Creating Solr Collections from Data files in a few clicks
There are exciting new features coming in Hue 3.11 week and later in CDH 5.9 this Fall. One of which is Hue’s brand new tool to create Apache Solr Collections from file data. Hue’s Solr dashboards are great for visualizing and learning more about your data so being able to easily load data into Solr collections can be really useful.
In the past, indexing data into Solr has been quite difficult. The task involved writing a Solr schema and a morphlines file then submitting a job to YARN to do the indexing. Often times getting this correct for non trivial imports could take a few days of work. Now with Hue’s new feature you can start your YARN indexing job in minutes. This tutorial offers a step by step guide on how to do it.
Tutorial
What you’ll need
First you'll need to have a running Solr cluster that Hue is configured with.
Next you'll need to install these required libraries. To do so place them in a directory somewhere on HDFS and set the path for _config_indexer_libs_path_ under indexer in the Hue ini to match by default, the _config_indexer_libs_path_ value is set to _/tmp/smart_indexer_lib_. Additionally under indexer in the Hue ini you’ll need to set _enable_new_indexer _to true.
[indexer]
\# Flag to turn on the morphline based Solr indexer.
enable_new_indexer=false
\# Oozie workspace template for indexing.
\## config_indexer_libs_path=/tmp/smart_indexer_lib
Note:
If using Cloudera Manager, check how to add properties in Hue.ini safety valve and put the abov
Selecting data
We are going to create a new Solr collection from business review data. To start let’s put the data file somewhere on HDFS so we can access it.
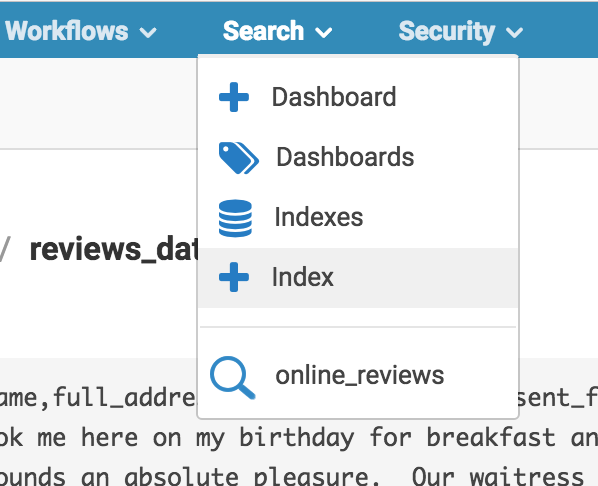
Now we can get started! Under the search tab in the navbar select Index.
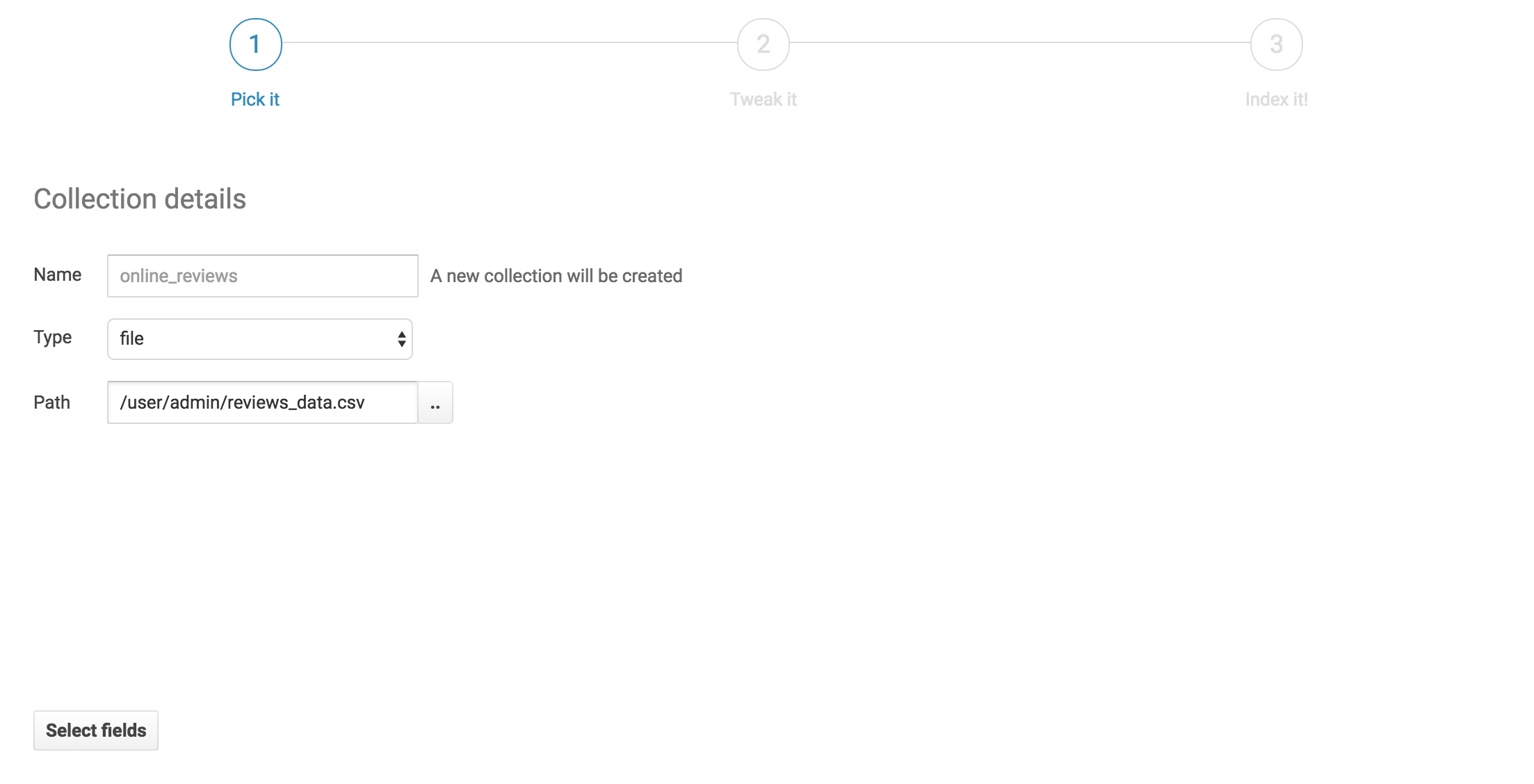
We'll pick a name for our new collection and select our reviews data file from HDFS. Then we'll click next.
Field selection and ETL
