Note: This post is deprecated as of Hue 3.8 / April 24th 2015. Hue now has a new Spark Notebook application.
Hue ships with Spark Application that lets you submit Scala and Java Spark jobs directly from your Web browser.
The open source Spark Job Server is used for communicating with Spark (e.g. for listing, submitting Spark jobs, retrieving the results, creating contexts…).
Here are more details about how to run the Spark Job server as a service. This is better suited for production, to the contrary of the development mode detailed in the previous post. We are using CDH5.0 and Spark 0.9.
Package and Deploy the server
Most of the instructions are on the github.
We start by checking out the repository and building the project (note: if you are on Ubuntu and encrypted your disk, you will need to build from /tmp). Then, from the Spark Job Server root directory:
mkdir bin/config
cp config/local.sh.template bin/config/settings.sh
And these two variables in settings.sh:
LOG_DIR=/var/log/job-server
SPARK_HOME=/usr/lib/spark (or SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark)
Then package everything:
bin/server_deploy.sh settings.sh
[info] - should return error message if classPath does not match
[info] - should error out if loading garbage jar
[info] - should error out if job validation fails
...
[info] Packaging /tmp/spark-jobserver/job-server/target/spark-job-server.jar ...
[info] Done packaging.
[success] Total time: 149 s, completed Jun 2, 2014 5:15:14 PM
/tmp/job-server /tmp/spark-jobserver
log4j-server.properties
server_start.sh
spark-job-server.jar
/tmp/spark-jobserver
Created distribution at /tmp/job-server/job-server.tar.gz
We have our main tarball /tmp/job-server/job-server.tar.gz, ready to be copied on a server.
Note:
You could also automatically copy the files with server_deploy.sh.
Start the Spark Job Server
We then extract job-server.tar.gz and copy our application.conf on the server. Make sure than ‘master’ points to the correct Spark Master URL.
scp /tmp/spark-jobserver/./job-server/src/main/resources/application.conf hue@server.com:
Edit application.conf to point to the master:
# Settings for safe local mode development
spark {
master = "spark://spark-host:7077"
…
}
Here is the content of our jobserver folder:
ls -l
total 25208
-rw-rw-r- 1 ubuntu ubuntu 2015 Jun 9 23:05 demo.conf
-rw-rw-r- 1 ubuntu ubuntu 2563 Jun 11 16:32 gc.out
-rw-rw-r- 1 ubuntu ubuntu 588 Jun 9 23:05 log4j-server.properties
-rwxrwxr-x 1 ubuntu ubuntu 2020 Jun 9 23:05 server_start.sh
-rw-rw-r- 1 ubuntu ubuntu 366 Jun 9 23:13 settings.sh
-rw-rw-r- 1 ubuntu ubuntu 13673788 Jun 9 23:05 spark-job-server.jar
