Livy is an open source REST interface for interacting with Apache Spark from anywhere. It supports executing snippets of Python, Scala, R code or programs in a Spark Context that runs locally or in YARN.
In the episode 1 we previously detailed how to use the interactive Shell API.
In this follow-up, lets put the API in practice for a more concrete example: let's simulate sharing RDDs or contexts!
Starting the REST server
This is described in the previous post section.
Sharing Spark contexts…
Livy offers remote Spark sessions to users. They usually have one each (or one by Notebook):
# Client 1
curl localhost:8998/sessions/0/statements -X POST -H 'Content-Type: application/json' -d '{"code":"1 + 1"}'
\# Client 2
curl localhost:8998/sessions/1/statements -X POST -H 'Content-Type: application/json' -d '{"code":"..."}'
\# Client 3
curl localhost:8998/sessions/2/statements -X POST -H 'Content-Type: application/json' -d '{"code":"..."}'
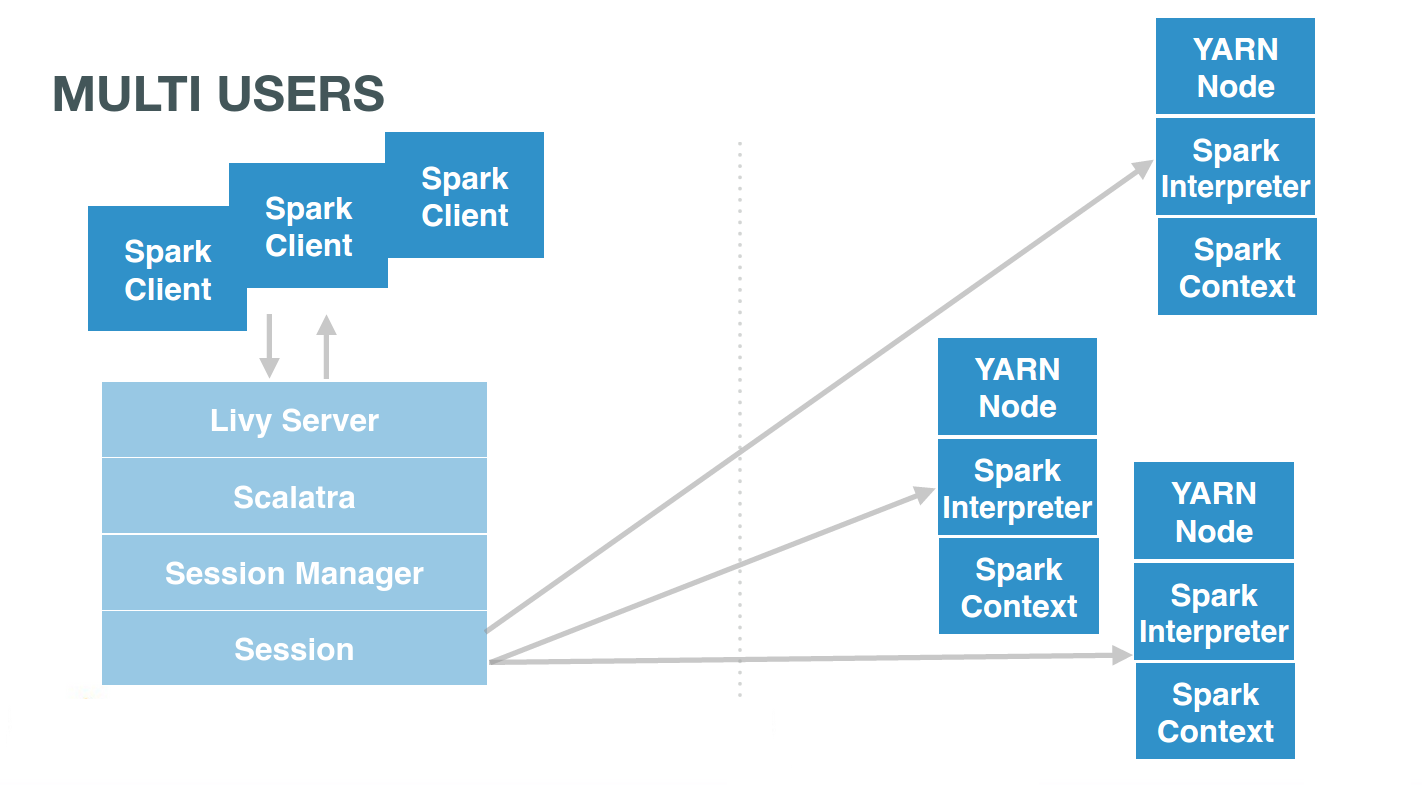
… and so sharing RDDs
If the users were pointing to the same session, they would interact with the same Spark context. This context would itself manages several RDDs. Users simply need to use the same session id, e.g. 0, and issue commands there:
# Client 1
curl localhost:8998/sessions/0/statements -X POST -H 'Content-Type: application/json' -d '{"code":"1  + 1"}'
\# Client 2
curl localhost:8998/sessions/0/statements -X POST -H 'Content-Type: application/json' -d '{"code":"..."}'
\# Client 3
curl localhost:8998/sessions/0/statements -X POST -H 'Content-Type: application/json' -d '{"code":"..."}'
