Hue is a SQL Editor integrating with the most common data warehouses and databases. Getting specialized autocomplete for each language brings better code maintainability (force a decoupled design), speed (no need to load all the parsers for only one language) and obviously a nicer end user experience (Impala, Hive, PostgreSQL… always have slight different syntax).
In Hue we use generated parsers to handle autocomplete and syntax checking in the editors. In this post we’ll guide you through the steps necessary to create an autocompleter for any SQL dialect in Hue.
There are currently three parsers for this in Hue, one for Impala, one for Hive and a generic SQL parser that is used for other dialects. The parsers are written using a bison grammar and are generated with jison. They’re 100% javascript and live on the client side, this gives the performance of a desktop editor in your browser.
Structure
Normally parsers generate a parse tree but for our purposes we don’t really care about the statement itself but rather about what should happen when parts of a particular statement is encountered. During parsing the state is kept outside the parse tree and in case of syntax errors this enables us to provide some results up to the point of the error. There are two ways that incomplete/erroneous statements are handled, first we try to define most of the incomplete grammar and secondly we rely on the “error” token which allows the parser to recover.
The parsers provide one function, parseSql, that accepts the text before the cursor and the text after the cursor as arguments. The function returns an object containing instructions on what to suggest given the input.
As an example:
sqlParserRepository.getAutocompleteParser('impala').then(parser => {
console.log(parser.parseSql('SELECT * FROM customers'));
});
Would output something like:
{
definitions: [],
locations: (6) [{…}, {…}, {…}, {…}, {…}, {…}],
lowerCase: false,
suggestAggregateFunctions: {tables: [Array(1)]},
suggestAnalyticFunctions: true,
suggestColumns: {source: "select", tables: [{identifierChain: [{name: "customers"}]}]},
suggestFunctions: {},
suggestKeywords: (8) [{…}, {…}, {…}, {…}, {…}, {…}, {…}, {…}]
}
We take this output and link it to various sources of metadata to provide the list of suggestions the user finally sees. In this case we’d use the data from “suggestColumns” to call the backend for all the columns of the “customers” table. We’d also use the functions library to list all the UDFs etc.
Here’s a list of some of the different types of suggestions the parser can identify:
|
suggestAggregateFunctions suggestAnalyticFunctions suggestColRefKeywords suggestColumnAliases suggestColumns suggestCommonTableExpressions suggestDatabases suggestFilters suggestFunctions suggestGroupBys |
Parsers are generated and added to the repository using our custom cli app generateParsers.js under tools/jison/. To for instance generate all the Impala parsers you would run the following command in the hue folder:
node tools/jison/generateParsers.js impalaIn reality two parsers are generated per dialect, one for syntax and one for autocomplete. The syntax parsers is a subset of the autocomplete parser with no error recovery and without the autocomplete specific grammar.
All the jison grammar files can be found here and the generated parsers are also committed together with their tests here.
The grammar
In a regular SQL parser you might define the grammar of a select statement like this:
SelectStatement
: 'SELECT' ColumnList 'FROM' Identifier
;
ColumnList
: Identifier
| ColumnList ',' Identifier
;
This would be able to parse a statement like 'SELECT a, b, c FROM some_table' (depending on lexer definitions of course). To turn this into an autocompleter we add the notion of a cursor to the mix, it’s defined as an obscure character that’s unlikely to be used in a statement. We went for '\u2020', the dagger, identified as 'CURSOR' in the lexer. The actual parsed string is therefore beforeCursor + ‘\u2020’ + afterCursor.
For the statement above we’d add an extra rule with an _EDIT postfix like this:
SelectStatement
: 'SELECT' ColumnList 'FROM' Identifier
;
SelectStatement_EDIT
: 'CURSOR' --> { suggestKeywords: ['SELECT'] }
| 'SELECT' ColumnList_EDIT
| 'SELECT' ColumnList 'CURSOR' --> { suggestKeywords: ['FROM'] }
| 'SELECT' ColumnList 'FROM' 'CURSOR' --> { suggestTables: {} }
| 'SELECT' ColumnList_EDIT 'FROM' Identifier --> { suggestColumns: { table: $4 } }
;
So if a “lonely” cursor is encountered it will tell us to suggest the ‘SELECT’ keyword etc.