Note:
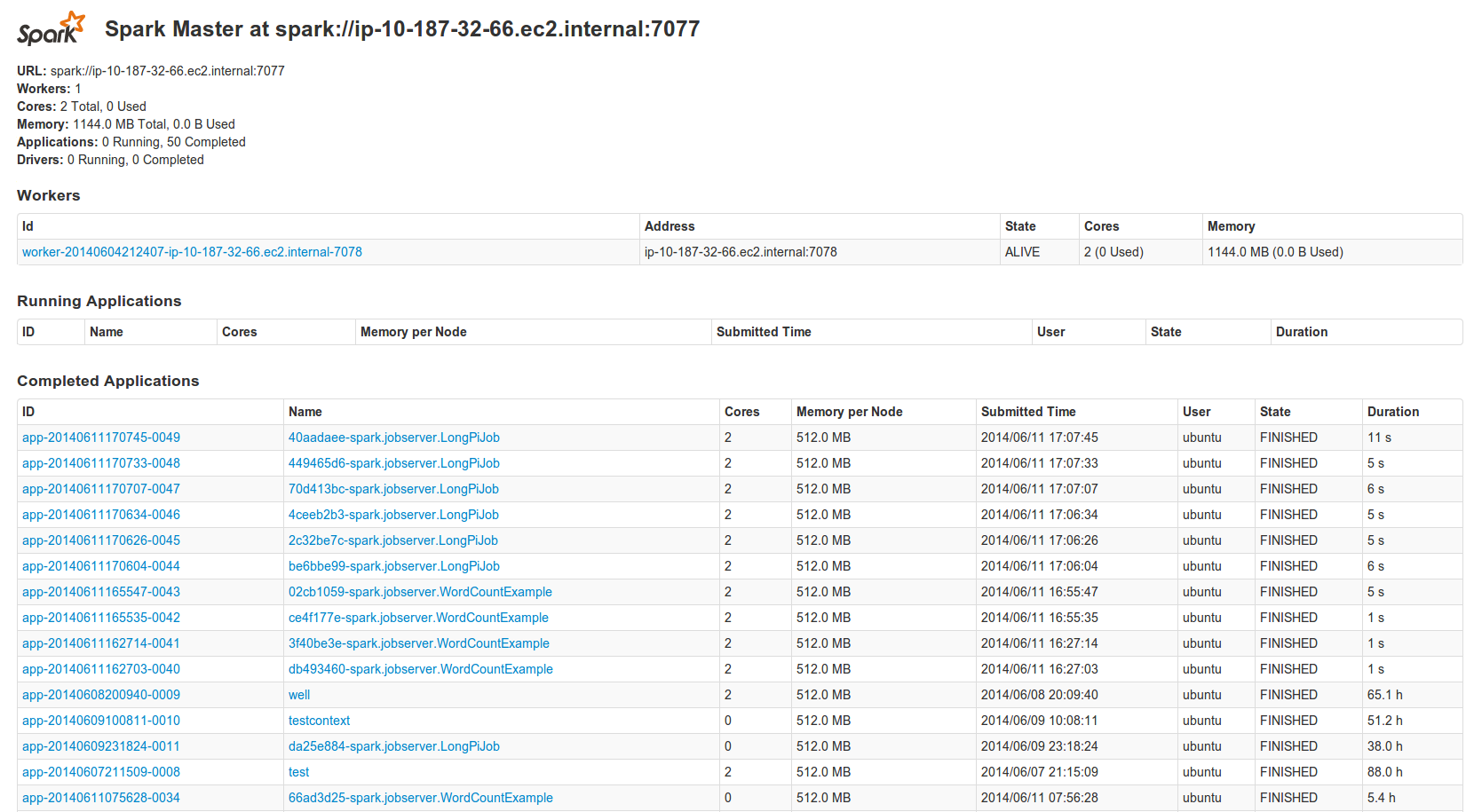
You can get the spark URL by looking at it on the Spark Master Web UI.
Also make sure that you see at least one Spark work: "Workers: 1"
In the past, we had some problems (e.g. spark worker not starting) when trying to bind Spark to a localhost. We fixed it by hardcoding in the spark-env.sh:
sudo vim /etc/spark/conf/spark-env.sh
export STANDALONE_SPARK_MASTER_HOST=spark-host
Now just start the server and the process will run in the background:
./server_start.shYou can check if it is alive by grepping it:
ps -ef | grep 9999
ubuntu 28755 1 2 01:41 pts/0 00:00:11 java -cp /home/ubuntu/spark-server:/home/ubuntu/spark-server/spark-job-server.jar::/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/spark/conf:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/spark/assembly/lib/\*:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/spark/examples/lib/\*:/etc/hadoop/conf:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/hadoop/\*:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/hadoop/../hadoop-hdfs/\*:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/hadoop/../hadoop-yarn/\*:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/hadoop/../hadoop-mapreduce/\*:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/spark/lib/scala-library.jar:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/spark/lib/scala-compiler.jar:/opt/cloudera/parcels/CDH-5.0.0-1.cdh5.0.0.p0.47/lib/spark/lib/jline.jar -XX:+UseConcMarkSweepGC -verbose:gc -XX:+PrintGCTimeStamps -Xloggc:/home/ubuntu/spark-server/gc.out -XX:MaxPermSize=512m -XX:+CMSClassUnloadingEnabled -Xmx5g -XX:MaxDirectMemorySize=512M -XX:+HeapDumpOnOutOfMemoryError -Djava.net.preferIPv4Stack=true -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.manage
That’s it!
Run the Pi example!
The Spark Job Server comes with a few examples that you can build with one command. Let’s run the Pi job.
We open up the Spark App on http://hue:8888/spark, go to the the application tab and upload the job-server-tests-0.3.x.jar.
Now in the editor, specify the class to run, here spark.jobserver.LongPiJob and execute it!
You will see the Spark Application running on the Spark Master UI too. If you want to get a long running application, create a context, then assign this context to the application in the editor.
Sum-up
This is how we setup the Spark Server on demo.gethue.com/spark. As usual, feel free to comment on the hue-user list or @gethue!
Happy Sparking!
PS: we hope to see you in person at the Hue or Job Server talks at the upcoming Spark Summit!