+ 1"}'
\# Client 2
curl localhost:8998/sessions/0/statements -X POST -H 'Content-Type: application/json' -d '{"code":"..."}'
\# Client 3
curl localhost:8998/sessions/0/statements -X POST -H 'Content-Type: application/json' -d '{"code":"..."}' 
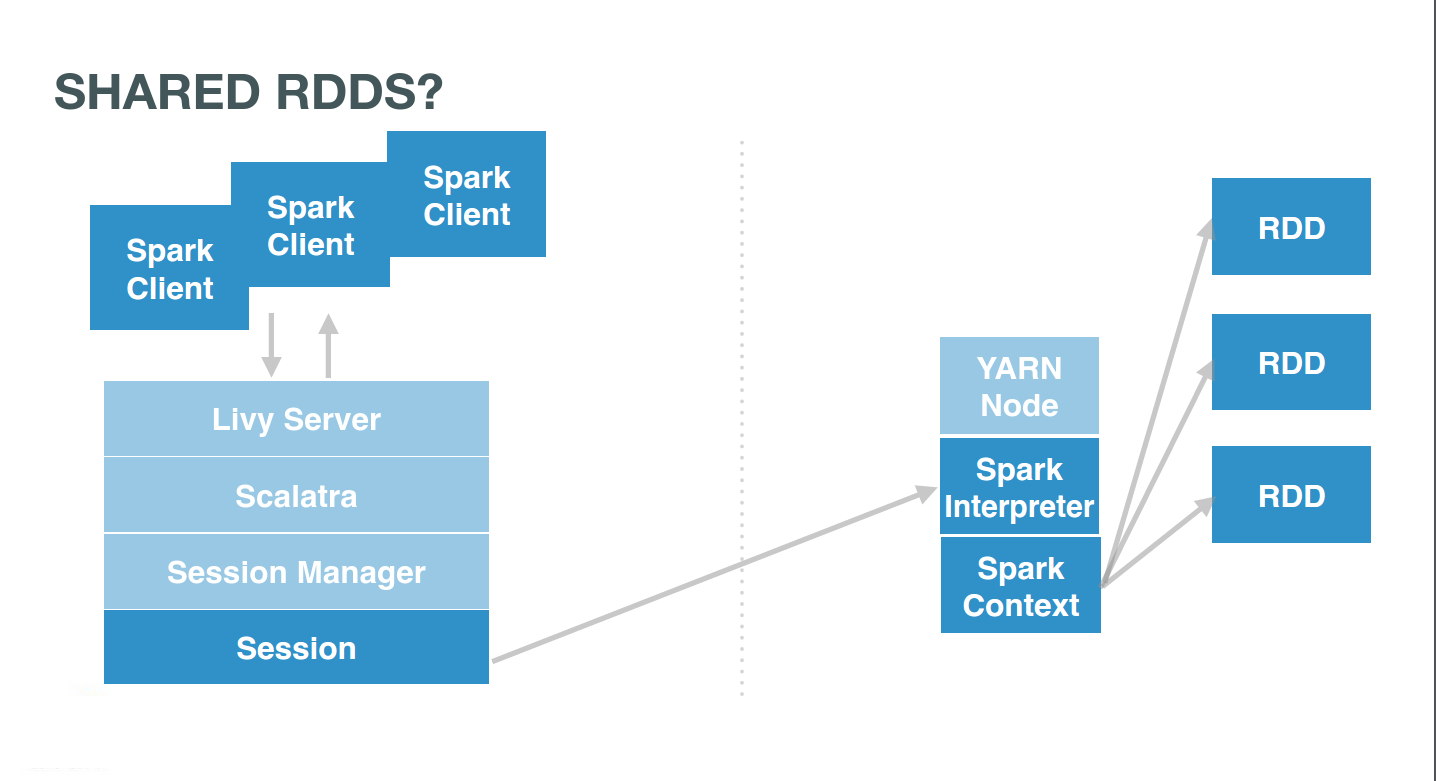
… Accessing them from anywhere
Now we can even make it more sophisticated while keeping it simple. Imagine we want to simulate a shared in memory key/value store. One user can start a named RDD on a remote Livy PySpark session and anybody could access it.
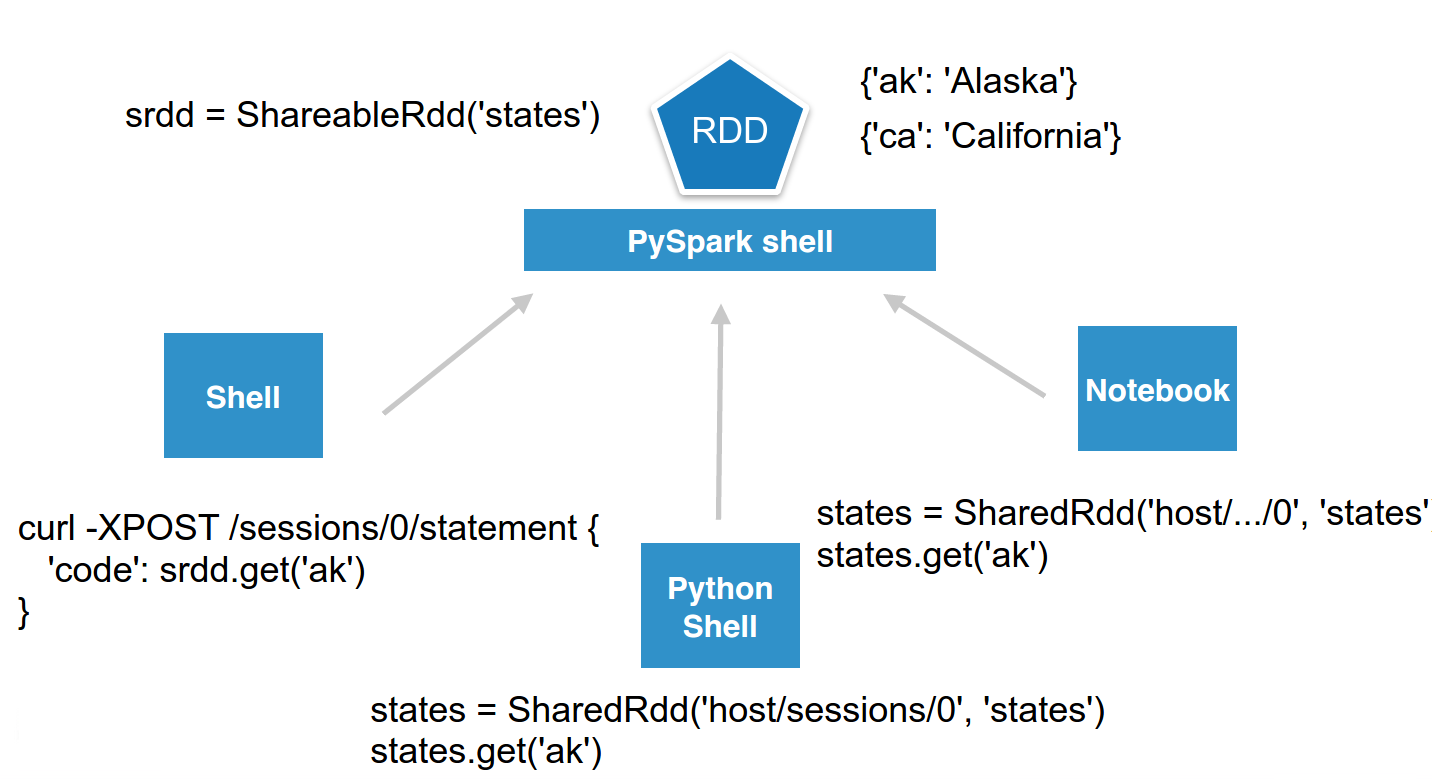
To make it prettier, we can wrap it in a few lines of Python and call it ShareableRdd. Then users can directly connect to the session and set or retrieve values.
