Data Catalog Search
Before typing any query to get insights, users need to find and explore the correct datasets. The Data Catalog search usability experience has been improved in each release since. It is accessible from the top bar of the interface and offers free text search of SQL tables, columns, tags and saved queries. This is particularly useful for quickly looking up a table among thousands or finding existing queries already analysing a certain dataset.
In this iteration, the search now provides more results directly via the ‘Show more’ link. Existing tags can be faceted simply by typing ‘tags:'.
Some example of searches:
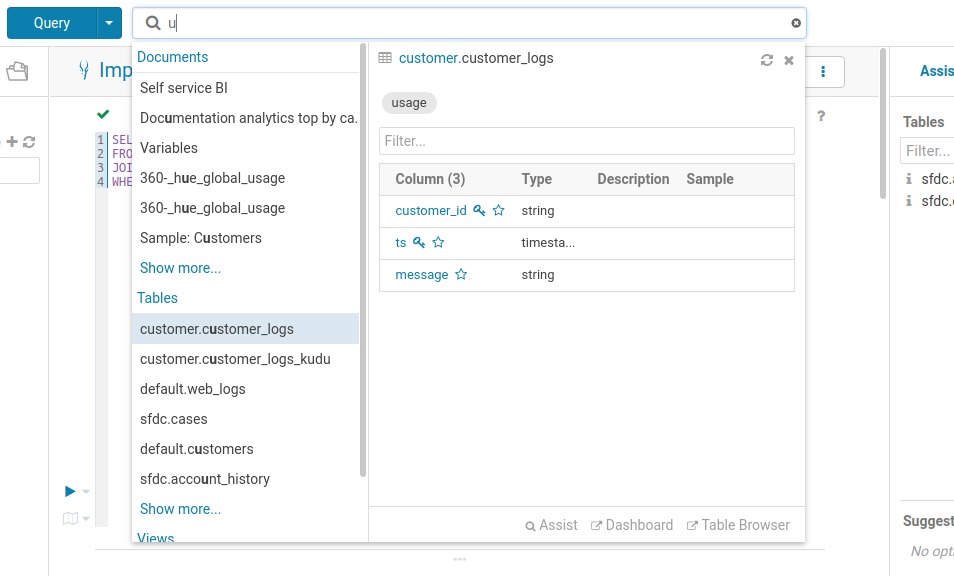
Searching all the available queries or data in the cluster
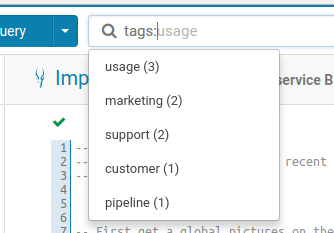
Listing the possible tags to filter on. This also works for 'types'.
Unification and Caching of all SQL metadata
The list of tables and their columns is displayed in multiple part of the interface. This data is pretty costly to fetch and comes from different sources. In this new version, the information is now cached and reused by all the Hue components. As the sources are diverse, e.g. Apache Hive, Cloudera Navigator, Cloudera Optimizer those are stored into a single object, so that it is easier and faster to display without caring about the underlying technical details.
In addition to editing the tags of any SQL objects like tables, views, columns… which has been available since version one, table descriptions can now also be edited. This allows a self service documentation of the metadata by the end users, which was not possible until know as directly editing Hive comments require some admin Sentry privileges which are not granted to regular users in a secure cluster.
In the upcoming version,this information is also reused on the Catalog pages.
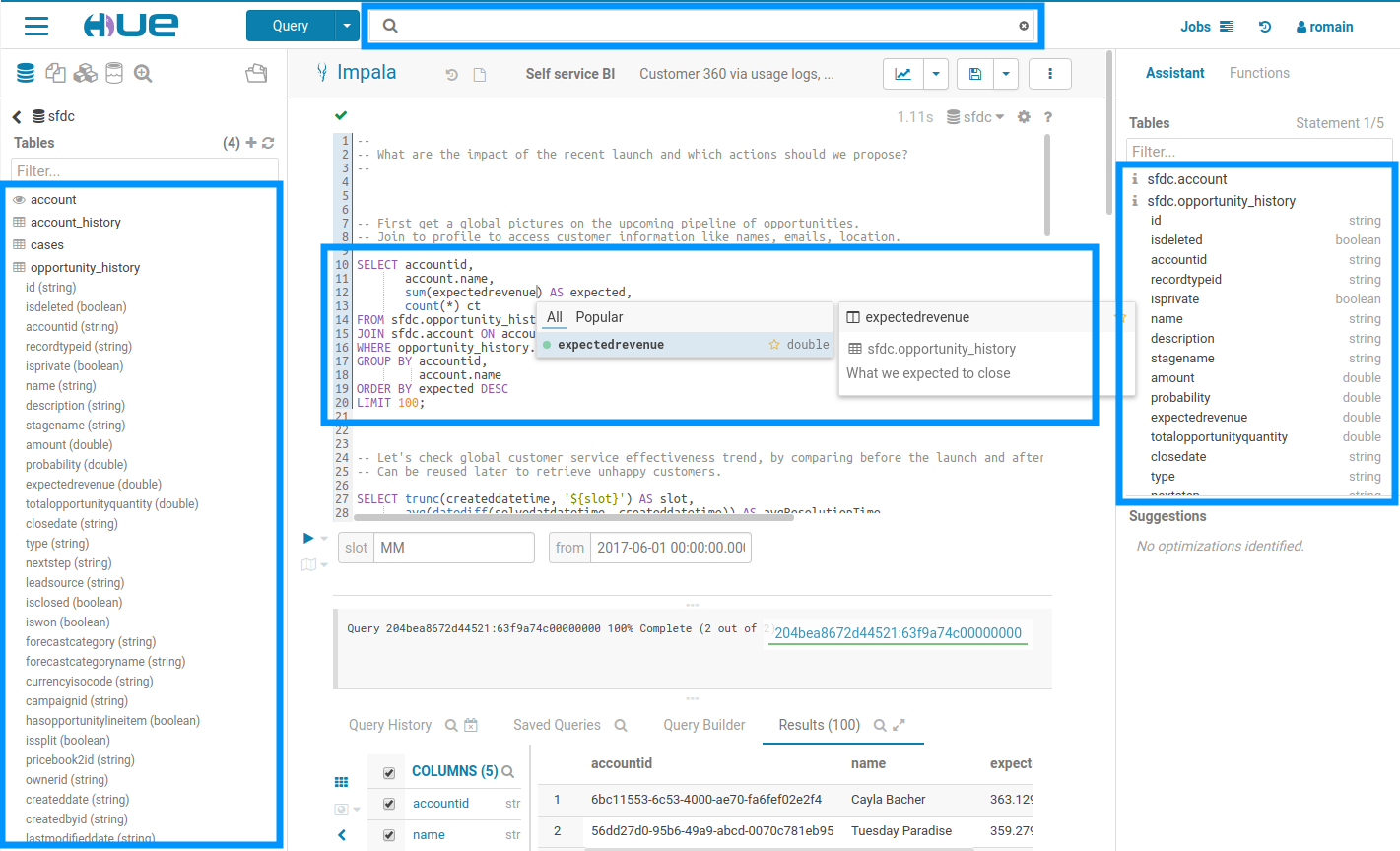
Showing all the common data now cached and unified for a slicker experience
As usual thank you to all the project contributors and for sending feedback and participating on the hue-user list or @gethue!