Livy is an open source REST interface for interacting with Spark from anywhere. It supports executing snippets of code or programs in a Spark Context that runs locally or in YARN.
Note: Livy is not supported in CDH, only in the upstream Hue community.
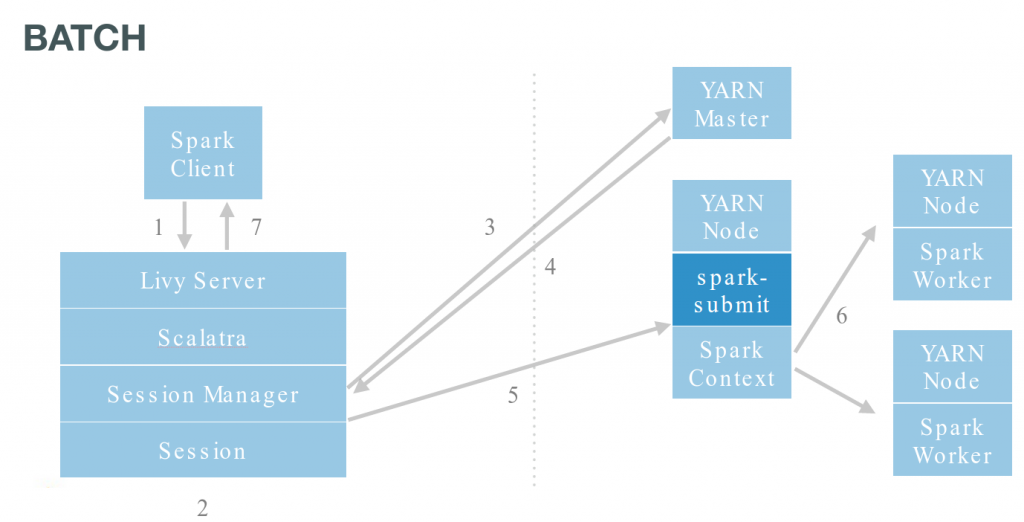
We previously detailed how to use the interactive Shell API (aka spark shells) and how to create remote shared RDDs. In this follow-up we will see how to execute batch jobs (aka spark-submit) in YARN. These jobs can be Java or Scala compiled into a jar or just Python files. Some advantages of using Livy is that jobs can be submitted remotely and don't need to implement any special interface or be re-compiled.
Starting the REST server
This is described in the previous post section.
We are using the YARN mode here, so all the paths needs to exist on HDFS. For local dev mode, just use local paths on your machine.
Submitting a Jar
Livy offers a wrapper around spark-submit that work with jar and py files. The API is slightly different than the interactive. Let's start by listing the active running jobs:
curl localhost:8998/sessions | python -m json.tool % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 34 0 34 0 0 2314 0 -:-:- -:-:- -:-:- 2428
{
"from": 0,
"sessions": [],
"total": 0
}
Then we upload the Spark example jar /usr/lib/spark/lib/spark-examples.jar on HDFS and point to it. If you are using Livy in local mode and not YARN mode, just keep the local path /usr/lib/spark/lib/spark-examples.jar.