class ShareableRdd():
def __init__(self):
self.data = sc.parallelize([])
def get(self, key):
return self.data.filter(lambda row: row[0] == key).take(1)
def set(self, key, value):
new_key = sc.parallelize([[key, value]])
self.data = self.data.union(new_key)
set() adds a value to the shared RDD, while get() retrieves it.
srdd = ShareableRdd()
srdd.set('ak', 'Alaska')
srdd.set('ca', 'California')
srdd.get('ak')
If using the REST Api directly someone can access it with just these commands:
curl localhost:8998/sessions/0/statements -X POST -H 'Content-Type: application/json' -d '{"code":"srdd.get(\"ak\")"}'
{"id":3,"state":"running","output":null}curl localhost:8998/sessions/0/statements/3
{"id":3,"state":"available","output":{"status":"ok","execution_count":3,"data":{"text/plain":"[['ak', 'Alaska']]"}}}We can even get prettier data back, directly in json format by adding the %json magic keyword:
curl localhost:8998/sessions/0/statements -X POST -H 'Content-Type: application/json' -d '{"code":"data = srdd.get(\"ak\")\n%json data"}'
{"id":4,"state":"running","output":null}curl localhost:8998/sessions/0/statements/4
{"id":4,"state":"available","output":{"status":"ok","execution_count":2,"data":{"application/json":[["ak","Alaska"]]}}}Note
Support for %json srdd.get("ak") is on the way!
Even from any languages
As Livy is providing a simple REST Api, we can quickly implement a little wrapper around it to offer the shared RDD functionality in any languages. Let's do it with regular Python:
pip install requests
pythonThen in the Python shell just declare the wrapper:
import requests
import json
class SharedRdd():
"""
Perform REST calls to a remote PySpark shell containing a Shared named RDD.
"""
def __init__(self, session_url, name):
self.session_url = session_url
self.name = name
def get(self, key):
return self._curl('%(rdd)s.get("%(key)s")' % {'rdd': self.name, 'key': key})
def set(self, key, value):
return self._curl('%(rdd)s.set("%(key)s", "%(value)s")' % {'rdd': self.name, 'key': key, 'value': value})
def _curl(self, code):
statements_url = self.session_url + '/statements'
data = {'code': code}
r = requests.post(statements_url, data=json.dumps(data), headers={'Content-Type': 'application/json'})
resp = r.json()
statement_id = str(resp['id'])
while resp['state'] == 'running':
r = requests.get(statements_url + '/' + statement_id)
resp = r.json()
return r.json()['data']
Instantiate it and make it point to a live session that contains a ShareableRdd:
states = SharedRdd('http://localhost:8998/sessions/0', 'states')
And just interact with the RDD transparently:
states.get('ak')
states.set('hi', 'Hawaii')
And that's it! This shared RDD example is a good demo of the capabilities of the REST Api and does claim any production support for Shared RDDs. The shared RDD could also supporting loading, saving… and being discovered through a RDD listing API.
All the code sample is available on github and will work with the very latest version of Livy.
If you want to learn more about the Livy Spark REST Api, feel free to send questions on the user list or meet up in person at the upcoming Spark Summit in Amsterdam!