Phoenix brings SQL to HBase and let you query Kafka data streams
Initially published on https://medium.com/data-querying/phoenix-brings-sql-to-hbase-and-let-you-query-kafka-data-streams-8fd2edda1401
Apache HBase is a massive key value database in the Big Table family. It excels in random read/write and is distributed. The Hue Query Assistant is a versatile SQL compose Web application with a goal of making database querying easy and ubiquitous within organizations.
In this post we will demo the recent integration of Apache Phoenix which provides a SQL interfacing layer to HBase, hence making it easy to query. Note that Hue already supported querying HBase via a native application, but the beauty of SQL is its popularity (many people know the basics of SQL) and letting us piggyback on the powerful capacity of the Hue Editor.
Typical use cases involve ingesting live data like metrics, tracing, logs in order to perform real time analysis or querying. Here we will demo via a classic “Hello World” and then via live log ingestion transiting in Kafka.
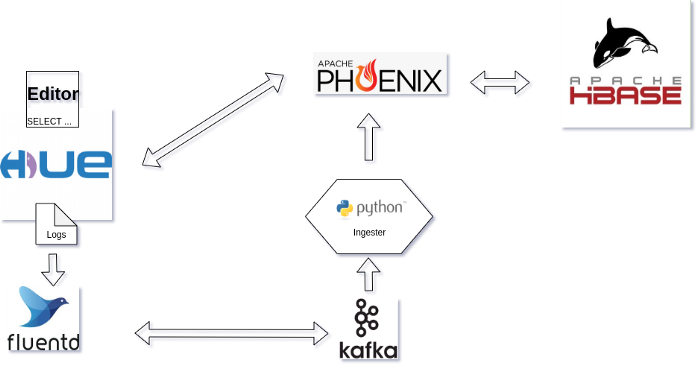
A Docker compose environment was developed so that it is just 1 click to test on your own. It includes these services:
- HBase
- Phoenix Query Server
- Hue Query Assistant (already comes with the Phoenix connector)
- Fluentd to live ingest Hue logs into Kafka
- Python Ingester script consuming logs from Kafka and pushing to HBase
For fetching the Docker Compose configuration and starting everything:
mkdir big-table-hbase
cd big-table-hbase
wget https://raw.githubusercontent.com/romainr/query-demo/master/big-table-hbase/docker-compose.yml
docker-compose up -d
>
Creating hue-database ... done
Creating query-demo_zookeeper_1 ... done
Creating hbase-phoenix ... done
Creating query-demo_fluentd_1 ... done
Creating query-demo_kafka_1 ... done
Creating hue ... done
Creating kafka2phoenix ... done
Then those URLs will be up:
- http://localhost:8888/ Hue Editor
- http://localhost:8765/ Phoenix Query Server
For stopping everything:
docker-compose down
Hello World
We will just follow the official Get started in 15 minutes tutorial, which is even quicker in our case.
CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city)
);
UPSERT INTO us_population VALUES ('NY','New York',8143197);
