Last update February 2nd 2017
We recently launched demo.gethue.com, which in one click lets you try out a real Hadoop cluster. We followed the exact same process as building a production ready cluster. Here is how we did it.
Before getting started, you will need to get your hands on some machines. Hadoop runs on commodity hardware, so any regular computer with a major linux distribution will work. To follow along with the demo, take a look at Amazon Cloud Computing service. If you already have a server or two, or don't mind running Hadoop on your local linux box, then go straight to Machine Setup!
Here is a video demoing how easy it is to boot your own cluster and start crunching data!
Machine setup
We picked AWS and started 4 r3.large instances with Ubuntu 14.04 and 100 GB storage (instead of the default 8GB). If you need less performance, one xlarge instance is enough or you can install less services on an even smaller instance.
Then configure the security group like below. We allow everything between the instances (the first row, don’t forget it on multi machine cluster!) and open up Cloudera Manager and Hue ports to the outside.
|
All TCP |
Hadoop Setup
Now that we have some machines, let’s install Hadoop. We used Cloudera Manager as it installs everything for us and just followed this guide. Moreover, post install monitoring and configuration are also greatly simplified with the administration interface.
Start first by connecting to one of the machine:
ssh -i ~/demo.pem ubuntu@ec2-11-222-333-444.compute-1.amazonaws.com
Retrieve and start Cloudera Manager:
wget http://archive.cloudera.com/cm5/installer/latest/cloudera-manager-installer.bin
chmod +x cloudera-manager-installer.bin
sudo ./cloudera-manager-installer.bin
After, login with the default credentials admin/admin (note: you might need to wait 5 minutes before http://ec2-54-178-21-60.compute-1.amazonaws.com:7180/ becomes available).
Then enter all the Public DNS IP (e.g. ec2-11-222-333-444.compute-1.amazonaws.com) of your machines in the Install Wizard and click go! Et voila, Cloudera Manager will setup your whole cluster automatically for you!
Assign a dynamic IP to your machine with Hue and then go to IP:8888 and start playing with your fully functional Hadoop cluster and its examples!
As usual feel free to comment on the hue-user list or @gethue!
Note
If you are getting a "Bad Request (400)" error, you will need to enter in the hue.ini or CM safety valve:
[desktop]
allowed_hosts=*Note
If you have several machines, it is recommended to move the services around in order to homogenize the memory/CPU usage. For example split HBase, Oozie, Hive and Solr on different hosts.
Note
When running some MapReduce jobs with YARN, if all the jobs deadlock in ACCEPTED or READY states, you might be hitting this YARN bug.
The solution is to use a low number like 2 or 3 for the Dynamic resource manager pools. Go to CM → Clusters → Other → Dynamic Resource Pools → Configuration → Edit → YARN and set ‘Max Running Apps’ to 2.
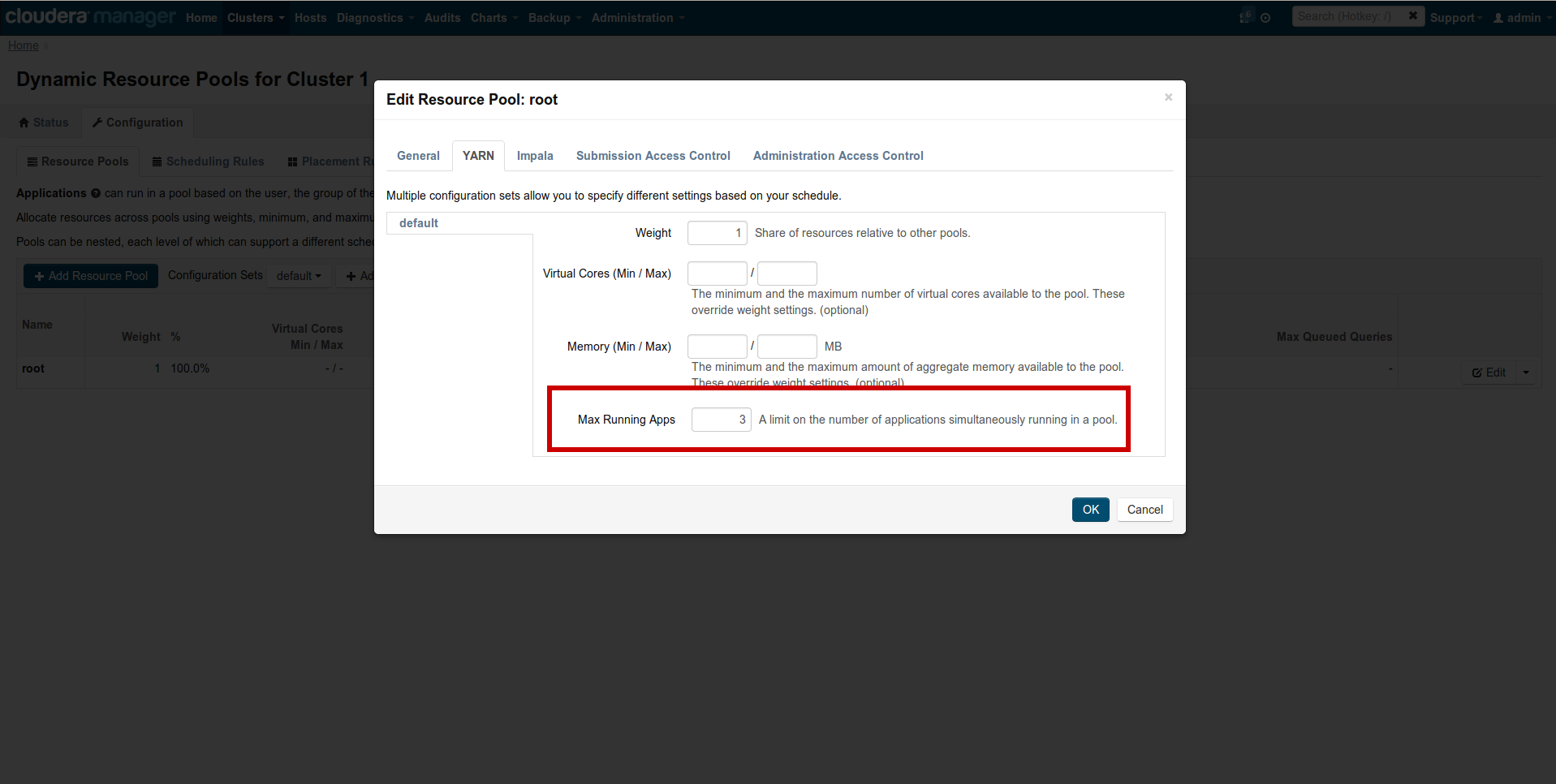
You can also try to decrease yarn.nodemanager.resource.memory-mb and the task memory and bump the memory of yarn.app.mapreduce.am.resource.mb.