On this tab we can see all the fields the indexer has picked up from the file. Note that Hue has also made an educated guess on the field type. Generally, Hue does a good job inferring data type. However, we should do a quick check to confirm that the field types look correct.
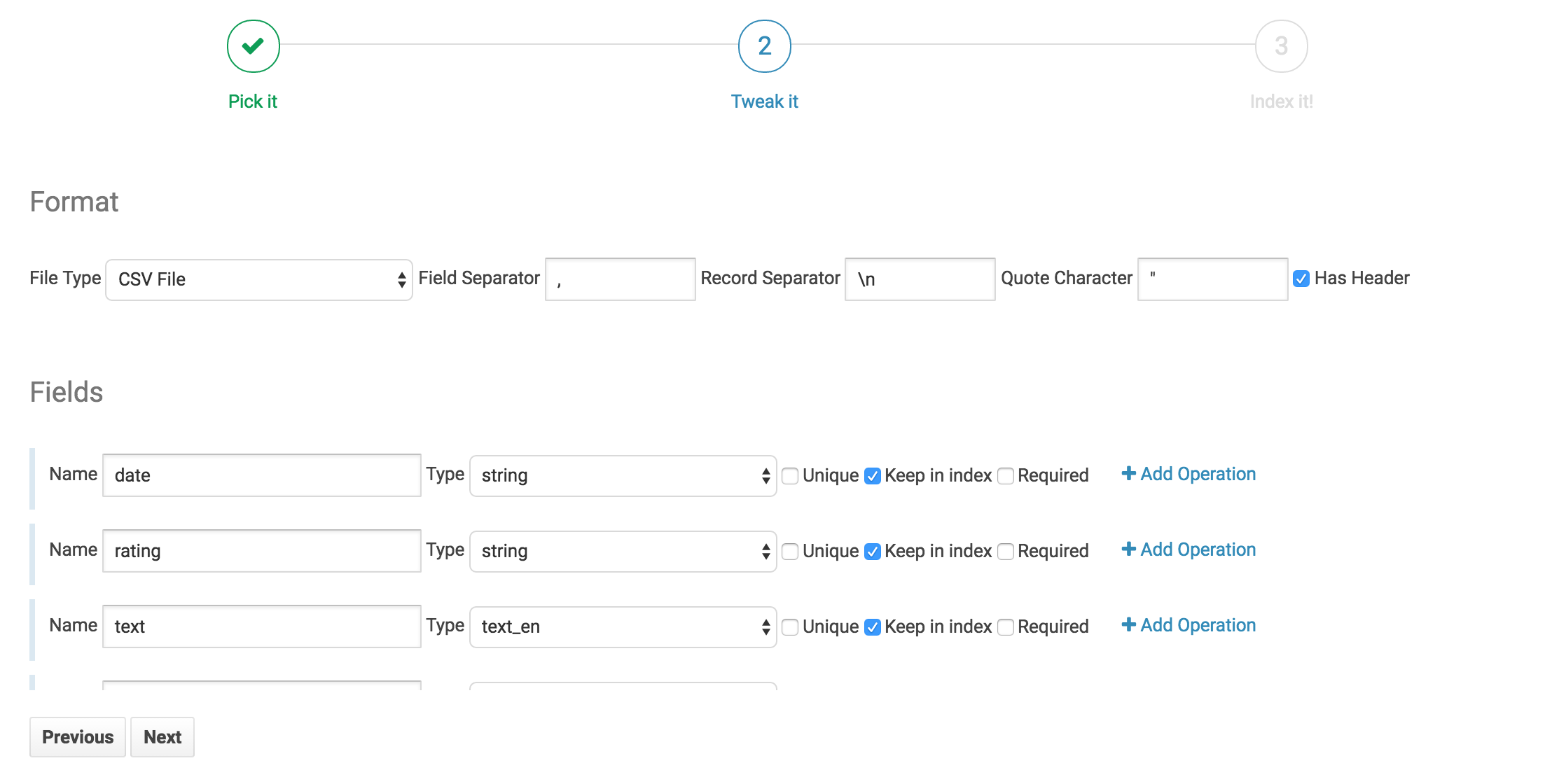
For our data we're going to perform 4 operations to make a very searchable Solr Collection.
-
Convert Date
This operation is implicit. By setting the field type to date we inform Hue that we want to convert this date to a Solr Date. Hue can convert most standard date formats automatically. If we had a unique date format we would have to define it for Hue by explicitly using the convert date operation.


-
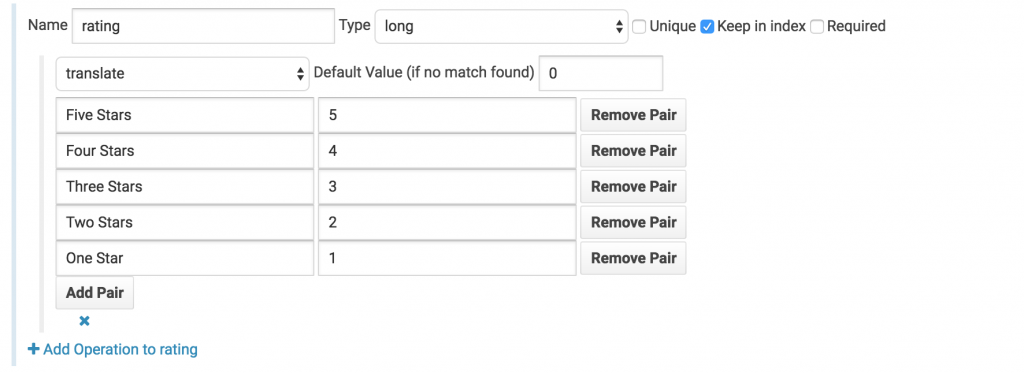
Translate star ratings to integer ratings
Under the rating field we’ll change the field type from string to long and click add operation. We’ll then select the translate operation and setup the following translation mapping.
