Self-service exploratory analytics is one of the most common use cases of the Hue users. In this tutorial, let's see how to get started on the analysis. We will use the free Instacart dataset and start with the Importer feature.
Getting the data
This steps was made particularly easy by Instacart. Just go on their dataset page of 3 million orders and download the 200 MBs.
Making it queryable
Next step is not always trivial. In our case, there is no data team adding the dataset to the Data Catalog for us, but hopefully we can use the Data Importer of Hue.
Upload to the object store
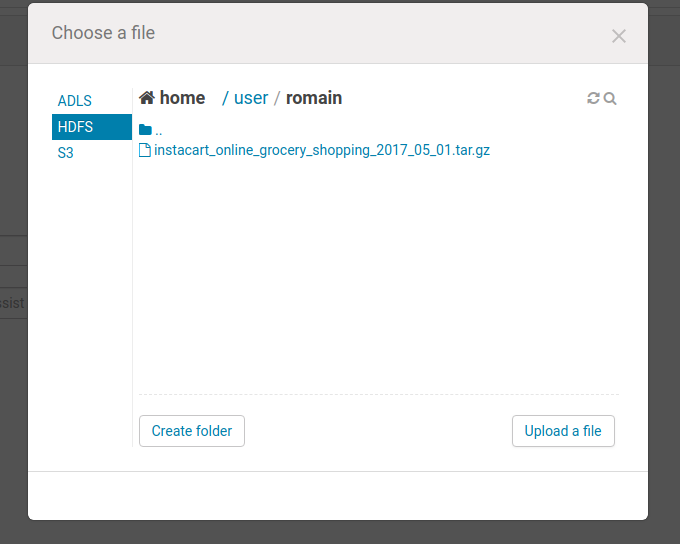
First upload the dataset to the cluster. This is easy via the File Browser.
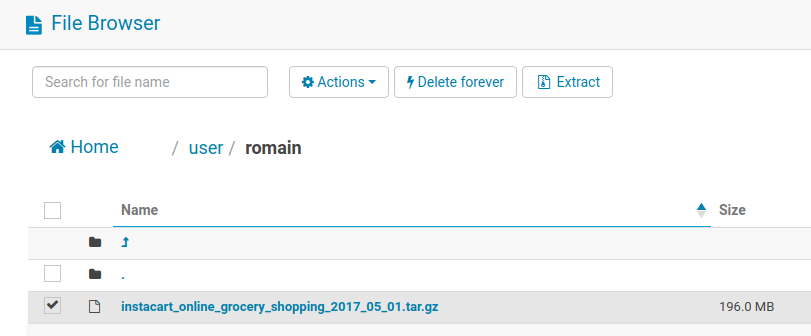
Then, the next step is to uncompress the archive. This is also convenient to do in two clicks via the File Browser. Note that the processing is happening in the cluster, not on your machine, and it is an efficient way to upload multiple files.