curl -X POST -data '{"file": "/user/romain/spark-examples.jar", "className": "org.apache.spark.examples.SparkPi"}' -H "Content-Type: application/json" localhost:8998/batches
{"id":0,"state":"running","log":[]}
We get the submission id, in our case 0, and can check its progress. It should actually already be done:
curl localhost:8998/batches/0 | python -m json.tool
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 902 0 902 0 0 91120 0 -:-:- -:-:- -:-:- 97k
{
"id": 0,
"log": [
"15/10/20 16:32:21 INFO ui.SparkUI: Stopped Spark web UI at http://192.168.1.30:4040",
"15/10/20 16:32:21 INFO scheduler.DAGScheduler: Stopping DAGScheduler",
"15/10/20 16:32:21 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!",
"15/10/20 16:32:21 INFO storage.MemoryStore: MemoryStore cleared",
"15/10/20 16:32:21 INFO storage.BlockManager: BlockManager stopped",
"15/10/20 16:32:21 INFO storage.BlockManagerMaster: BlockManagerMaster stopped",
"15/10/20 16:32:21 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!",
"15/10/20 16:32:21 INFO spark.SparkContext: Successfully stopped SparkContext",
"15/10/20 16:32:21 INFO util.ShutdownHookManager: Shutdown hook called",
"15/10/20 16:32:21 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-6e362908-465a-4c67-baa1-3dcf2d91449c"
],
"state": "success"
}
We can see the output logs:
curl localhost:8998/batches/0/log | python -m json.tool
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 5378 0 5378 0 0 570k 0 -:-:- -:-:- -:-:- 583k
{
"from": 0,
"id": 3,
"log": [
"SLF4J: Class path contains multiple SLF4J bindings.",
"SLF4J: Found binding in [jar:file:/usr/lib/zookeeper/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]",
"SLF4J: Found binding in [jar:file:/usr/lib/flume-ng/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]",
"SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.",
"SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]",
"15/10/21 01:37:27 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable",
"15/10/21 01:37:27 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032",
"15/10/21 01:37:27 INFO yarn.Client: Requesting a new application from cluster with 1 NodeManagers",
"15/10/21 01:37:27 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)",
"15/10/21 01:37:27 INFO yarn.Client: Will allocate AM container, with 1408 MB memory including 384 MB overhead",
"15/10/21 01:37:27 INFO yarn.Client: Setting up container launch context for our AM",
"15/10/21 01:37:27 INFO yarn.Client: Setting up the launch environment for our AM container",
"15/10/21 01:37:27 INFO yarn.Client: Preparing resources for our AM container",
....
....
"15/10/21 01:37:40 INFO yarn.Client: Application report for application_1444917524249_0004 (state: RUNNING)",
"15/10/21 01:37:41 INFO yarn.Client: Application report for application_1444917524249_0004 (state: RUNNING)",
"15/10/21 01:37:42 INFO yarn.Client: Application report for application_1444917524249_0004 (state: FINISHED)",
"15/10/21 01:37:42 INFO yarn.Client: ",
"\t client token: N/A",
"\t diagnostics: N/A",
"\t ApplicationMaster host: 192.168.1.30",
"\t ApplicationMaster RPC port: 0",
"\t queue: root.romain",
"\t start time: 1445416649481",
"\t final status: SUCCEEDED",
"\t tracking URL: http://unreal:8088/proxy/application_1444917524249_0004/A",
"\t user: romain",
"15/10/21 01:37:42 INFO util.ShutdownHookManager: Shutdown hook called",
"15/10/21 01:37:42 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-26cdc4d9-071e-4420-a2f9-308a61af592c"
],
"total": 67
}
We can add an argument to the command, for example do 100 iterations that way the result is more precise and will run longer:
curl -X POST -data '{"file": "/usr/lib/spark/lib/spark-examples.jar", "className": "org.apache.spark.examples.SparkPi", "args": ["100"]}' -H "Content-Type: application/json" localhost:8998/batches
{"id":1,"state":"running","log":[]}
In case we want to stop the running job, we just issue:
curl -X DELETE localhost:8998/batches/1
{"msg":"deleted"}
Doing it another time will return nothing as the job was removed from Livy:
curl -X DELETE localhost:8998/batches/1
session not found
Submitting a Python job
Submitting Python jobs is almost identical to jar jobs. We uncompress the spark examples and upload pi.py on HDFS:
~/tmp$ tar -zxvf /usr/lib/spark/examples/lib/python.tar.gz
./
./sql.py
./kmeans.py
./cassandra_outputformat.py
./mllib/
./mllib/correlations.py
./mllib/kmeans.py
....
....