-
Grok the city from the full address field
We’ll add a grok operation to the full address field, fill in the following regex .* (?\w+),.* and set the number of expected fields to 1. In the new child field we’ll set the name to city. This new field will now contain the value matching the city capture group in the regex.


-
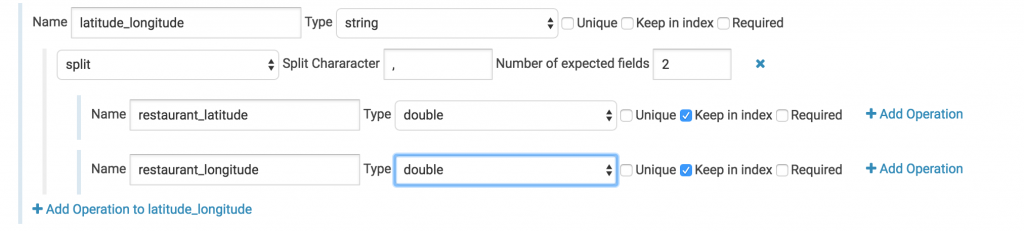
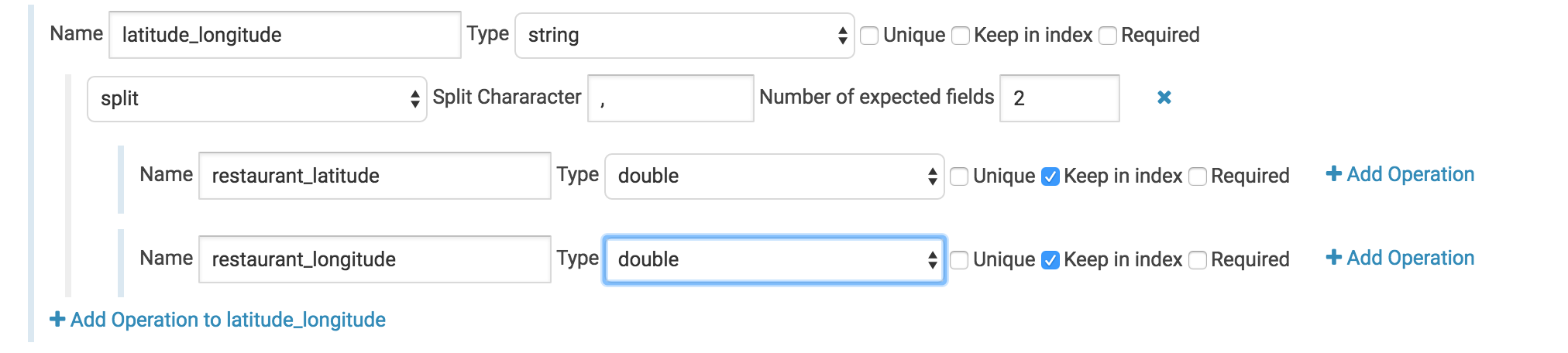
Use a split operation to separate the latitude/longitude field into two separate floating point fields.
Here we have an annoyance. Our data file contains the latitude and longitude of the place that’s being reviewed - Awesome! For some reason though they’ve been clumped into one field with a comma between the two numbers. We’ll use a split operation to grab each individually. Set the split value to ‘,’ and the number of output fields to 2. Then change the child fields’ types to doubles and give them logical names. In this case there’s not really much sense in keeping the parent field so let’s uncheck the “keep in index” box.
-
perform a GeoIP to find where the user was when they submitted the review
Here we’ll add a geo ip operation and select iso_code as our output. This will give us the country code.