Tutorial: Creating a basic PostgreSQL parser in 5 minutes
Prerequisites: make sure you have jison installed and a development Hue. Then configure a PostgreSQL interpreter.
In the Hue folder:
./build/env/bin/pip install psycopg2-binary
and edit your hue config desktop/conf/pseudo-distributed.ini to contain:
[notebook]
[[interpreters]]
[[[postgresql]]]
name = postgresql
interface=sqlalchemy
options='{";url": "postgresql://hue:pwd@dbhost:31335/huedb"}'
Our generateParsers tool can take an existing dialect and setup the source code for a new parsers based on that.
In the hue folder run:
node tools/jison/generateParsers.js -new generic postgresqlAfter the -new argument you specify an existing dialect to clone first and then the name of the new parser.
Once executed the tool has cloned the generic parser with tests and generated a new postgresql parsers. The jison files can be found under desktop/core/src/desktop/js/parse/jison/sql/postgresql/ and the tests can be found in desktop/core/src/desktop/js/parse/sql/postgresql/test
To regenerate the parsers after changes to the jison files run:
node tools/jison/generateParsers.js postgresqlThe tool will report any problems with the grammar. Note that it might still generate a parser if the grammar isn’t ambiguous but it’s likely that there will be test failures.
Extending the grammar
This gives you an idea on how to add custom syntax to the newly generated postgresql parser. For this example we’ll add the REINDEX statement as it’s quite simple.
REINDEX { INDEX | TABLE | DATABASE | SYSTEM } name [ FORCE ]We’ll start by adding a test, in postgresqlAutocompleteParser.test.js in the test folder inside the main describe function before the first ‘it(“should …’:
fdescribe('REINDEX', () => {
it('should handle "REINDEX TABLE foo FORCE; |"', () => {
assertAutoComplete({
beforeCursor: 'REINDEX TABLE foo FORCE; ',
afterCursor: '',
noErrors: true,
containsKeywords: ['SELECT'],
expectedResult: {
lowerCase: false
}
});
});
it('should suggest keywords for "REINDEX |"', () => {
assertAutoComplete({
beforeCursor: 'REINDEX ',
afterCursor: '',
noErrors: true,
containsKeywords: ['INDEX', 'DATABASE'],
expectedResult: {
lowerCase: false
}
});
});
});
When we now run npm run test there should be two failing tests.
Next we’ll have to add the keyword to the lexer, let’s open sql.jisonlex in the jison folder for postgresql and add the following new tokens:
'REINDEX' { parser.determineCase(yytext); return 'REINDEX'; }
'INDEX' { return 'INDEX'; }
'SYSTEM' { return 'SYSTEM'; }
'FORCE' { return 'FORCE'; }
Now let’s add the grammar, starting with the complete specification. For simplicity we’ll add it in sql_main.jison, at the bottom of the file add:
DataDefinition : ReindexStatement ; ReindexStatement : 'REINDEX' ReindexTarget RegularOrBacktickedIdentifier OptionalForce ; ReindexTarget : 'INDEX' | 'TABLE' | 'DATABASE' | 'SYSTEM' ; OptionalForce : | 'FORCE' ;
“DataDefinition” is an existing rule and this extends that rule with “ReindexStatement”.
Save the file(s) and first run node tools/jison/generateParsers.js postgresql then npm run test and we should be down to one failing test.
For the next one we’ll add some keyword suggestions after the user has typed REINDEX, we’ll continue below the ReindexStatement in sql_main.jison:
DataDefinition_EDIT
: ReindexStatement_EDIT
;
ReindexStatement_EDIT
: 'REINDEX' 'CURSOR'
{
parser.suggestKeywords(['DATABASE', 'INDEX', 'SYSTEM', 'TABLE']);
}
;
Again, run node tools/jison/generateParsers.js postgresql then npm run test and the tests should both be green.