./streaming/flume_wordcount.py
./streaming/recoverable_network_wordcount.py
./streaming/hdfs_wordcount.py
./streaming/kafka_wordcount.py
./streaming/stateful_network_wordcount.py
./streaming/sql_network_wordcount.py
./streaming/mqtt_wordcount.py
./streaming/network_wordcount.py
./streaming/direct_kafka_wordcount.py
./wordcount.py
./pi.py
./hbase_inputformat.py
Then start the job:
curl -X POST -data '{"file": "/user/romain/pi.py"}' -H "Content-Type: application/json" localhost:8998/batches
{"id":2,"state":"starting","log":[]}As always, we can check its status with a simple GET:
curl localhost:8998/batches/2 | python -m json.tool
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 616 0 616 0 0 77552 0 -:-:- -:-:- -:-:- 88000
{
"id": 2,
"log": [
"\t ApplicationMaster host: 192.168.1.30",
"\t ApplicationMaster RPC port: 0",
"\t queue: root.romain",
"\t start time: 1445417899564",
"\t final status: UNDEFINED",
"\t tracking URL: http://unreal:8088/proxy/application_1444917524249_0006/",
"\t user: romain",
"15/10/21 01:58:26 INFO yarn.Client: Application report for application_1444917524249_0006 (state: RUNNING)",
"15/10/21 01:58:27 INFO yarn.Client: Application report for application_1444917524249_0006 (state: RUNNING)",
"15/10/21 01:58:28 INFO yarn.Client: Application report for application_1444917524249_0006 (state: RUNNING)"
],
"state": "running"
}
And the output by adding the /log suffix!
curl localhost:8998/batches/2/log | python -m json.toolSubmitting a Streaming job
In many cases, Streaming consist in a batch job that we submit. Here is how to submit the Solr Spark streaming jobs that collects live tweets and index them into a Dynamic Search Dashboard.
After we compiling the jar, we upload it on HDFS, and also upload the twitter4j.properties.
curl -X POST -data '{"file": "/user/romain/spark-solr-1.0-SNAPSHOT.jar", "className": "com.lucidworks.spark.SparkApp", "args": ["twitter-to-solr", "-zkHost", "localhost:9983", "-collection", "tweets"], "files": ["/user/romain/twitter4j.properties"]}' -H "Content-Type: application/json" localhost:8998/batches
{"id":3,"state":"starting","log":[]}
We check the status and see that it is running correctly:
curl localhost:8998/batches/3 | python -m json.tool
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 842 0 842 0 0 82947 0 -:-:- -:-:- -:-:- 84200
{
"id": 3,
"log": [
"\t start time: 1445420201439",
"\t final status: UNDEFINED",
"\t tracking URL: http://unreal:8088/proxy/application_1444917524249_0009/",
"\t user: romain",
"15/10/21 02:36:47 INFO yarn.Client: Application report for application_1444917524249_0009 (state: RUNNING)",
"15/10/21 02:36:48 INFO yarn.Client: Application report for application_1444917524249_0009 (state: RUNNING)",
"15/10/21 02:36:49 INFO yarn.Client: Application report for application_1444917524249_0009 (state: RUNNING)",
"15/10/21 02:36:50 INFO yarn.Client: Application report for application_1444917524249_0009 (state: RUNNING)",
"15/10/21 02:36:51 INFO yarn.Client: Application report for application_1444917524249_0009 (state: RUNNING)",
"15/10/21 02:36:52 INFO yarn.Client: Application report for application_1444917524249_0009 (state: RUNNING)"
],
"state": "running"
}
If we open the Dashboard and configure it like in the blog post, we can see the tweets coming:

At the end, we can just stop the job with:
curl -X DELETE localhost:8998/batches/3
You can refer to the Batch API documentation for how to specify additional spark-submit properties. For example to add a custom name or queue:
curl -X POST -data '{"file": "/usr/lib/spark/lib/spark-examples.jar", "className": "org.apache.spark.examples.SparkPi", "queue": "my_queue", "name": "Livy Pi Example"}' -H "Content-Type: application/json" localhost:8998/batchesNext time we will explore magic keywords and how to integrate better with IPython!
If you want to learn more about the Livy Spark REST Api, feel free to send questions on the user list or meet up in person at the upcoming Spark Summit in Amsterdam!