Indexing
Before we index, let’s make sure everything looks good with a quick scan of the preview. This can be handy to avoid any silly typos or anything like that.
Now that we've defined our ETL Hue can do the rest. Click index and wait for Hue to index our data. At the bottom of this screen we can see a progress bar of the process. Yellow means our data is currently being indexed and green means it's done. Feel free to close this window. The indexing will continue on your cluster.
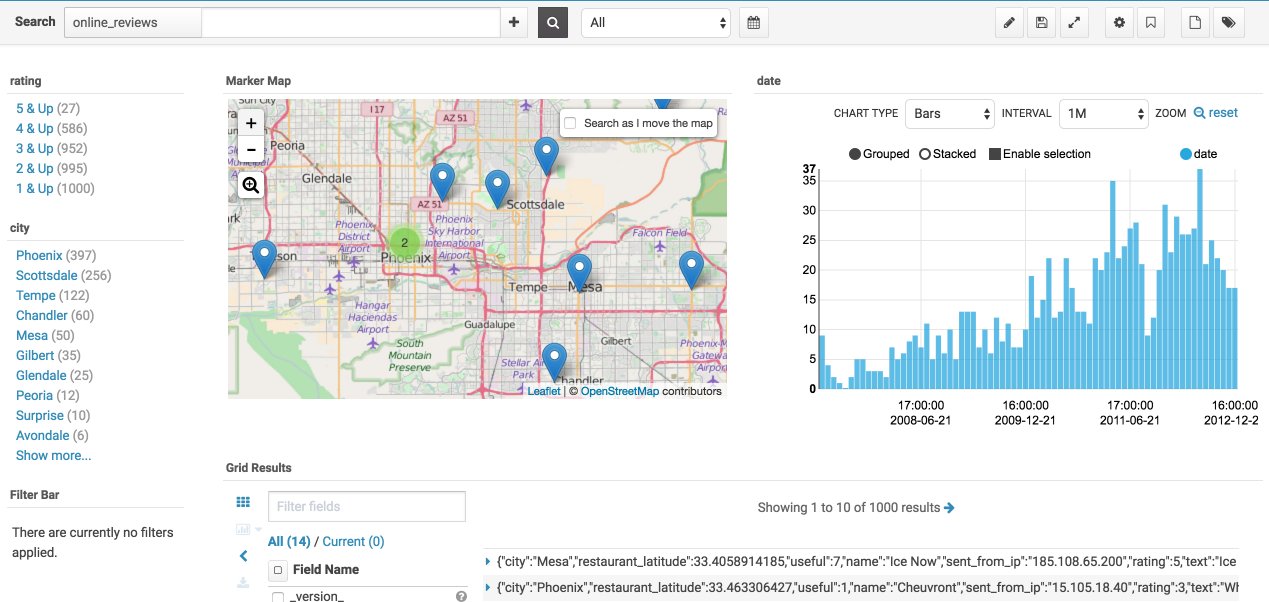
Once our data has been indexed into a Solr Collection we have access to all of Hue's search features and can make a nice analytics dashboard like this one for our data.
Documentation
Assembling the lib directory yourself
The indexer libs path is where all required libraries for indexing should be. If you’d prefer you can assemble this directory yourself. There are three main components to the libs directory:
- JAR files required by the MapReduceIndexerTool
- All required jar files should have shipped with CDH. Currently the list of required JARs is:
- argparse4j-0.4.3.jar
- readme.txt
- httpmime-4.2.5.jar
- search-mr-1.0.0-cdh5.8.0-job.jar
- kite-morphlines-core-1.0.0-cdh5.8.0.jar
- solr-core-4.10.3-cdh5.8.0.jar
- kite-morphlines-solr-core-1.0.0-cdh5.8.0.jar
- solr-solrj-4.10.3-cdh5.8.0.jar
- noggit-0.5.jar
- Should this change and you get a missing class error, you can find whatever jar may be missing by grepping all the jars packaged with CDH for the missing class.