We also want the autocompleter to suggest the keyword REINDEX when the user hasn’t typed anything, to do that let’s first add the following test with the other new ones in postgresqlAutocompleteParserSpec.js:
it('should suggest REINDEX for "|"', () => {
assertAutoComplete({
beforeCursor: '',
afterCursor: '',
noErrors: true,
containsKeywords: ['REINDEX'],
expectedResult: {
lowerCase: false
}
});
});
For this to pass we need to add REINDEX to the list of DDL and DML keywords in the file sqlParseSupport.js next to the generated parser (desktop/core/src/desktop/js/parse/sql/postgresql/sqlParseSupport.js/). Find the function parser.suggestDdlAndDmlKeywords and add ‘REINDEX’ to the keywords array. Now run npm run test and the three tests should pass.
Before you continue further be sure to remove the ‘f’ from ‘fdescribe’ in the spec to allow all other tests to run. Note that in this case there will be two new failing tests where the keyword ‘REINDEX’ has to be added.
In order to use the newly generated parsers we have to add them to the webpack bundles:
npm run webpack
npm run webpack-workersWhile developing it will speed up if the webpack bundling runs in the background, for this open two terminal sessions and run on npm run dev in one and npm run dev-workers in the other. It will then monitor changes to the files and build a lot quicker.
After the bundling you can now test it directly in the editor:
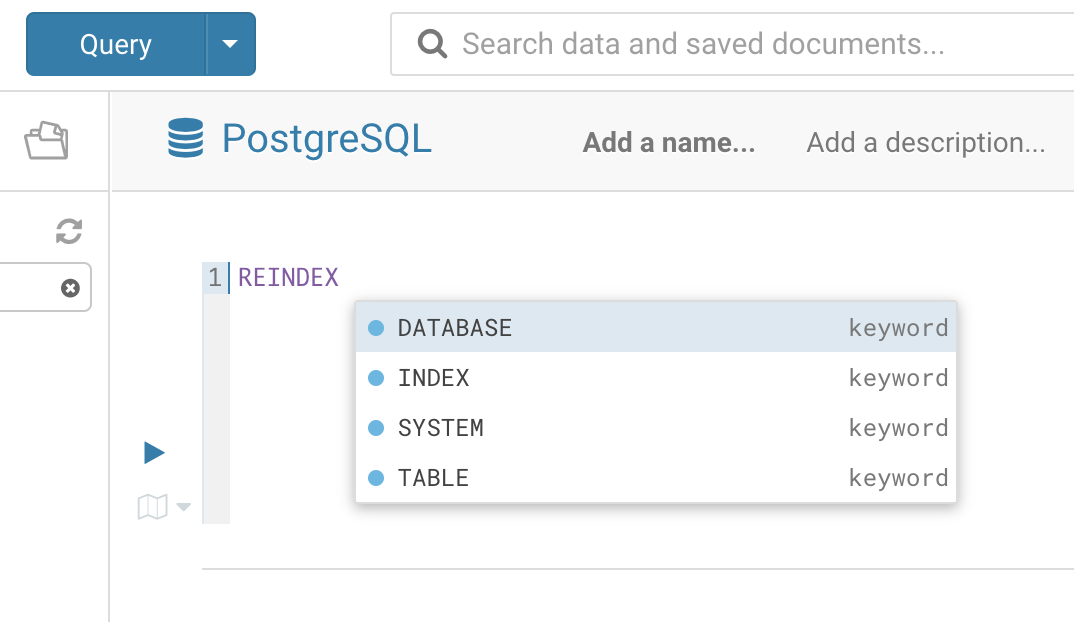
We hope this will get you to dive in to the wonderful world of autocompleters and grammars! Looking for a good project? Integrating Apache Calcite, ZetaSql, PartiQL… would make SQL users even happier with a lot more Databases!
And as always, if you have any feedback or questions then feel free to comment here or on @gethue!