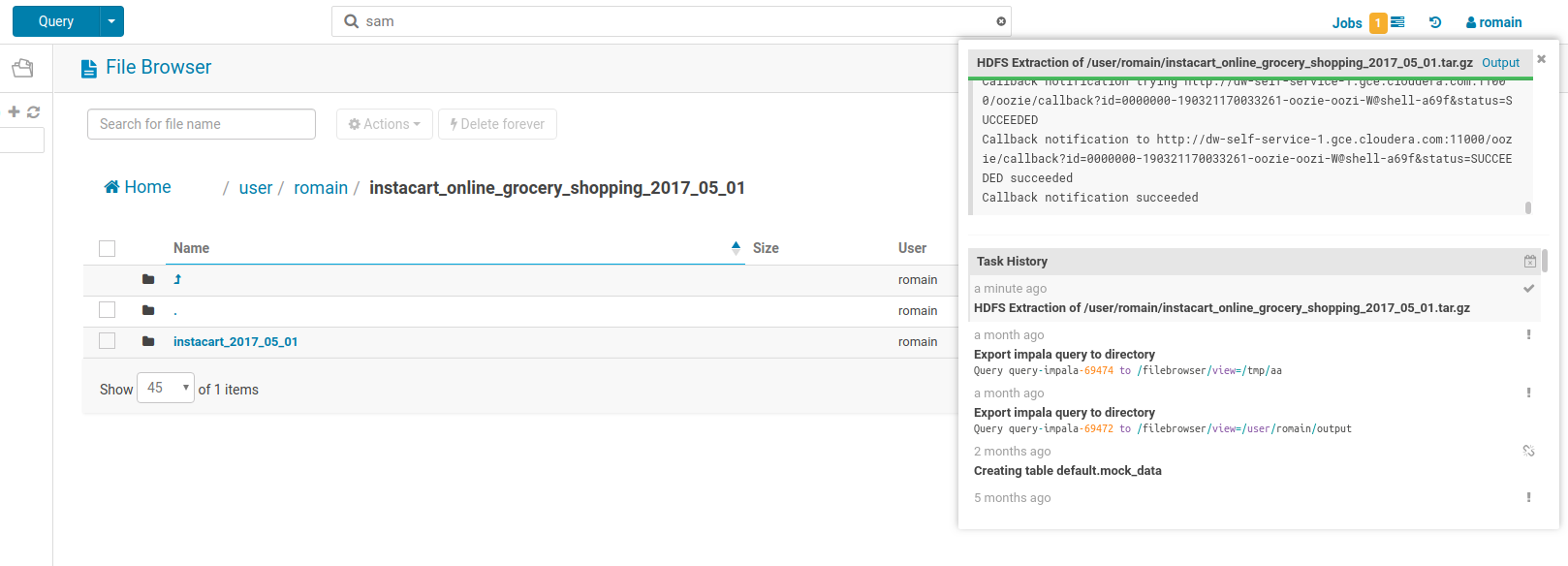
Load via the importer
Via the top left Hamburger icon that will open this menu, click in the very bottom. Or use ‘+’ icon in the top of the left SQL Assist. This will open-up the Importer.
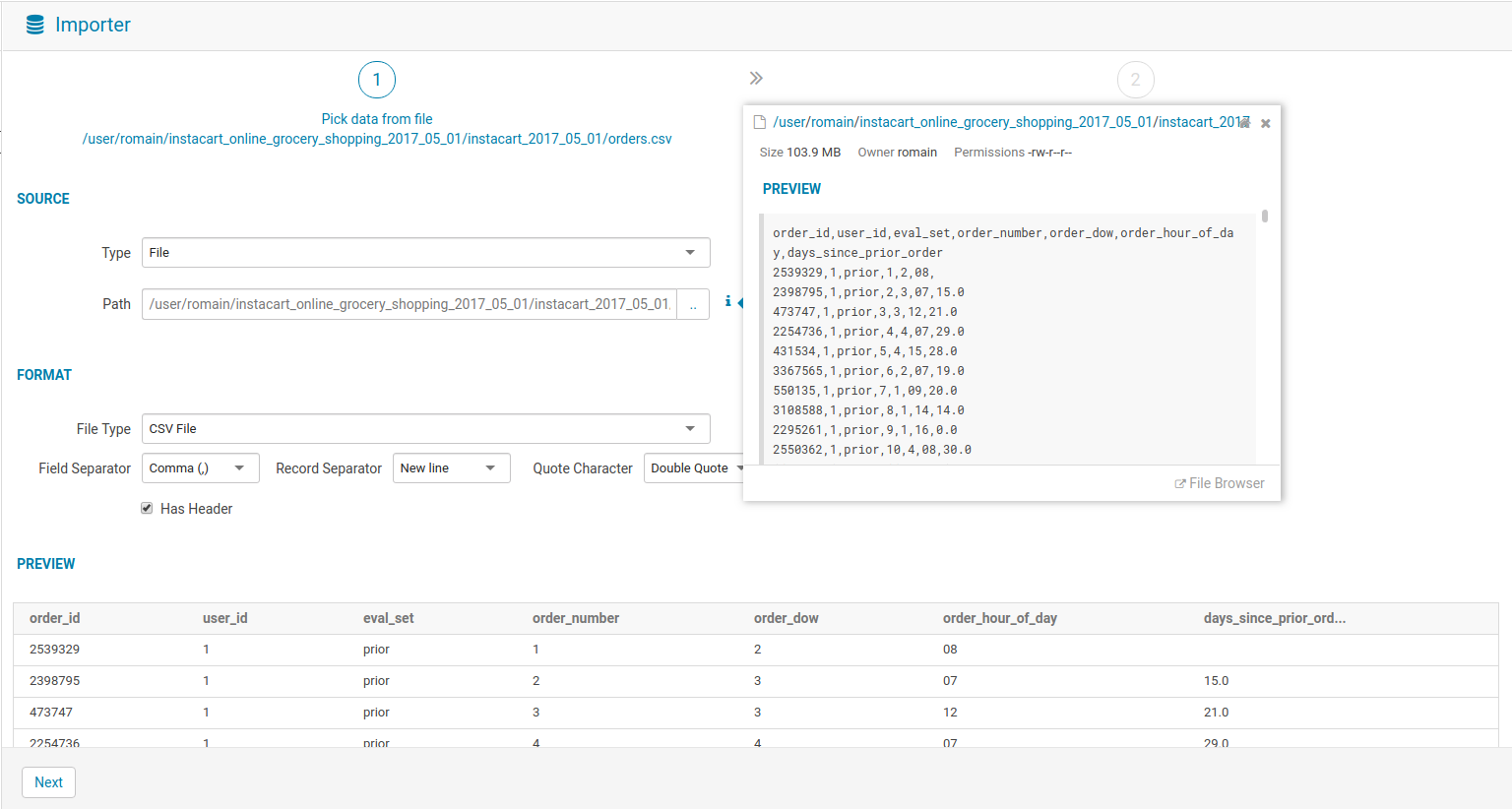
From there, go select the ‘orders’ file that was