- Maxmind GeoLite2 database
- This file is required for the GeoIP lookup command and can be found on MaxMind’s website
- Grok Dictionaries
- Any grok commands can be defined in text files within the grok_dictionaries sub directory. A good starter set of grok dictionaries can be found here.
Operations
On top of the ease of use, this is where the real power of Hue's new indexer lies. Heavily leveraging Morphlines, operations let us easily transform our data into a more searchable format. Before we add some to our fields let's quickly go over the operations that the indexer offers.
Operation list:
- With the split operation we can take a field and produce new fields by splitting the original field on a delimiting character
-
Input: “2.1,-3.5,7.1”
Split Character: “,” -
Outputs 3 fields:
Field 1: “2.1”
Field 2: “-3.5”
Field 3: “7.1”
- Grok is an extension of Regex and can be used to match specific subsections of a field and pull them out. You can read more about the Grok syntax here
-
Input: “Winnipeg (Canada)”
Regular Expression: “\w+ \((?\w+)\)” -
Outputs 1 field:
country: “Canada”
- Generally the indexer converts dates automatically to Solr's native format. However, if you have a very obscure date format you can define it using a SimpleDateFormat here to ensure it is converted correctly
-
Input: “Aug (2016) 24”
Date Format: “MMM (YYYY) dd” - Output: In place replacement: “2016-08-24T00:00:00Z”
- Extract URI Components lets you grab specific parts of a URI and put it in its own field without having to write the Regex yourself.
-
The following components can be extracted:
- Authority
- Fragment
- Host
- Path
- Port
- Query
- Scheme
- Scheme Specific Path
- User Info
<li style="font-weight: 400;">
<span style="font-weight: 400;">Input: “</span><a href="https://www.google.com/#q=cloudera+hue"><span style="font-weight: 400;">https://www.google.com/#q=cloudera+hue</span></a><span style="font-weight: 400;">”</span><span style="font-weight: 400;"><br /> </span><span style="font-weight: 400;">Selected: Host</span>
</li>
<li style="font-weight: 400;">
<span style="font-weight: 400;"><span style="font-weight: 400;">Output: “www.google.com”</span></span>
</li>
- Geo IP performs a Maxmind GeoIP lookup to match public IP addresses with a location.
-
The following location information can be extracted with this operation:
- ISO Code
- Country Name
- Subdivision Names
- Subdivision ISO Code
- City Name
- Postal Code
- Latitude
- Longitude
<li style="font-weight: 400;">
<span style="font-weight: 400;">Input: “74.217.76.101”</span><span style="font-weight: 400;"><br /> </span><span style="font-weight: 400;">Selected: ISO Code, City Name, Latitude, Longitude</span>
</li>
<li style="font-weight: 400;">
<span style="font-weight: 400;"><span style="font-weight: 400;">Output: “US”, “Palo Alto”, “37.3762”, “-122.1826”</span></span>
</li>
- Translate will take given hard coded values and replace them with set values in place.
-
Input: “Five Stars”
Mapping:
“Five Stars” -> “5”
“Four Stars” -> “4”
“Three Stars” -> “3”
“Two Stars” -> “2”
“One Star” -> “1” - Output: In place Replacement: “5”
- Find and Replace takes a Grok string as the find argument and will replace all matches in the field with the specified replace value in place.
-
Input: “Hello World”
Find: “(?\b\w+\b)”
Replace: “"${word}!" - Output: In place replacement: “Hello! World!”
Supported Input Data
Hue successfully recognized our file as a CSV. The indexer currently supports the following file types:
- CSV Files
- Hue Log Files
- Combined Apache Log Files
- Ruby Log File
- Syslog
Beyond files, metastore tables and Hive SQL queries are also supported. Read more about these in an upcoming 3.11 blog post.
Troubleshooting**
**
During the indexing process records can be dropped if they fail to match the Solr Schema. (e.g., trying to place a string into a long field). If some of your records are missing and you are unsure why you can always check the mapper log for the indexing job to get a better idea on what’s going on.****