UPSERT INTO us_population VALUES ('CA','Los Angeles',3844829);
UPSERT INTO us_population VALUES ('IL','Chicago',2842518);
UPSERT INTO us_population VALUES ('TX','Houston',2016582);
UPSERT INTO us_population VALUES ('PA','Philadelphia',1463281);
UPSERT INTO us_population VALUES ('AZ','Phoenix',1461575);
UPSERT INTO us_population VALUES ('TX','San Antonio',1256509);
UPSERT INTO us_population VALUES ('CA','San Diego',1255540);
UPSERT INTO us_population VALUES ('TX','Dallas',1213825);
UPSERT INTO us_population VALUES ('CA','San Jose',91233);
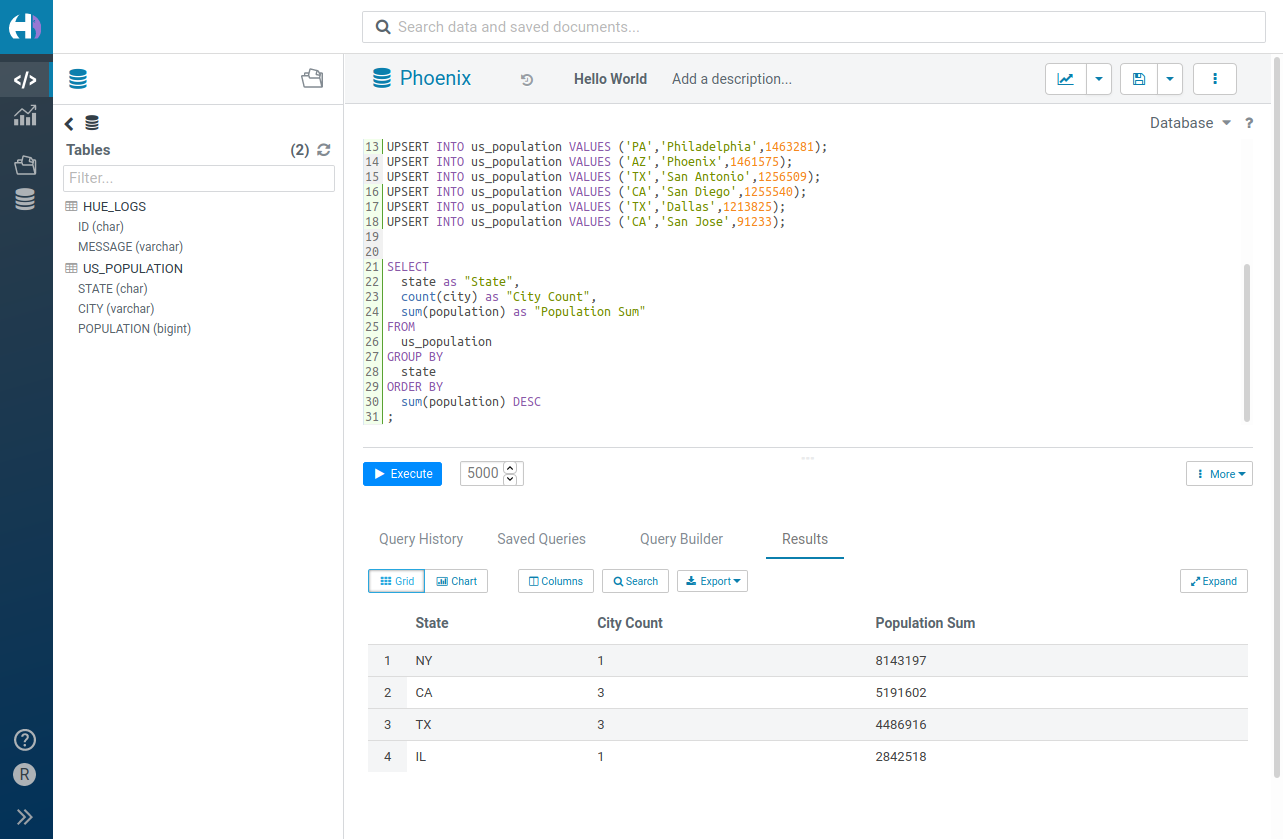
SELECT
state as "State",
count(city) as "City Count",
sum(population) as "Population Sum"
FROM
us_population
GROUP BY
state
ORDER BY
sum(population) DESC
;
Querying a stream of Kafka data
To make the demo more realistic, we will query some live data ingested into a Kafka topic. The data consists in the access logs of the SQL Editor itself (so we are doing a meta data analysis of Hue usage ;). In practice this could be any other type of data like customer orders, weather, stocks, traffic data…
To keep things simple we use a small ingester program to read the data from Kafka and push it to HBase, so that we can query it and see the live results. They are many tools to perform this in production, like the Phoenix Kafka Consumer, Apache Nifi, Apache Spark, Fluentd…
In our case we read the Kafka topic
hue_logs
with the kafka-python module and after having creating the Phoenix table we insert the Kafka records into the table via the Phoenix Python module sending an UPSERT statement.
CREATE TABLE hue_logs (
id CHAR(30) PRIMARY KEY,
message VARCHAR
)
UPSERT INTO hue_logs VALUES
(<timestamp of record + id>, <log message>)
In the architecture diagram, replace the ingester/Fluentd/Kafka with your home solution.
Then just query the Phoenix table hue_logs a few times to see latest access logs of the Hue service stored in HBase:
SELECT *
FROM hue_logs
ORDER BY id DESC
LIMIT 100
Et voila!
Many thanks to the community and the Phoenix/HBase team. And more improvements are on the way with in particular a better SQL autocomplete, connector for the create table wizard and some builtin SQL examples.
And if you are eager to try it, you can even access it in one click on demo.gethue.com!
Onwards!
Romain