extracted from the Instacart archive. A File and Table previews are shown automatically.
Click next to go to step 2. Hue auto-detects the types of the columns and checks if the names are valid. In more advanced scenarios, the user could also change the type of the table (e.g. by selecting the Apache Parquet or Apache Kudu format)
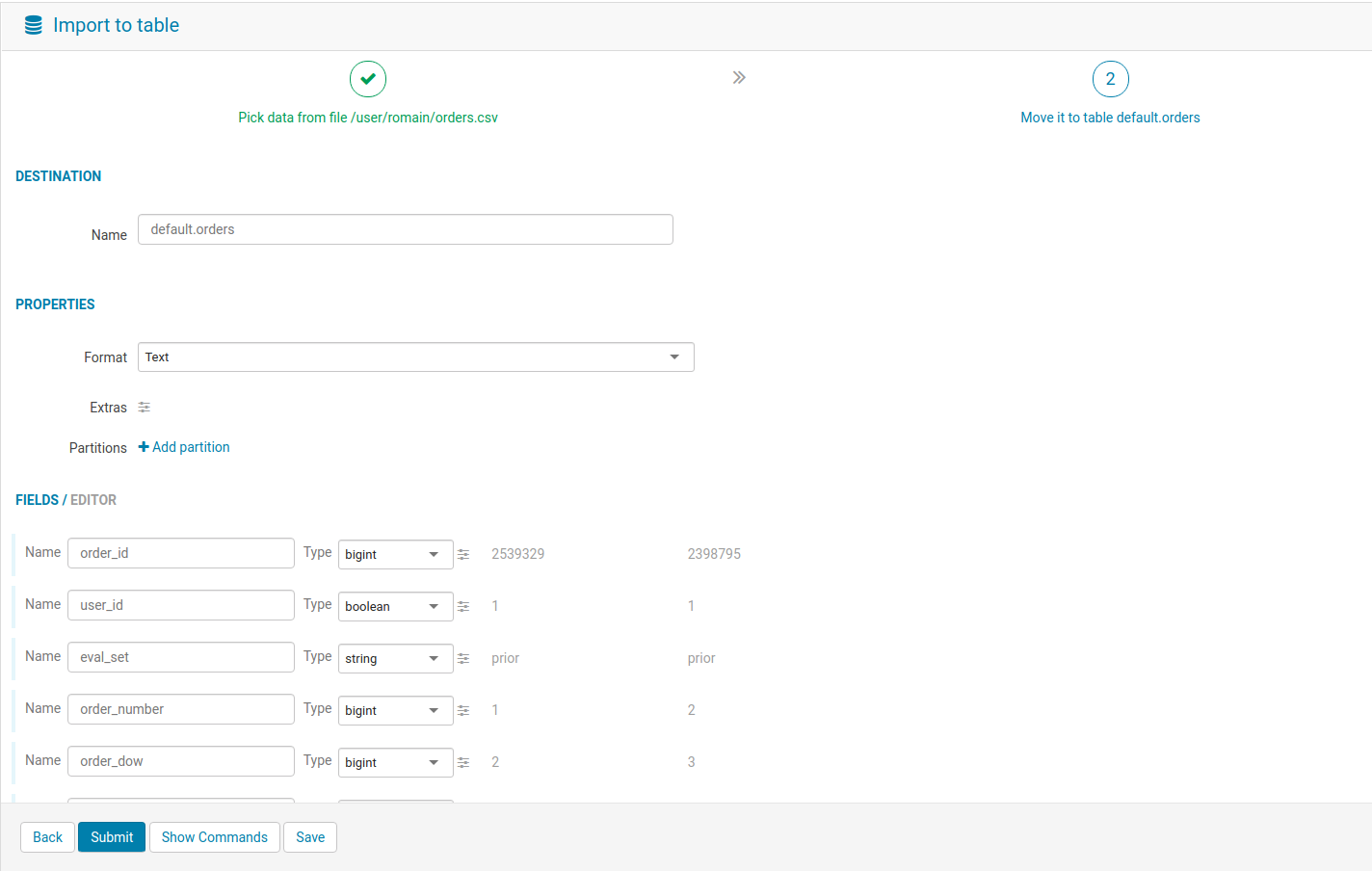
Click ‘Submit’ and afterwards the table will appear in the Data Catalog!
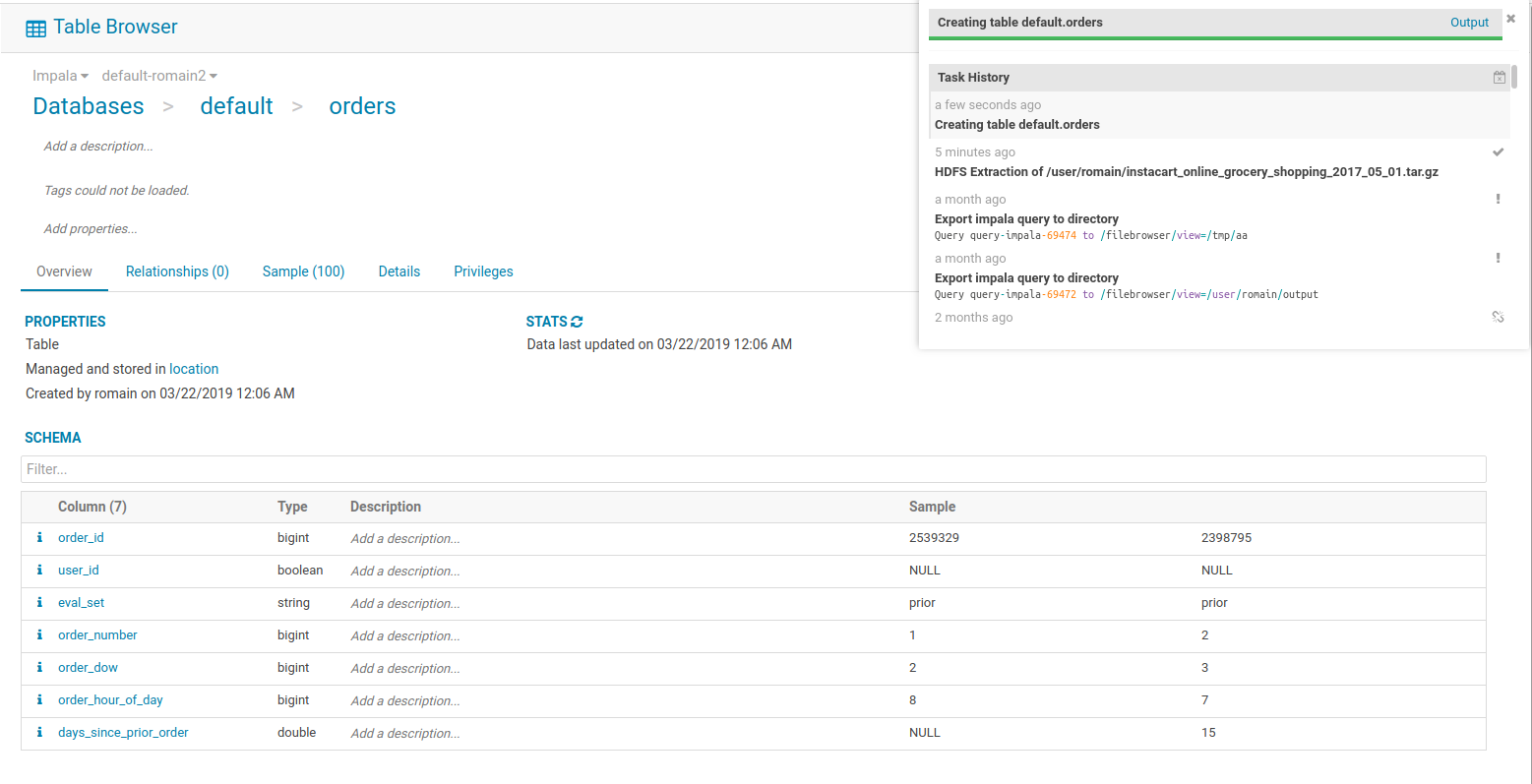
Note: for advanced users, the SQL command to create the table and import the data can also be printed.
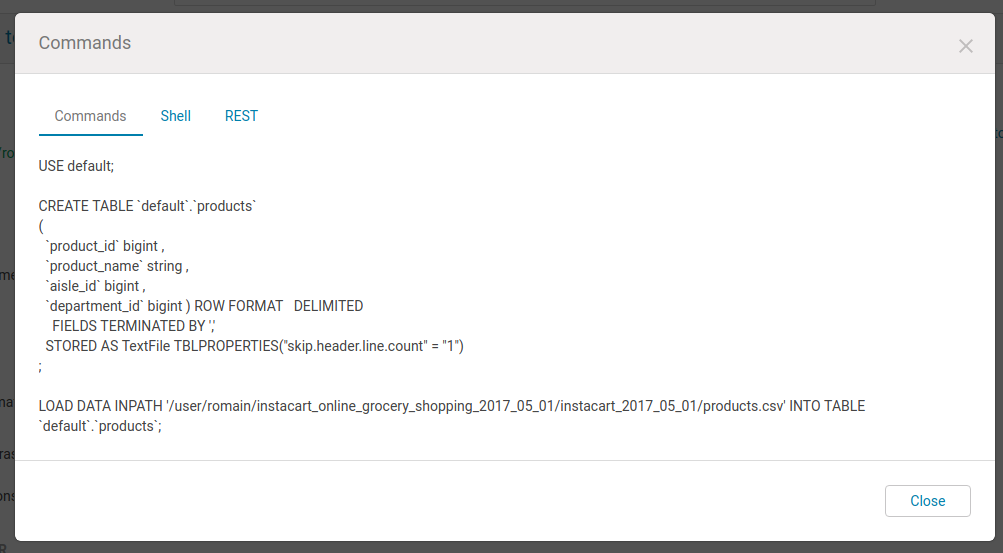
In next episode
Repeat with the ‘products’ file and now you are ready to start querying! We will start from there in the upcoming post of this series.
Note: the importer supports multiple outputs like Solr Dashboards or inputs like regular databases.
As usual feel free to comment here or to send feedback to the hue-user list or @gethue!