in the next Hue version!
And feel free to send feedback on the hue-user list or @gethue!